

Рассказываем, как пользоваться cURL и какие задачи с его помощью можно решить.
Статью подготовил Юрий Никулин, эксперт в продуктовом SEO. Юрий — преподаватель в it-школах «Нетология» и «CyberMarketing», победитель Сколково в номинации «Лучший стартрап в сфере IT технологий» в 2023 году и модератор на конференции «Optimization».
Что такое cURL
cURL (Client URL) — это обычная программа встроенной командной строки в Windows или в MAC. Она позволяет взаимодействовать с сервером по разным протоколам, используя URL в запросе.
Протоколов достаточно много, но для SEO специалистов в 99% случаев, нужны только HTTP и HTTPS:
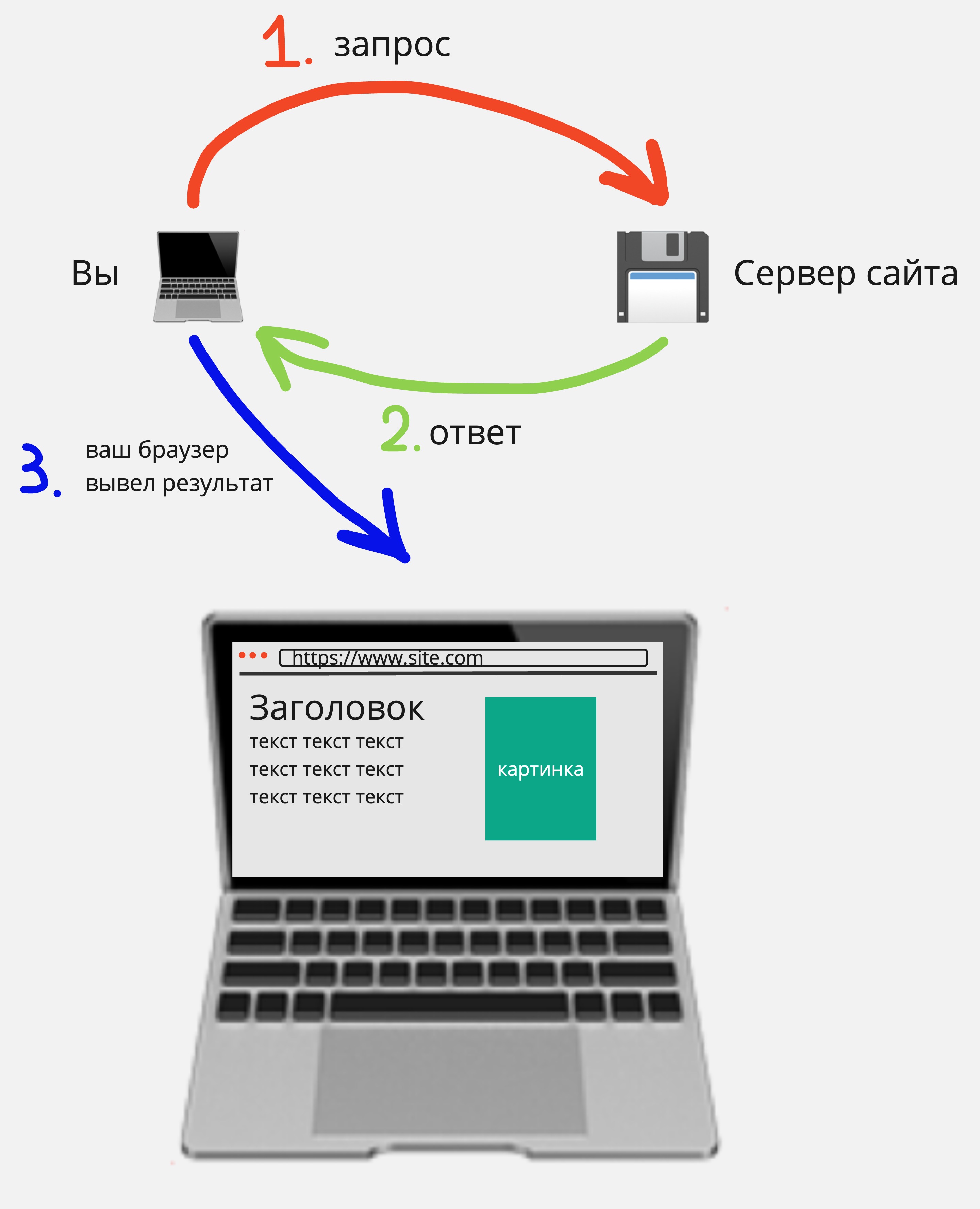
HTTP это устаревший незащищенный протокол передачи данных между двумя серверами, например между вашим компьютером (браузером) и сервером любого сайта. Пример: http://www.site.com
HTTPS это расширение к протоколу HTTP, только данные передаются в зашифрованном виде. Пример: https://www.site.com
Так выглядит простейшая схему работы протокола HTTP/HTTPS:
В этой статье вы узнаете, как можно использовать вместе Python и cURL для автоматизации запросов GET, POST и PUT, а также для загрузки файлов и веб-страниц.
4 min read

cURL — это универсальный инструмент командной строки с открытым исходным кодом для передачи данных по сети. Он поставляется с большим количеством параметров, поэтому может обрабатывать практически любой запрос. Кроме того, cURL расширяемый и имеет интерфейс практически на каждом современном языке программирования.
Использование cURL с языком программирования дает множество преимуществ. Например, создание запросов может быть автоматизировано для настройки или веб-скрапинга.
В этой статье вы узнаете, как можно использовать Python и cURL для автоматизации запросов GET, POST и PUT, а также для загрузки файлов и веб-страниц.
