

Что такое размер кластера
Размер кластера (единицы распределения) – другими словами, минимальный размер блоков на жестком диске или другом носителе информации, необходимый для хранения файлов.
Применительно к большинству HDD/SSD и пользовательских задач, можно оставить стандартную настройку, предлагаемую ОС – то есть, 4096 байт. Этот размер кластера является штатным в Windows практически для всех дисков, чей размер не превышает 16 Тб.
Почему стандарт 4 КБ?
Для многих накопителей, в особенности твердотельных, значения производительности, к примеру записи, начиная с 4 КБ, становятся оптимальными, это видно из графика:

В то время, как на чтение, скорость также довольно существенна и более менее сносна начиная с 4 КБ:

Именно по этой причине 4 КБ размер блока очень часто применяют за стандартный, так как при меньшем размере идут большие потери производительности, а при увеличении размера блока, в случае работы с небольшими данными, данные будут распределены менее эффективно, занимать весь размер блока и квота накопителя будет использоваться не эффективно.
Общие советы
Вкратце, чем меньшего размера файлы будут храниться на диске, тем меньше нужно задавать размер кластера. Благодаря этому, вы сможете немного повысить производительность жесткого диска или SSD за счет того, что большее количество блоков будет задействовано.
Соответственно, если у вас много крупных файлов (видео, loseless музыка и прочее), можете задать больший размер кластера. Таким образом, пространство диска будет использоваться более экономно.
При чтении / записи больших файлов производительность увеличится, при этом КПД диска немного упадет.
Подводные камни. Специализированный софт и системные утилиты (сканирование диска, дефрагментация) могут испытывать затруднения при использовании нестандартных размеров кластера – учитывайте это.
При расчете производительности жесткого диска можно пренебречь снижением количества IOPS при увеличении размера блока, почему?
Мы уже поняли, что для «вращающихся» накопителей, время, требуемое для случайного чтения или записи, складывается из следующих компонент:
T(I/O) = T(A)+T(L)+T(R/W).
И далее даже рассчитали производительность при случайном чтении и записи в IOPS. Вот только параметром T(R/W) мы там по сути пренебрегли, и это не случайно. Мы знаем, что допустим, последовательное чтение может быть обеспечено на скорости в 120 мегабайт в секунду. Становится понятным, что блок в 4КБ, будет считан за примерно 0,03 мс, время на два порядка меньшее, нежели время остальных задержек (8 мс + 4 мс).
Таким образом, если при размере блока в 4КБ мы имеем 76 IOPS (основная задержка была вызвана вращением накопителя и временем позиционирования головки, а не самим процессом чтения или записи), то при размере блока в 64КБ, падение IOPS будет не в 16 раз, как при последовательном чтении, а лишь на несколько IOPS. Так как время, затрачиваемое на непосредственно чтение или запись, возрастет на 0,45 мс, что составляет лишь порядка 4% от общего времени задержки.
В результате мы получим 76-4% = 72,96 IOPS, что согласитесь, совсем не критично при расчетах, так как падение IOPS не в 16 раз, а лишь на несколько процентов! И при расчетах производительности систем куда важнее не забыть учесть другие важные параметры.
Волшебный вывод: при расчете производительности систем хранения, основанных на жестких дисках, следует подбирать оптимальный размер блока (кластера), для обеспечения нужной нам максимальной пропускной способности в зависимости от типа данных и используемых приложений, причем падением IOPS при увеличении размера блока с 4КБ до 64КБ или даже 128КБ можно пренебречь, либо учитывать, как 4 и 7% соответсвенно, если в поставленной задаче они будут играть важную роль.
Также становится понятным, почему не всегда есть смысл использовать очень большие блоки. Скажем, при видеостриминге, двухмегабайтный размер блока может оказаться далеко не самым оптимальным вариантом. Так как падение количества IOPS будет более, чем в 2 раза. Помимо прочего добавятся другие деградационные процессы в массивах, связанные с многопоточностью и вычислительной нагрузкой при распределении данных по массиву.
Команда LABEL используется для просмотра, изменения и удаления меток томов в командной строке Windows. Метка тома — это текстовый идентификатор, который может быть присвоен логическому тому, и обычно используется как дополнительное средство идентификации томов в системе. Длина метки не должна превышать 11 символов для файловых систем FAT32 и 32 символов для NTFS. В качестве символов поля метки для файловых систем FAT32 могут использоваться только буквы, цифры и пробел.
Формат командной строки:
Параметры командной строки:
диск: – Определяет букву диска.
метка – Определяет метку тома.
/MP – Определяет точку подключения тома, или имя тома.
том – Определяет букву диска (с последующим двоеточием), точку подключения или имя тома. Если указано имя тома, флаг /MP необязателен.
label /? – отобразить справку по использованию команды.
label – редактировать метку текущего диска.
label D: – редактировать метку диска D:
label C: Dick_C- установить метку «Disk_C» для логического диска C:
label C: “Disk C” – то же, что и в предыдущем примере, но текст метки содержит пробел, и поэтому заключен в двойные кавычки.
label /MP C:mounted1 REOVERY – создать метку “RECOVERY” для точки монтирования C:mounted1. Точка монтирования тома в пустой каталог NTFS может быть создана командой MOUNTVOL или оснасткой «Управление дисками» панели управления Windows.