Что такое cURL?
cURL — это программный проект. Однако его имя также используется в двух продуктах: библиотека libcurl и инструмент командной строки, известный как curl (который использует libcurl). При упоминании curl в этой статье подразумевается именно инструмент командной строки.
cURL считается универсальным. Однако его основная задача простая – передача данных по различным сетевым протоколам. Учитывая сложность современной сети, curl предлагает огромный список опций для обработки самых сложных запросов.
cURL выпустили в 1996 году под названием HttpGet и позже переименовали в urlget, затем он стал curl. Первым вариантом использования было получение курсов обмена валют для использования их в IRC-канале. В настоящее время curl поддерживает передачу данных различными способами, включая FTP(S), HTTP(S) (POST, GET, PUT), IMAP, POP3, MQTT и SMB. Кроме того, curl может обрабатывать файлы cookie и SSL-сертификаты.
Когда curl устанавливает соединение через HTTPS, он получает сертификат удаленного сервера и сверяет его со своим хранилищем сертификатов CA, чтобы убедиться, что удаленный сервер является тем, за кого себя выдает. Например, следующий запрос отправляет HTTPS-запрос на сайт Bright Data и устанавливает файл cookie, известный как greeting, со значением hello:
curl --cookie "greeting=hello" https://www.brightdata.comКогда речь заходит о парсинге или об автоматизации рутинных задач в интернете, бородатые сисадмины и web-программисты (как начинающие, так и профи) всегда знают волшебный рецепт, который сможет решить практически любые «хотелки» – это великий и ужасный cURL.
Всех слабонервных просьба отойти от экранов и переключиться на что-то более позитивное. Ниже речь о хардкор-решениях для профи, а также для тех, кто задумывается о создании своего собственного парсера.
Ранее мы рассказывали о разных библиотеках и фреймворках для Python, а также о библиотеках для парсинга на языке Go. Сейчас о command-like интерфейсе и о том, как использовать cURL через прокси.
cURL – это связка из кроссплатформенной библиотеки (libcurl) и программы, управляемой с помощью интерфейса командной строки, предназначенной для обмена информацией и файлами посредством различных интернет-протоколов. В списке поддерживаемых протоколов более десятка наименований, но всех их объединяет работа с адресами на основе разметки URL.
Собственно, сURL – это анаграмма от слов «Client URL». Аббревиатура URL расшифровывается как Uniform Resource Locator, что в переводе означает «единый/унифицированный указатель ресурса».
Многие обыватели привыкли называть URL-адреса ссылками. Типовая структура URL-адреса выглядит следующим образом:
Если какие-то элементы не используются, то они опускаются (то есть убираются из URL).
Вот так выглядят URL-адреса для известного многим протокола HTTP:
Тот же адрес может выглядеть заметно сложнее, если используется передача дополнительных параметров и якорных ссылок:
Если используется протокол SOCKS5 и параметры авторизации, как в случае с нашими резидентными или мобильными прокси, то URL будет выглядеть примерно так:
cURL поддерживает следующие протоколы:
- HTTP и его защищённая версия HTTPS, GOPHER (аналог www),
- Для работы с файлами FTP (FTPS), SFTP, FILE, TFTP, LDAP (LDAPS)
- Для удалённого подключения SCP, SMB, SMBS, TELNET,
- Для работы с почтой POP3 (POP3S), IMAP (IMAPS), SMTP (SMTPS),
- А также DICT, RTMP и RTSP.
Но что самое приятное, cURL умеет работать через HTTP и SOCKS-прокси.
Спектр задач, для которых можно применять cURL, просто нереальный. Это почти что текстовый браузер, только управлять его работой нужно из консоли. И именно поэтому очень важно знать ключевые аргументы cURL и порядок указания их параметров.
cURL обычно используют:
- Самостоятельно, с задействованием интерфейса командной строки.
- В структуре shell-скриптов (или в cmd-скриптах).
- Для взаимодействия с удалёнными программными интерфейсами (API).
Давайте разбираться в деталях.
– инструмент командной строки для получения или отправки данных с использованием синтаксиса URL.
Если вы работаете в службе поддержки, то должны уметь использовать команды cURL для устранения неполадок веб-приложений. – кроссплатформенная утилита для Windows, MAC и UNIX.
Ниже приведены некоторые часто используемые примеры синтаксиса.
Если вы работаете в UNIX-системе и пытаетесь подключиться к внешнему URL-адресу, то сначала проверьте наличие доступа к ресурсу через . Для этого используйте следующую команду:
Если нужно сохранить содержимое URL или URI в конкретном файле, используйте следующий синтаксис:
# curl yoururl.com > yoururl.html
[root@localhost]# curl 74.125.68.100 >/tmp/google.html
Приведенный выше пример сохранит все содержимое с хоста 74.125.68.100 в файл .
Если хотите удостовериться, что получаете ожидаемый заголовок запроса и ответа, используйте следующую команду:
[root@localhost ]# curl -v 74.125.68.100 * About to connect() to 74.125.68.100 port 80 (#0) * Trying 74.125.68.100... * Connected to 74.125.68.100 (74.125.68.100) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.29.0 >Host: 74.125.68.100 >Accept: */* >< HTTP/1.1 200 OK <Date: Sun, 18 Jan 2015 06:02:58 GMT <Expires: -1 < Cache-Control: private, max-age=0 < Content-Type: text/html; charset=ISO-8859-1 < Set-Cookie: NID=67=EZH_o3sPvCSnxzVatz21OHv_; expires=Mon, 20-Jul-2015 06:02:58 GMT; path=/; domain=.; HttpOnly < P3P: CP="This is not a P3P policy! See http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657 for moreinfo." < Server: gws < X-XSS-Protection: 1; mode=block < X-Frame-Options: SAMEORIGIN <Alternate-Protocol: 80:quic,p=0.02 <Accept-Ranges: none <Vary: Accept-Encoding <Transfer-Encoding: chunked
Если нужно узнать, сколько времени требуется для загрузки с определенной скоростью, то используйте следующую команду:
# curl –-limit-rate 2000B
# curl –-limit-rate 2000B 74.125.68.100
Если необходимо проверить, можно ли использовать прокси-сервер, примените следующий синтаксис:
# curl --proxyyourproxy:port http://yoururl.com
Для устранения конкретной проблемы можно использовать , чтобы вставить в свои данные. Рассмотрим следующий пример запроса с Content-Type:
# curl --header 'Content-Type: application/json' http://yoururl.com
Мы просим передать Content-Type в качестве application / json в заголовок запроса.
Вы можете добавить заголовок к запросу с помощью синтаксиса – .
# curl –-header “X-CustomHeader: GeekFlare” http://yoururl.com
[root@localhost]# curl -v --header "X-CustomHeader: GeekFlare" 74.125.68 * About to connect() to 74.125.68.100 port 80 (#0) * Trying 74.125.68.100... * Connected to 74.125.68.100 (74.125.68.100) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.29.0 >Host: 74.125.68.100 >Accept: */* > X-CustomHeader: GeekFlare >< HTTP/1.1 200 OK <Date: Sun, 18 Jan 2015 08:30:25 GMT <Expires: -1 < Cache-Control: private, max-age=0 < Content-Type: text/html; charset=ISO-8859-1 < Set-Cookie: NID=67=CkzDX-zTtWA0d9M1QVG4O3Im; expires=Mon, 20-Jul-2015 08:30:25 GMT; path=/; domain=.; HttpOnly < P3P: CP="This is not a P3P policy! See http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657 for moreinfo." < Server: gws < X-XSS-Protection: 1; mode=block < X-Frame-Options: SAMEORIGIN <Alternate-Protocol: 80:quic,p=0.02 <Accept-Ranges: none <Vary: Accept-Encoding <Transfer-Encoding: chunked
Если вы хотите быстро проверить заголовок ответа, то для этого можно использовать следующий синтаксис.
# curl --head http://yoururl.com
[root@localhost]# curl -I 74.125.68.100 HTTP/1.1 200 OK Date: Sun, 18 Jan 2015 08:31:22 GMT Expires: -1 Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Set-Cookie: NID=67=SpnXKTDUhw7QGakIeLxmDSF; expires=Mon, 20-Jul-2015 08:31:22 GMT; path=/; domain=.; HttpOnly P3P: CP="This is not a P3P policy! See http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657 for moreinfo." Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Alternate-Protocol: 80:quic,p=0.02 Transfer-Encoding: chunked Accept-Ranges: none Vary: Accept-Encoding [root@localhost ]#
Если необходимо получить доступ к https URL-адресу, который выдает ошибку сертификата из-за несоответствия имени хоста, можно использовать следующий синтаксис.
curl --insecure https://yoururl.com
Чтобы подключиться к URL- адресу только по протоколу SSL V2 / V3 или ,используйте следующий синтаксис.
Для подключения с использованием SSLV2:
# curl --sslv2 https://yoururl.com
Для подключения с использованием SSLV3:
# curl --sslv3 https://yoururl.com
Для подключения через TLS:
# curl --tlsv1 https://yoururl.com
С помощью можно загрузить файл с , указав имя пользователя и пароль.
# curl -u user:password -O ftp://ftpurl/style.css
Всегда можно использовать «-v» с любым синтаксисом для вывода в подробном режиме.
Да, это возможно. Вы можете выполнить удаленно с помощью следующих инструментов.
– компактный инструмент для извлечения URL-адреса онлайн и добавления следующих параметров.
--connect-timeout --cookie --data --header --head --location --max-time --proxy --request --user --url --user-agent

cURL command line builder–позволяет создать команду cURL, с помощью которой можно ввести информацию в пользовательский интерфейс.

– полезная утилита для устранения проблем с подключением в режиме реального времени.
Вадим Дворниковавтор-переводчик статьи «11 cURL Command Usage with Real-Time Example»
Работа с cURL
Рассмотрим, как работать с cURL на разных операционных системах.
Windows
Нажмите «Пуск» и введите поиске фразу «Windows terminal». Далее начинайте вводить запросы cURL. Самый распространенный по типу “Hello World” — curl –version, он позволяет проверить версию.
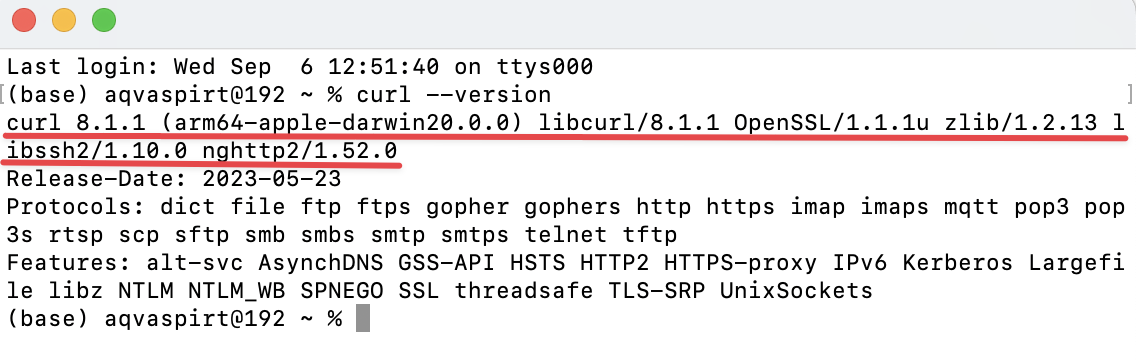
MacOS
Откройте “Launcher” и через поиск выберите там “Terminal”. Введите аналогичный запрос curl –version, после этого должна появиться версия curl, например, вот так:
Linux
На Linux cURL тоже установлен по умолчанию. Для проверки версии cURL на Linux введите в терминале curl –version.