При редактировании метки, программа отображает информацию о ее наличии и значении:
Том в устройстве C: имеет метку Disk_C
Серийный номер тома: 1CA9-44FE
Метка тома (32 символа, ENTER – метка не нужна):
Если существующая метка тома удаляется, то требуется подтверждение запроса на удаление:
Весь список команд CMD Windows
Оптимальный размер блока (кластера)
Оптимальный размер блока нужно учитывать в зависимости от характера нагрузки и типа используемых приложений. Если идет работа с данными небольшого размера, к примеру с базами данных — следует выбрать стандартные 4 КБ, если же речь идет о стриминге видеофайлов — размер кластера лучше выбирать от 64 КБ и более.
Следует помнить, что размер блока не столь критичен для SSD, сколько для стандартных HDD, так как позволяет обеспечить нужную пропускную способность в виду небольшого количества случайных IOPS, количество которых снижается незначительно при увеличении размера блока, в отличии от SSD, где наблюдается практически пропорциональная зависимость.
Какие факторы влияют на производительность систем хранения и как?
Время на прочтение
Системы хранения данных для подавляющего большинства веб-проектов (и не только) играют ключевую роль. Ведь зачастую задача сводится не только к хранению определенного типа контента, но и к обеспечению его отдачи посетителям, а также обработки, что накладывает определенные требования к производительности.
В то время, как при производстве накопителей используется множество других метрик, чтоб описать и гарантировать должную производительность, на рынке систем хранения и дисковых накопителей, принято использовать IOPS, как сравнительную метрику, с целью «удобства» сравнения. Однако производительность систем хранения, измеряемая в IOPS (Input Output Operations per Second), операциях ввода / вывода (записи / чтения), подвержена влиянию большого множества факторов.
В этой статье я хотел бы рассмотреть эти факторы, чтобы сделать меру производительности, выраженную в IOPS, более понятной.
Начнем с того, что IOPS вовсе не IOPS и даже совсем не IOPS, так как существует множество переменных, которые определяют сколько IOPS мы получим в одних и других случаях. Также следует принять во внимание, что системы хранения используют функции чтения и записи и обеспечивают различное количество IOPS для этих функций в зависимости от архитектуры и типа приложения, в особенности в случаях, когда операции ввода / вывода происходят в одно и тоже время. Различные рабочие нагрузки предъявляют различные требования к операциям ввода / вывода (I/O). Таким образом, системы хранения, которые на первый взгляд должны были бы обеспечивать должную производительность, в действительности могут не справится с поставленной задачей.
Блоки и размер блока
Для внутреннего хранения файла файловая система разбивает хранилище на блоки. Традиционным размером блока были 512 байт, но более актуальное значение — 4 килобайта. Вообще же при выборе этого значения руководствуются поддерживаемым размером страницы на типовом оборудовании MMU (memory management unit, «устройство управления памятью» — прим. перев.).
Файловая система вставляет порезанный на части (chunks) файл в эти блоки и следит за ними в метаданных. В идеале всё выглядит так:


Это называется внешней фрагментацией (external fragmentation) и обычно приводит к падению производительности. Причина — вращающейся головке жёсткого диска приходится переходить с места на место, чтобы собрать все фрагменты, а это медленная операция. Решением данной проблемы занимаются классические инструменты дефрагментации.
Что происходит с файлами меньше 4 КБ? Что происходит с содержимым последнего блока после того, как файл был порезан на части? Естественным образом будет возникать неиспользуемое пространство — это называется внутренней фрагментацией (internal fragmentation). Очевидно, этот побочный эффект нежелателен и может привести к тому, что многое свободное пространство не будет использоваться, особенно если у нас большое количество очень маленьких файлов.
Итак, реальное использование диска файлом можно увидеть с помощью stat , ls -ls file.c или du file.c . Например, содержимое 1-байтового файла всё равно занимает 4 КБ дискового пространства:
Таким образом, мы смотрим на две величины: размер файла и использованные блоки. Мы привыкли думать в терминах первого, однако должны — в терминах последнего.
Журналирование
Возможности журналирования для ext2 появились в ext3. Журнал — циклический лог, записывающий обрабатываемые транзакции с целью улучшить устойчивость к сбоям питания. По умолчанию он применяется только к метаданным, однако можно его активировать и для данных с помощью опции data=journal , что повлияет на производительность.
Это специальный скрытый файл, обычно с номером inode 8 и размером 128 МБ, объяснение про который можно найти в официальной документации:
Журнал, представленный в файловой системе ext3, используется в ext4 для защиты ФС от повреждений в случае системных сбоев. Небольшой последовательный фрагмент диска (по умолчанию это 128 МБ) зарезервирован внутри ФС как место для сбрасывания «важных» операций записи на диск настолько быстро, насколько это возможно. Когда транзакция с важными данными полностью записана на диск и сброшена с кэша (disk write cache), запись о данных также записывается в журнал. Позже код журнала запишет транзакции в их конечные позиции на диске (операция может приводить к продолжительному поиску или большому числу операций чтения-удаления-стирания) перед тем, как запись об этих данных будет стёрта. В случае системного сбоя во время второй медленной операции записи журнал позволяет воспроизвести все операции вплоть до последней записи, гарантируя атомарность всего, что пишется на диск через журнал. Результатом является гарантия, что файловая система не застрянет на полпути обновления метаданных.