Главная особенность cURL для SEO и на что он способен
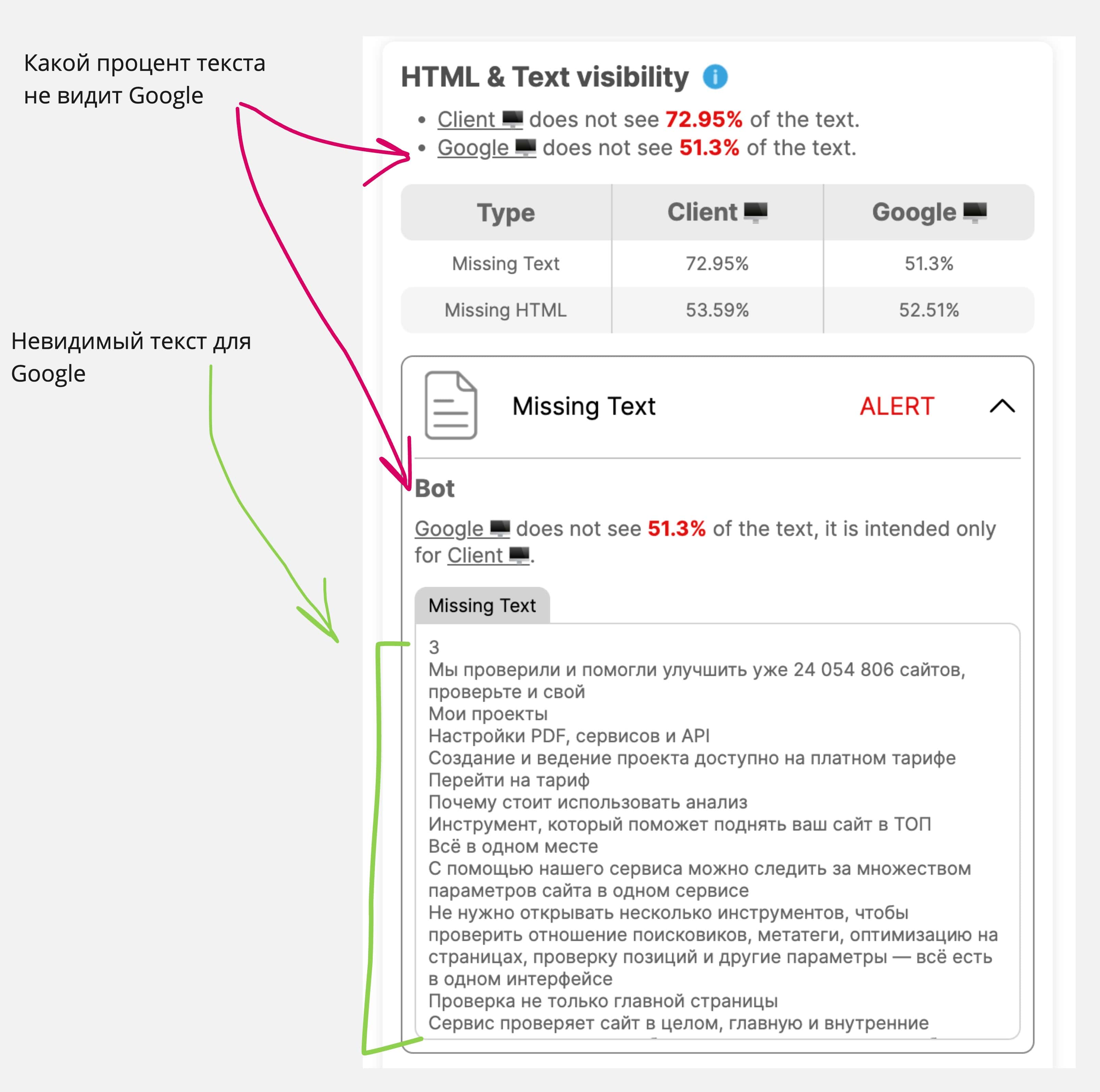
cURL позволяет узнать, как поисковые боты индексируют и видят страницу. Если хотите понять, какой текст HTML скрыт от глаз поисковиков или какие HTTP-заголовки ответа сервера получают боты, cURL поможет.
На что он способен:
Проходить базовую аутентификацию;
Получать HTTP-заголовки и отслеживать цепочки редиректов;
Получать HTML страницы.
Три причины, почему это лучше, чем браузер и его расширения:
Чтобы контролировать процесс самому, в cURL баги не допустимы;
Чтобы притвориться поисковиком, такое может браузер и некоторые расширения;
Пройдемся по каждой из особенностей, опишем возможные задачи и их решения.
Замена user-agent
Задача
Вы хотите посмотреть страницу глазами Яндекса или Google и увидеть какой контент им недоступен. У них, конечно, есть свои инструменты, но Яндекс ограничивает отдачу HTML через инструмент «Проверка ответа сервера» в 50 000 строк, а «Google mobile-friendly test» вовсе перестал работать, так что посмотреть сторонние сайты не получится.