Разрежённые файлы
Большинство современных файловых систем поддерживают разрежённые файлы (sparse files). У таких файлов могут быть дыры, которые в действительности не записаны на диск (не занимают дисковое пространство). На этот раз реальный размер файла будет больше, чем используемые блоки.

Такая особенность может оказаться очень полезной, например, для быстрой генерации больших файлов или для предоставления свободного пространства виртуальному жёсткому диску виртуальной машины по запросу.
Чтобы медленно создать 10-гигабайтный файл, который занимает около 10 ГБ дискового пространства, можно выполнить:
Или же воспользоваться командой truncate :
Дисковое пространство, выделенное файлу, можно изменить командой fallocate , которая делает системный вызов fallocate() . С этим вызовом доступны и более продвинутые операции — например:
- Предварительно выделить пространство для файла вставкой нулей. Такая операция увеличивает и использование дискового пространства, и размер файла.
- Освободить пространство. Операция создаст дыру в файле, делая его разрежённым и уменьшая использование пространства без влияния на размер файла.
- Оптимизировать пространство, уменьшив размер файла и использование диска.
- Увеличить пространство файла, вставив дыру в его конец. Размер файла увеличивается, а использование диска не меняется.
- Обнулить дыры. Дыры станут не записанными на диск extents, которые будут читаться как нули, не влияя на дисковое пространство и его использование.
Команда cp поддерживает работу с разрежёнными файлами. С помощью простой эвристики она пытается определить, является ли исходный файл разрежённым: если это так, то результирующий файл тоже будет разрежённым. Скопировать же неразрежённый файл в разрежённый можно так:
Таким образом, если вам нравится работать с разрежёнными файлами, можете добавить следующий алиас в окружение своего терминала ( ~/.zshrc или ~/.bashrc ):
Когда процессы читают байты в секциях дыр файловая система предоставляет им страницы с нулями. Например, можно посмотреть, что происходит, когда файловый кэш читает из файловой системы в области дыр в ext4. В этом случае последовательность в readpage.c будет выглядеть примерно так:
После этого сегмент памяти, к которому процесс пытается обратиться с помощью системного вызова read() , получит нули напрямую из быстрой памяти.
Команда целиком
Выберем из карты все плохие куски (содержат – и не являются строкой с самой командой):
Получится нечто такое:
Преобразуем в формулы для вычисления номеров кластеров в 16ричной системе счисления:
К сожалению, числа получились на разных строках – объединяем их через дефис, затем каждый второй дефис заменяем переводом строки, затем уберём дубликаты строк:
Объединим последовательные цепочки, если конечный кластер первой совпадает с начальным следующей. Для этого объединим строки через пробел и поудаляем -число такое-же-число . У меня sed не съел d , поэтому я использовал w . После замены вернём на место переводы строк.
Приготовимся посчитать номер следующего за концом кластера:
По аналогии с прошлым разом, объединяем строки через дефис, а каждый третий дефоис заменяем пробелом:
Объединяем цепочки, где начальный кластер следующий совпадает со следующим за конечным кластером предыдущей:
Убираем лишнюю информацию о следующем кластере:
Контрольные суммы
Файловые системы последнего поколения хранят также контрольные суммы (checksums) для блоков данных во избежание незаметного повреждения данных. Эта возможность позволяет обнаруживать и корректировать случайные ошибки и, конечно, ведёт к дополнительным накладным расходам в использовании диска пропорционально размеру файлов.
Более современные системы вроде BTRFS и ZFS поддерживают контрольные суммы для данных, а у более старых, таких как ext4, реализованы контрольные суммы для метаданных.
Файловые системы COW (copy-on-write)
Следующее (после семейства ext) поколение файловых систем принесло очень интересные возможности. Пожалуй, наибольшего внимания среди фич файловых систем вроде ZFS и BTRFS заслуживает их COW (copy-on-write, «копирование при записи»).

Как видно, клонирование — очень быстрая операция, не требующая удваивания пространства, которое используется в случае обычной копии. Именно эта технология и стоит за возможностью создания мгновенных снапшотов в BTRFS и ZFS. Вы можете буквально клонировать (или сделать снапшот) всей корневой файловой системы меньше чем за секунду. Очень полезно, например, перед обновлением пакетов на случай, если что-то сломается.
BTRFS поддерживает два метода создания shallow-копий. Первый относится к подтомам (subvolumes) и использует команду btrfs subvolume snapshot . Второй — к отдельным файлам и использует cp –reflink . Такой алиас (опять же, для ~/.zshrc или ~/.bashrc ) может пригодиться, если вы хотите по умолчанию делать быстрые shallow-копии:
cp=’cp –reflink=auto –sparse=always’
Следующий шаг — если есть не-shallow-копии или файл, или даже файлы, с дублирующимися extents, можно дедуплицировать их, чтобы они использовали (через reflink) общие extents и освободили пространство. Один из инструментов для этого — duperemove, однако учтите, что это естественным образом приводит к более высокой фрагментации файлов.