Решение
Шаг 1: вводим команду
- -A — эта опция используется для установки user-agent в HTTP запросе к серверу сайта. К примеру мы хотим притвориться Google. По другому, мы говорим: “Эй, сервер, мы поисковый бот Google! Дай нам тот контент, который ты хочешь показывать этому поисковику”;
- “user -agent” — вставляем от поискового бота, в нашем случае от Google:
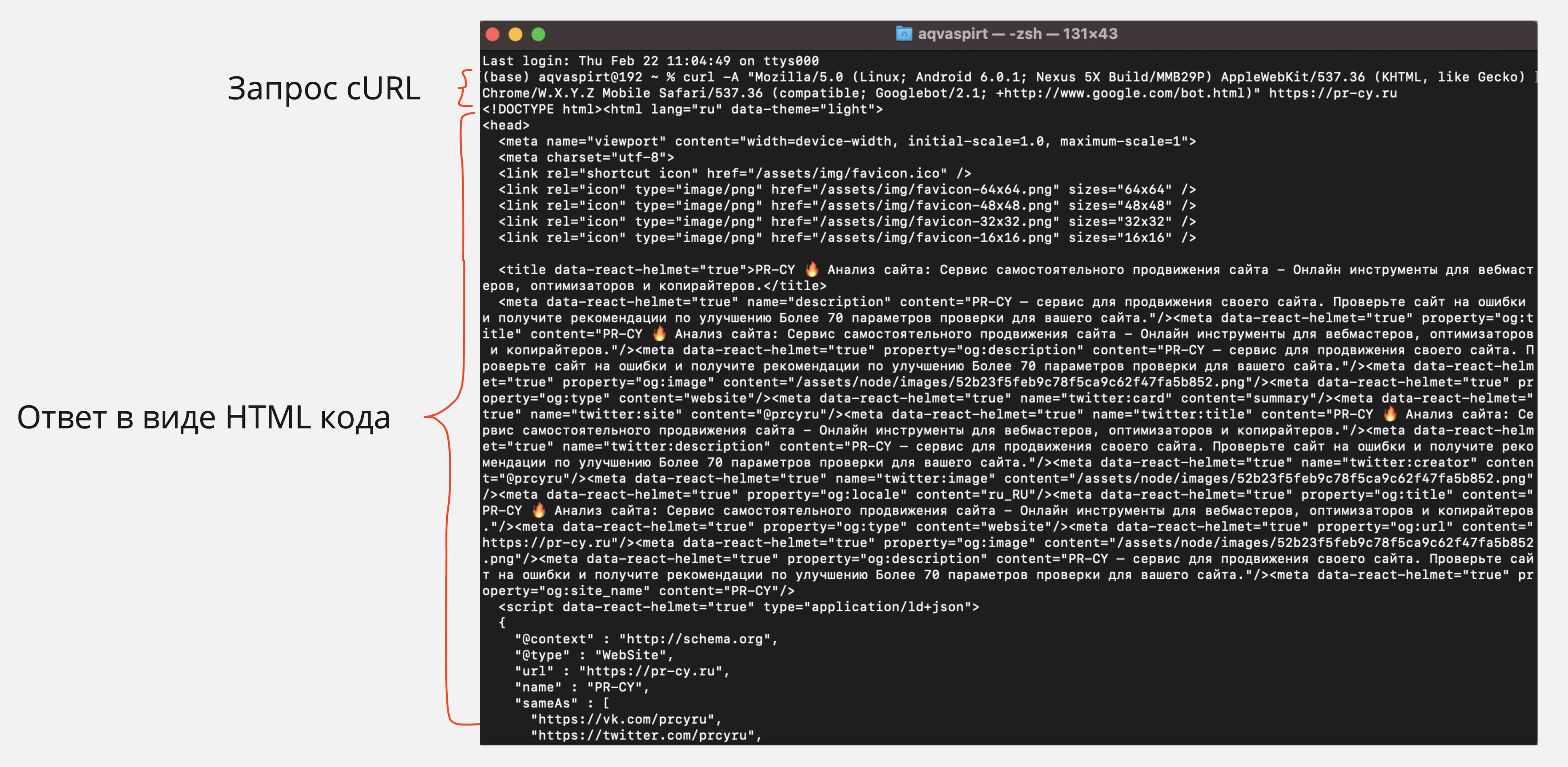
curl -A "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://pr-cy.ru
В итоге cURL возвращает следующий ответ:
Шаг 2: ищем невидимый для Google контент
Есть четыре пути определения контента, который не видит поисковый бот:
1. Очистите текст, который вам выдал cURL, от HTML-тегов, либо найдите любой онлайн-сервис по запросу «Очистить текст от HTML тегов», либо в DevTools в разделе Console введите javascript код console.log(document.body.textContent); и скопируйте полученный текст в какой-нибудь редактор.