Если мы попытаемся теперь разобраться, как дисковое пространство используется файлами, всё будет не так просто. Утилиты вроде du или dutree всего лишь считают используемые блоки, не учитывая, что некоторые из них могут быть разделяемыми, поэтому они покажут больше занятого места, чем на самом деле используется.
Аналогичным образом, в случае BTRFS стоит избегать команды df , поскольку пространство, занятое файловой системой BTRFS, она покажет как свободное. Лучше пользоваться btrfs filesystem usage :
К сожалению, я не знаю простых способов отслеживания занятого пространства отдельными файлами в файловых системах с COW. На уровне подтома с помощью утилит вроде btrfs-du мы можем получить приблизительное представление о количестве данных, которые уникальны для снапшота и которые разделяются между снапшотами.
Всем здравствуйте! При создании файловой системы например в виндовс fat32 можно указать размер кластера при форматировании. Например 4кб. Как это сделать в linux? Может есть какой-то параметр в mkfs? В gparted таких настроек не нашел. Например в файловой системе ext4, btrfs, xfs, f2fs и т.д.

Соответственно, вам также потребуется что-то в духе -O bigalloc
Но я бы очень рекомендовал сначала всё попробовать на тестовой машине, без важных данных, т.к. я встречал жалобы на проблемы с монтированием ФС после подобных операций, как минимум, на ext.


При помощи ddrescue создан образ диска. К нему есть карта, что не удалось скопировать. Начинается вот так:
Насколько я понимаю, это означает, что 0x400 байт начиная с 0x52C15CAC00 не удалось прочитать. Как понять, какие именно файлы повреждены? Файловая система NTFS.
набор вроде нельзя перечислить? это же не ms/windows. здесь подобное сделать несложно: for i in 0-100 101-200 201-300; do sudo ntfscluster -s $i раздел; done . можно пояснить перенаправление stderr? — да, спрашивайте.
Как проверить жесткий диск
Друзья, говорят краткость сестра таланта, один мой приятель, прочитав данный вопрос, ответил на него так: — «Царапину не залепишь ничем, а софтовый бэд лечится нулём».
Тема непростая, но актуальная, статья длинная, но я постарался, что бы она была доступная для понимания простому пользователю. Что бы легче всё было понять, я предлагаю по ходу статьи пошагово проверить бесплатной программой жёсткий диск MAXTOR STM3250310AS, установленный в компьютере, который принесли в наш сервис на ремонт. Установленная на жёстком диске операционная система, время от времени зависает, отказывается загружаться, выдавая разные ошибки или просто чёрный экран. Жёсткий диск поскрипывает и щёлкает, (ниже объясню почему). Переустановка Windows делу не помогла и хозяева компьютера не знают что делать.
Итак как проверить состояние жёсткого диска? Сделать это можно различными тестами в программе HDDScan, для начала проверим показатели S.M.A.R.T данного винчестера, затем проведём тест поверхности винчестера, обнаружим ни много ни мало 63 сбойных сектора и наша программа их все исправит, другой вопрос надолго ли (читаем далее).
изготовлен из алюминиевых или стеклянных пластин, покрытых слоем ферромагнитного материала. Жёсткий диск это в первую очередь устройство работающее по принципу магнитной записи. Магнитные головки, считывающие, записывающие или стирающие информацию с жёсткого диска, парят над его поверхностью на высоте 10-12 нм и никогда не касаются поверхности магнитного диска, который легко повредить.
- На заключительном этапе производства винчестера, проводится , то есть на рабочие пластины жёсткого диска наносятся дорожки, каждая дорожка делится на секторы. Так же на магнитную поверхность жёсткого диска наносятся специальные магнитные сервометки, они нужны для точного попадания магнитной головки винчестера на дорожки жёсткого диска. Минимальная единица информации на жёстком диске это , объём доступный пользователю составляет 512 байт данных. Низкоуровневое форматирование в жизни жёсткого диска происходит только один раз друзья и только на специальном и очень дорогом заводском оборудовании – называемом . Информация записанная с помощью такого форматирования уже никогда не будет перезаписана. Ни в каком сервисе друзья, такое форматирование сделать не удастся. Поэтому мой ответ на вопрос, можно ли провести низкоуровневое форматирование средствами операционной системы, будет ответ – нет нельзя. Низкоуровневое форматирование можно сделать только на заводе, оно уничтожает даже дорожки, сектора и магнитные сервометки. К примеру, режим Write в программе Виктория затирает всю информацию на жёстком диске путём заполнения всех секторов нулями, это нельзя назвать низкоуровневым форматированием, но и форматированием назвать нельзя, это что-то среднее. После режима Write все сектора жёсткого диска заполнены нулями и не содержат никаких ошибок и его можно форматировать в файловую систему средствами Windows.
- На заводе в секторы записывается только служебная информация (, к примеру физический адрес сектора и адресный маркер, определяющий начало сектора), данную информацию можно назвать разметкой, она нужна для нормальной работы жёсткого диска, это информация о номерах дорожек и секторов, нужная для безошибочного попадания головок на эти дорожки и сектора при считывании информации записанных в них.Уже после покупки жёсткого диска, пользовательские данные так же позже будут записаны в эту область (к примеру первый сектор жёсткого диска будет содержать главную загрузочную запись MBR), но данные пользователя можно будет записывать и стирать, в отличии от служебной информации, которая обладает намного большей намагниченностью, именно поэтому головки чтения-записи накопителя не могут её затереть.
Вся служебная информация о номерах дорожек и секторов будет храниться в специальной таблице, находящейся в закрытой и недоступной для средств ОС и BIOS , представляющей из себя миниоперационную систему, вместе с прошивкой они управляют работой жёсткого диска. Иногда задают вопрос – Нужно ли иногда обновлять прошивку жёсткого диска, ответ отрицательный, современные винчестеры в обновлении не нуждаются. Так же в данной служебной зоне будет храниться паспорт диска, значения атрибутов SMART, а так же таблица-дефектов с информацией о невосстановимых или переназначенных сбойных секторах (бэд-блоках). Вот мы и добрались с Вами до физических, логических и программных сбойных секторов.
Дело в том друзья, что если операционная система, испытывает проблемы с чтением данных с какого-либо сектора, то контроллер винчестера предпринимает ещё несколько дополнительных попыток прочитать данные, если они так же неудачны, данный сектор признаётся сбойным, в дальнейшем информация записывается в нормальный сектор, находящийся на резервной дорожке, а проблемный сектор признаётся сбойным и выводится из обращения, это называется (, в простонародье ремап).
Факт признания сектора сбойным заносится в таблицу-дефектов с информацией о невосстановимых или переназначенных сбойных секторах, находящуюся в служебной зоне.
Кстати таблиц дефектов бывает две, одна начальная (Primary-list), создаётся после конечных заводских испытаний, любой жёсткий диск друзья уже при выходе с завода имеет уже несколько переназначенных бэд-блоков. Ну а растущая таблица дефектов (Grown-list), заполняется по мере использования жёсткого диска уже нами.
Какие бывают сбойные сектора и как их исправить?
Почему жёсткий диск скрипит и щёлкает иногда при работе
Когда операционная система встречает сбойный сектор, контроллер жёсткого диска, предпринимает несколько попыток прочесть информацию из него, при этом щелчки и скрип может издавать позиционер головки винчестера.
Так же причиной щелчков и скрипа жёсткого диска может быть следующая причина. При переназначении сбойного сектора нормальным с резервной дорожки (находящейся не всегда рядом), магнитной головке естественно приходится менять направление, как говорят многие скакать из стороны в сторону.
Третья причина –как я уже говорил выше, при изготовлении жёсткого диска, производится специальная разметка магнитной поверхности жёстких дисков специальными сервометками, служат данные сервометки для точного позиционирования магнитной головки на дорожках винчестера, именно с помощью сервометок магнитная головка винчестера двигается правильно. Иногда сервометки разрушаются по тем же причинам, по которым образуются физические бэд-блоки и магнитная головка не может занять и удержать нужное ей положение, при этом из жёсткого диска раздаются щелчки и скрип.
Вы скажете, что всё это хорошо и понятно, но как избавиться от бэд-блоков, может перекинуть с винчестера данные и форматировать в программе установки операционной системы?
При форматировании всеми способами, доступными операционной системе, произойдёт та же самая попытка прочесть информацию из сбойного сектора, потом сравнить их с контрольной суммой ECC, а она не совпадает и значит перезапись неправильной информации не произойдёт и сбойный сектор останется сбойным даже после форматирования. Вот и получается, что нужна специальная программа, например МHDD или HDDScan, которая ничего не будет считывать, а просто принудительно сделает перезапись, обычно заполнит сбойный сектор нулями, а вот затем уже прочитает записанное и сравнит контрольную сумму, после этого сектор вернётся в работу.
К примеру в программе HDDScan есть функция —Тест в режиме линейной записи (посекторное стирание данных) осторожно все ваши данные удалятся. К сожалению без удаления данных ничего не получится, поэтому перед этим тестом их необходимо перенести на другой носитель информации.
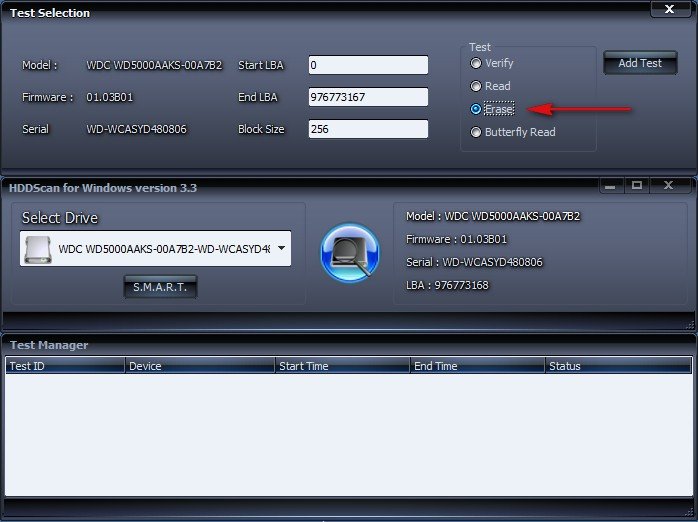
А лучше всего совсем снять ваш жёсткий диск и подсоединить его к другому компьютеру имеющему программу HDDScan, затем запустить тест Erase и проверить весь ваш винчестер. Можно и не снимать ничего, записать загрузочные диски с программами или , загрузиться с них и запустить данные программы с функцией , но это мы сделаем в других статьях.