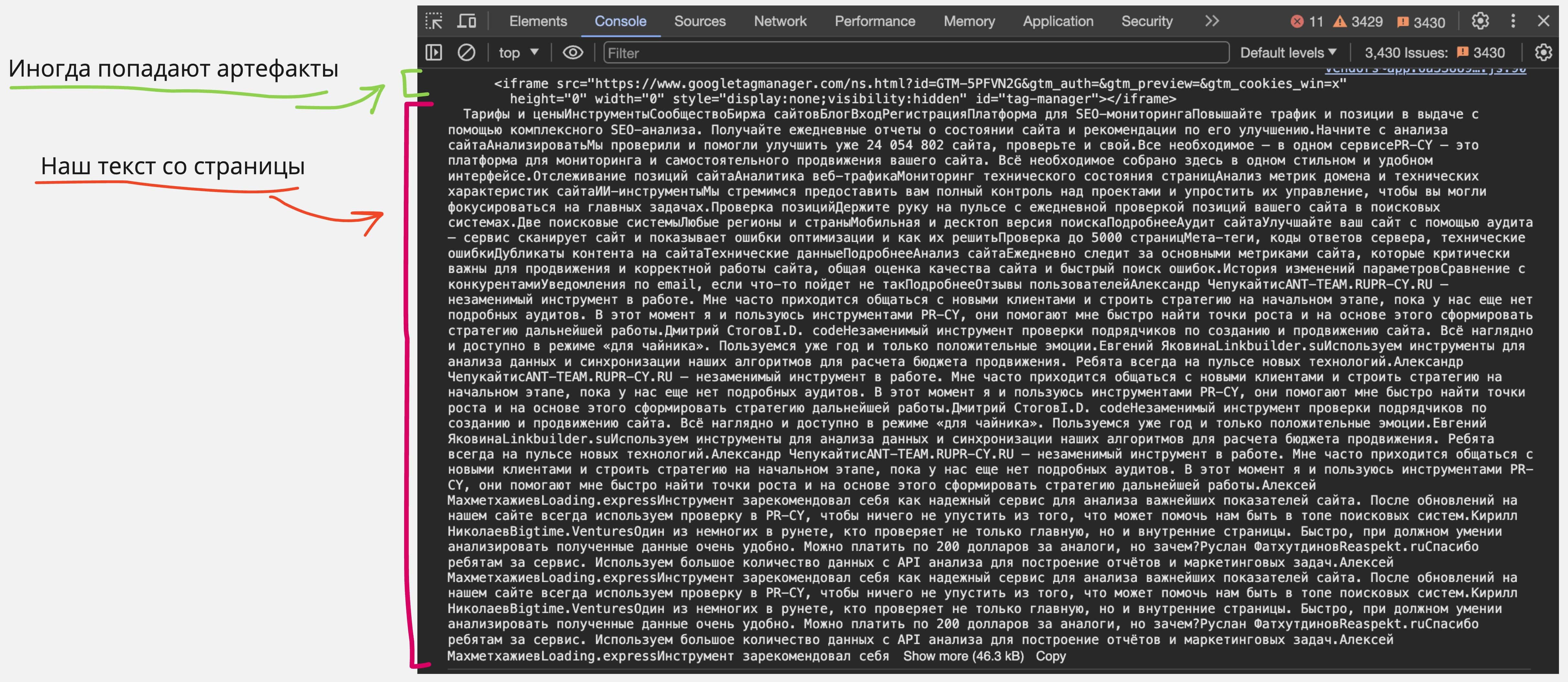
Сравниваем два HTML кода в любом онлайн-сервисе. Только будьте аккуратны, они сравнивают построчно. Любое изменение, даже точку, будут считать как добавленный/удаленный контент;
Используйте встроенную библиотеку python BeautifulSoup. Не будем вдаваться в подробности, так как эта тема отдельной статьи;
Различные расширения для браузеров, например SEO ALL STARS для Google Chrome. Единственный минус — многие расширения не умеют видеть текст под iframe. В любом случае, поэкспериментируйте.
Прохождение базовой аутентификации
Задача
Вы создали новый сайт или новую страницу, но она не доступна для пользователей и закрыта от посещений. Как протестировать такую страницу глазами Яндекса или Google?
Решение
cURL позволяет проходить базовую авторизацию на странице и получать любые данные, которые отдает сервер сайта.
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Параметр -u используется для указания учетных данных и говорит cURL, что страница с авторизацией.
Как это выглядит в терминале:

После того, как вы прошли базовую авторизацию и посмотрели страницу глазами Google, останется только сравнить полученный HTML от Google и в браузере и найти тот текст, который поисковик не видит. Для этого используйте инструкцию выше.
Получение HTTP-заголовков и отслеживание цепочки редиректов
Задача
Вы заходите на сайт и видите страницу с ответом сервера 200 OK. Пользователи жалуются, что по этой же странице у них открывается совсем другой контент или их перенаправляют в другое место. Вы хотите подтвердить жалобы пользователей и параллельно проверить ответы сервера и цепочки редиректов.
Решение
Шаг 1: проверяем, что видит Google
Такая ситуация может возникнуть, когда продакт-менеджер проводил сплит-тест и нечаянно добавил в него поисковых ботов или нецелевую аудиторию. Возможен вариант, когда сплит-тест отключили, а разработчики неверно поправили техническую часть. Из-за этого контент, ответы сервера и HTTP-заголовки могут выдаваться разные.
Вначале проверяем, нет ли лишних редиректов для бота Google и какие HTTP-заголовки ему возвращаются:
curl -sSL -D - -A "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" http://pr-cy.ru
Немного позже расшифруем все параметры в этом запросе.