Теперь друзья переходим непосредственно к работе с программой HDDScan, с помощью этой программы, мы увидим полную картину происходящего с нашим жёстким диском, а именно узнаем S.M.A.R.T нашего винчестера и расшифруем его, так же установим количество сбойных секторов и конечно попытаемся их исправить.Читаем далее статью HDDScan.
читайте по этой теме новую статью Как пользоваться одной из легендарных программ по диагностике жёстких дисков под названием Victoria!
Размер файла
Что такое размер файла? Ответ вроде бы прост: совокупность всех байтов его содержимого, от начала до конца файла.
Зачастую всё содержимое файла представляется как расположенное байт за байтом:

Так же мы воспринимаем и понятие размер файла. Чтобы его узнать, выполняем ls -l file.c или команду stat (т.е. stat file.c ), которая делает системный вызов stat() .
В ядре Linux структурой памяти, представляющей файл, является inode. И метаданные, к которым мы обращаемся с помощью команды stat , находятся именно в inode.
Здесь можно увидеть знакомые атрибуты, такие как время доступа и модификации, а также i_size — это и есть размер файла, как он был определён выше.
Размышлять в терминах размера файла интуитивно понятно, но больше нас интересует, как в действительности используется пространство.
Специфичные для файловой системы возможности
Помимо актуального содержимого файла ядру также необходимо хранить все виды метаданных. Метаданные inode’а мы уже видели, но есть и другие данные, с которыми знаком каждый пользователь UNIX: права доступа, владелец, uid, gid, флаги, ACL.
Уровень RAID
Если Ваша система хранения представляет собой массив накопителей объединенных в RAID определенного уровня, то производительность системы будет зависеть в значительной степени от того, какой именно уровень RAID был применен и какой процент от общего числа операций приходится на операции записи, ведь именно запись является причиной снижения производительности в большинстве случаев.
Так, при RAID0, на каждую операцию ввода будет расходоваться лишь 1 IOPS, ведь данные будут распределены по всем накопителям без дублирования. В случае же зеркала (RAID1, RAID10), каждая операция записи будет потреблять уже 2 IOPS, так как информация должна быть записана на 2 накопителя.
В более высоких уровнях RAID потери еще существеннее, к примеру в RAID5 штрафной коэффициент будет уже 4, что связано с тем, каким образом данные распределяются по дисках.
RAID5 используется вместо RAID4 в большинстве случаев, так как распределяет четность (контрольные суммы) по всем дискам. В массиве RAID4 один из дисков ответственен за всю четность, в то время как данные распространены более чем на 3 диска. Именно потому мы применяем штрафной коэффициент 4 в массиве RAID5, так как мы читаем данные, читаем четность, затем пишем данные и пишем четность.
В массиве RAID6 все аналогично, за исключением того, что мы вместо вычисления четности единожды, делаем это дважды и таким образом имеем 3 операции чтения и 3 записи, что дает нам уже штрафной коэффициент 6.
При больших массивах RAID-DP, которые состоят из десятков дисков, существует понятие уменьшения «штрафа четности», который возникает при записи четности. Так при росте массива RAID-DP, требуется меньшее количество дисков, выделяемых под четность, что приведет к снижению потерь, связанных с записями четностей. Однако в небольших массивах, либо с целью повышения консерватизма, мы можем пренебречь этим явлением.
Теперь, зная о потерях IOPS в результате применения того либо другого уровня RAID, мы можем рассчитать производительность массива. Однако, пожалуйста, примите к сведению, что другие факторы, такие как пропускная способность интерфейса, неоптимальное распределение прерываний по ядрах процессора и т.п., пропускная способность RAID-контроллера, превышение допустимой глубины очереди — могут оказывать негативное влияние.
В случае пренебрежения этими факторами, формула будет следующей:
Функциональные IOPS = (Исходные IOPS * % операций записи / штрафной коэффициент RAID) + (Исходные IOPS * % чтения), где Исходные IOPS = усредненный IOPS накопителей * количество накопителей.
Рассчитаем для примера производительность массива RAID10 из 12 дисков HDD SATA, если известно, что одновременно происходит 10% операций записи и 90% операций чтения. Допустим, что диск обеспечивает 75 случайных IOPS, при размере блока 4КБ.
Исходные IOPS = 75*12 = 900;
Функциональные IOPS = (900*0,1/2) + (900*0,9) = 855.
Таким образом видим, что при малой интенсивности записи, что в основном наблюдается в системах, рассчитанных на отдачу контента, влияние штрафного коэффициента RAID минимально.
В целях консерватизма я рекомендую добавлять от 20% от нужного числа IOPS, при проектировании систем.
Как узнать размер кластера на диске
fsutil fsinfo ntfsinfo C:
где C – название диска, для которого нужно получить данные.
Какой размер кластера предпочтителен
Илья – главный редактор сайта softdroid.net. Является автором нескольких сотен руководств и статей по настройке Android. Около 15 лет занимается ремонтом техники и решением технических проблем iOS и Android. Имел дело практически со всеми более-менее популярными марками мобильных смартфонов и планшетов Samsung, HTC, Xiaomi и др. Для тестирования используется iPhone 12 и Samsung Galaxy S21 с последней версией прошивки.
Я купил жесткий диск, размер 1 Тб, на нем размещен 1 NTFS раздел. Я собираюсь хранить все данные на нем. При форматировании требуется указать размер кластера. Размеры варьируются от 512 байт до 64 Кб. Какую опцию использовать при форматировании, или можно не менять стандартный размер кластера?
2 ответа 2
как пишут здесь, нужно разделить номер блока на размер кластера, используемого данной файловой системой, и перевести результат в десятичную систему счисления.
в шестнадцатиричной это будет:
делим номер из вопроса (0x52C15CAC00) на 1000 и получаем результат в десятичной системе счисления:
узнаём, что за файл(ы) располагаются в этом кластере (пример вывода команды взят из вышеупомянутой инструкции):
Замечу, что надо предварительно выполнить любую команду sudo , чтобы последняя команда не съелась в качестве пароля. Тогда на остальные команды пароль запрашиваться не будет и всё будет работать.
Существенный минус этого решения – то, что для каждого диапазона кластеров снова сканируется файловая система, т. е. работает очень медленно.
Теперь поясню, что же здесь происходит.
Информацию о диске можно получить при помощи ntfsinfo . Опция -f нужна чтобы образ не ставился на проверку с просьбой перезагрузиться дважды. Перенаправление ошибок в /dev/null чтобы избавиться от WARNING: Dirty volume mount was forced by the ‘force’ mount option.
Выберем отсюда строку с информацией о размере кластера:
Достанем из неё число и переведём в 16ричную систему счисления:
Сохраним в переменную:
«Упаковка хвостов»

Оборачиваем получившуюся выше конструкцию в качестве набора для цикла for:
В итоге получается интересующий нас список файлов вместе с указанием кластеров.
В данной статье мы рассмотрим несколько команд, которые могут быть использованы для проверки разделов в вашей файловой системе Linux. Команды могут быть использованы для просмотра информации о разделах, свободном и использованном дисковом пространстве на диске, а так же другой полезной информации о разделах. Кроме того, такие команды как FDISK, SFDISK и CFDISK могут не только отображать информацию о разделах, но и вносить какие-либо изменения.
1. FDISK — является часто используемой командой для проверки разделов на диске. Она может отобразить список разделов, а так же дополнительную информацию.
2. Sfdisk — отображает похожую информацию, так же как и FDISK, однако есть и некоторые особенности, к примеру, отображение размера каждого раздела в мегабайтах.
3. cfdisk — является редактором разделов Linux с интерактивным пользовательским интерфейсом Ncurses. Команда может быть использована для отображения списка существующих разделов, а так же внесения каких либо изменений.

4. parted — ещё одна утилита командной строки, которая умеет отображать список разделов, информацию о них, а так же позволяет вносить изменения в разделы при необходимости.
5. DF — не является утилитой для разметки разделов, скорее больше для просмотра информации. Можно отметить то, что утилита DF способна вывести информацию о файловых системах, которые даже не являются реальными разделами диска.
6. Pydf — является в неком роде улучшением версии DF, которая написана на Python. Способна выводить информацию о всех разделах жесткого диска в удобном виде. Но есть и минусы, показываются только смонтированные файловые системы.
7. lsblk — выводит список всех блоков хранения информации, среди которых могут быть дисковые разделы и оптические приводы. Отображается такая информация как общий размер раздела/блока, точка монтирования (если таковая есть). Если нет точки монтирования, то это может значить что файловая система не смонтирована, для CD/DVD привода дисков это означает, что в лотке нету диска.
8. BLKID — выводит информацию о разделах файловой системы, среди них такие атрибуты как UUID, а так же тип файловой системы. Однако эта утилита не сообщает о дисковом пространстве на разделах.
9. HWiNFO — может быть использована для вывода списка оборудования и разделов для хранения данных. В результате вывода нет подробностей о каждом разделе, к примеру, как у команд, о которых шла речь выше.
Попробуйте воспользоваться командами, о которых мы говорили в этой статье, оставляйте свои отзывы и дополнения к ним в комментариях. Так же рекомендую просмотреть пост, в котором опубликован список команд для просмотра информации о системе.
Метаданные размещения блоков

Эту же таблицу можно увидеть в структуре памяти (фрагмент из fs/ext2/ext2.h ):
Для больших файлов такая схема приводит к большим накладным расходам, поскольку единственный (большой) файл требует сопоставления тысяч блоков. Кроме того, есть ограничение на размер файла: используя такой метод, 32-битная файловая система ext3 поддерживает файлы не более 8 ТБ. Разработчики ext3 спасали ситуацию поддержкой 48 бит и добавлением extents:
Идея по-настоящему проста: занимать соседние блоки на диске и просто объявлять, где extent начинается и каков его размер. Таким образом мы можем выделять файлу большие группы блоков, минимизируя количество метаданных и заодно используя более быстрый последовательный доступ.
Примечание для любопытных: у ext4 предусмотрена обратная совместимость, то есть в ней поддерживаются оба метода: непрямой (indirect) и extents. Увидеть, как распределено пространство, можно на примере операции записи. Запись не идёт напрямую в хранилище — из соображений производительности данные сначала попадают в файловый кэш. После этого в определённый момент кэш записывает информацию на постоянное хранилище.