Получаем следующий ответ, где видим HTTP-заголовки и цепочки редиректов:
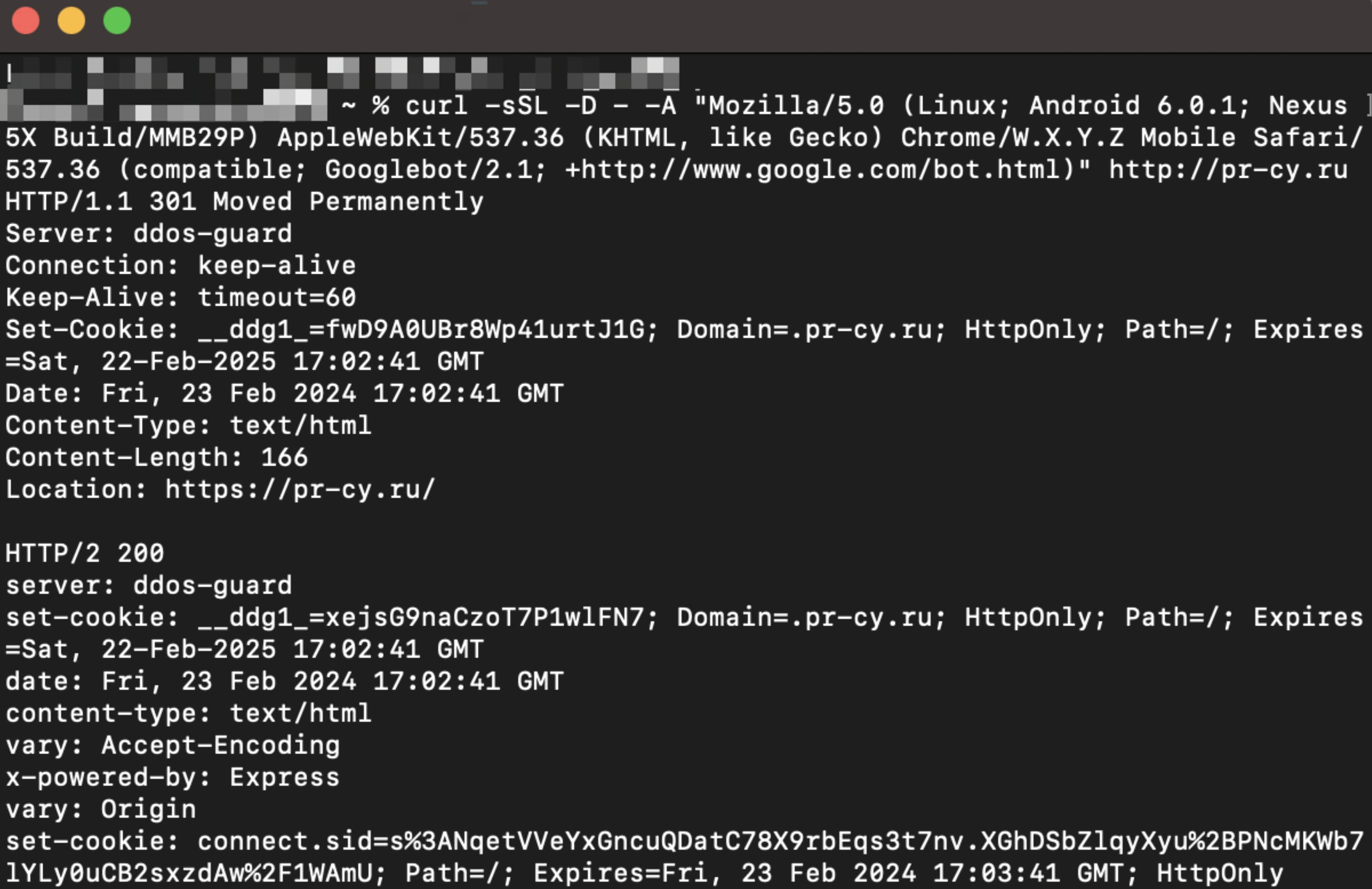
Видим, что для бота срабатывает один 301 редирект. Но это не из-за проблемы с сервером, а грамотно настроенные редиректы с HTTP на HTTPS. Запоминаем результат.
Шаг 2: проверяем, нет ли редиректов у пользователей, которые столкнулись с проблемами
После того как узнали эти данные, вводим в консоль следующий запрос:
curl -sSL -D - -H "User-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/105.0" -H "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8" -H "Accept-Language: en-US,en;q=0.5" http://pr-cy.ru
Получаем ответ, где видим HTTP-заголовки и цепочки редиректов, только уже для пользователя с проблемой. Теперь нужно сравнить ответы сервера для пользователей и ответы сервера для Google.
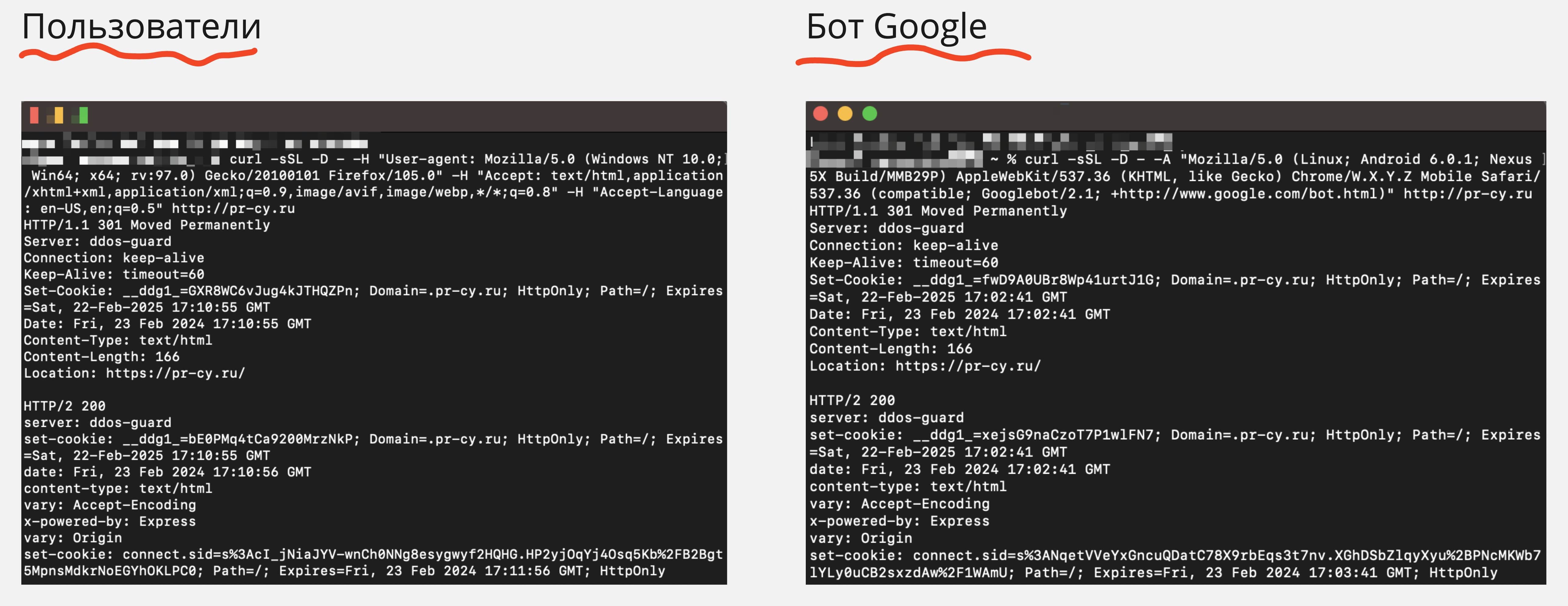
На скрине мы видим, что c HTTP-заголовками все в порядке и цепочки редиректов для пользователей и ботов одинаковые.