Кэш файловой системы представлен структурой address_space , в которой вызывается операция writepages. Вся последовательность выглядит так:
Дополнительная информация
Раздел (том) жесткого диска можно отформатировать под файловую систему NTFS, FAT или exFAT. В зависимости от метода форматирования раздела в Windows могут использоваться следующие значения по умолчанию.
С помощью команды FORMAT без указания размера кластера.
С помощью программы Windows Explorer, когда в поле Единица размещения в диалоговом окне Формат оставлено значение Стандартный размер размещения.
По умолчанию размер кластера для файловой системы NTFS в Windows NT 4.0 и более поздних версий равен 4 КБ. Это обусловлено тем, что сжатие файлов в NTFS невозможно для дисков с большим размером кластера. Команда форматирования не использует размер кластера больше 4 КБ, кроме случая, когда пользователь переопределяет значения по умолчанию. Вы можете сделать это, используя /А: переключение вместе с командой Format или с помощью указания большего размера кластера в соответствующем поле при форматировании с помощью проводника.
Размеры кластера по умолчанию для файловой системы NTFS
В следующей таблице описаны размеры кластера по умолчанию для NTFS.
Windows 7, Windows Server 2008 R2, Windows Server 2008, Windows Vista, Windows Server 2003, Windows XP и Windows 2000
Зависимость от приложений
Производительность нашего решения очень сильно может зависеть от приложений, которые будут исполнятся впоследствии. Так это может быть обработка транзакций — «структурированных» данных, которые организованы, последовательны и предсказуемы. Зачастую в этих процессах можно применить принцип пакетной обработки, распределив эти процессы во времени так, когда нагрузка минимальна, тем самым оптимизировав потребление IOPS. Однако в последнее время появляется все больше и больше медийных проектов, где данные «не структурированы» и требуют совсем иных принципов их обработки.
По этой причине подсчет необходимой производительности решения для конкретного проекта может стать весьма сложной задачей. Некоторые из производителей сторедж-хранилищ и экспертов утверждают, что IOPS не имеют значения, так как клиенты в подавляющем большинстве используют до 30-40 тысяч IOPS, в то время, как современные системы хранения обеспечивают сотни тысяч и даже миллионы IOPS. То есть современные хранилища удовлетворяют нужды 99% клиентов. Тем не менее это утверждение может быть справедливо далеко не всегда, лишь для бизнес-сегмента, который размещает хранилища у себя, локально, но не для проектов, размещаемых в дата-центрах, которые зачастую, даже при использовании готовых решений хранения, должны обеспечивать довольно высокую производительность и отказоустойчивость.
В случае размещения проекта в дата-центре, в большинстве случаев, все же более экономично строить системы хранения самостоятельно на основе выделенных серверов, нежели использовать готовые решения, так как становится возможным более эффективно распределить нагрузку и подобрать оптимальное оборудование для тех, либо других процессов. Помимо прочего, показатели производительности готовых систем хранения, далеки от реальных, так как в большинстве своем основаны на данных профилей синтетических тестов производительности, при применении 4 или 8 КБ размера блока, в то время как большинство клиентских приложений работает сейчас в средах с размером блока от 32 до 64 КБ.
Как видим из графика:

А что на счет задержек?
Даже если мы будем игнорировать тот факт, что инструменты, применяемые для измерения latency, имеют тенденцию измерять средние времена ожидания и упускают то, что один единственный I/O в каком-то из процессов, может занимать куда больше времени, чем другие, таким образом замедляя ход всего процесса, то совсем не учитывают то, насколько время ожидания I/O изменится в зависимости от размера блока. Помимо прочего это время также будет зависеть от конкретного приложения.
Таким образом мы приходим к еще одному волшебному выводу, что не только размер блока является не очень хорошей характеристикой при измерении производительности IOPS систем, но и latency может оказаться вполне бесполезным параметром.
Хорошо, если ни IOPS, ни время ожидания не являются хорошей мерой измерения производительности системы хранения, то что тогда?
Этот тест будет тем реальным методом, который наверняка позволит понять, насколько производительным будет решение для Вашего случая. Для этого понадобится запустить копию приложения на отдельно взятом хранилище и симулировать нагрузку за определенный период. Только так можно получить достоверные данные. И разумеется, нужно измерять не метрики хранилища, а метрики приложения.
Тем не менее учет приведенных выше факторов, влияющих на производительность наших систем, может быть весьма полезным при подборе хранилища или построении определенной инфраструктуры на основе выделенных серверов. С определенной степенью консерватизма становится возможным подобрать более-менее реальное решение, исключить некоторые технические и программные изъяны в виде не оптимального размера блока при разбивке или не оптимальной работы с дисками. Решение, конечно, не будет на 100% гарантировать расчетную производительность, но в 99% случаев можно будет говорить, что решение справится с нагрузкой, особенно, если добавлять консерватизм в зависимости от типа приложения и его особенностей в расчет.
Аннотация
Если размер кластера не задан во время форматирования раздела, используются значения по умолчанию, зависящие от размера раздела. Эти значения выбираются с учетом оптимального соотношения теряемого объема и числа кластеров в разделе.