Параметры в запросе:
-s — этот флаг означает “тихий” режим и не выводит информацию в терминал о ходе процесса;
-S — этот флаг не выводит ошибки возникающие в процессе запроса, чтобы не засорять терминал;
-L — этот флаг позволяет cURL следовать редиректам в запросе и показывать всю цепочку;
-D – — этот флаг выводим заголовки HTTP headers в ответ терминала, и не записывает в файл;
-H – — этот флаг указывает на добавление заголовка к HTTP-запросу. Он позволяет уникализировать запрос и притвориться любым пользователем.
Резюмируем
cURL — простая программа, которая имеется по умолчанию практически на всех компьютерах Windows и MAC. Она позволяет делать HTTP-запросы к любому сайту и получить HTTP-заголовки и тело страницы.
Мы разобрали три основных ситуации, в которых SEO-специалист может использовать cURL:
Просмотреть страницы глазами поисковика независимо от того, работают ли официальные сервисы от Яндекса и Google;
Получить тело страницы, когда она находится под авторизацией и поисковые боты не могут на нее попасть;
Отследить, действительно ли вам, вашим пользователям и поисковым ботам отдаются одинаковые редиректы и HTTP-заголовки.
Использование командной строки и аргументов
Чтобы обратиться к программе в консоли (в терминале или в командной строке), достаточно просто ввести её имя: curl.
Но, к сожалению, команда без аргументов не даст абсолютно никакого результата. Максимум, отобразит подсказку о том, как вызвать помощь (справочный раздел).
Чтобы увидеть базовый список доступных аргументов, нужно ввести команду:
или для Windows:
Если вам нужен максимально полный обзор всех опций, введите команду:
curl –help all
Обратите внимание, аргументы можно указывать двумя способами:
- С одним тире, тогда обращение к ним будет коротким, например, «-h» будет равнозначно вводу «–help». Но «коротких» команд обычно немного, буквально с десяток.
- С двумя тире, тогда название параметра нужно указывать в полном написании, например, «–disallow-username-in-url».
Если использовать утилиту без аргументов, но с указанием URL-адреса, то это будет аналогом GET-запроса. Пример на пальцах:
Это то же самое, что и:
curl –request GET https://blog.froxy.com/ru/what-is-data-parsing
На всякий случай, cURL прекрасно работает с SSL-сертификатами (то есть с httpS-протоколом) и с другими типами запросов: PUT, POST, DELETE, HEAD.
В ответ на GET-запрос cURL получит полное содержимое HTML-страницы по указанному адресу.
Вот так будет выглядеть команда для работы cURL с HTTP-заголовками:
curl -I https://blog.froxy.com/ru/what-is-data-parsing
А так полученные данные можно сохранить в файл:
curl -o what-is-data-parsing.html “https://blog.froxy.com/ru/what-is-data-parsing”
Среди общего списка аргументов cURL есть:
- Средства для трассировки и отправки запросов.
- Тонкие настройки для управления SSL-сертификатами и методами авторизации.
- Средства для работы с загрузкой файлов, с cookies, с сессиями, с IP-протоколами и т.п.
- Средства для отправки данных.
- Запись данных в файлы (для сохранения полученной информации).
- Управление кодировками, временем и скоростью соединений.
- Детальная работа с прокси и туннелированием.
Как использовать cURL с Python
Существуют различные способы выполнения запросов с помощью curl в Python. В этой статье мы рассматриваем 2 варианта. Первый — имитировать запросы curl в командной строке через пакеты os и subprocess Python. Этот простой подход программно отправляет команды в интерфейс командной строки вашей ОС.
Второй вариант — использовать пакет PycURL. Если вы хотите узнать о других способах парсинга сайтов с помощью Python (без использования curl), ознакомьтесь с нашей статьей “Скрапинг веб-сайтов на Python — пошаговое руководство“
Требования
Прежде чем приступить к работе, убедитесь, что вы загрузили и установили curl. Если вы используете Windows, обязательно добавьте curl в переменную среды PATH, чтобы вы могли просто выполнить команду curl.
Чтобы создать интерфейс Python с вашей ОС, вы можете использовать различные пакеты. Однако двумя наиболее популярными являются os и subprocess. Чтобы установить их, выполните следующую команду pip:
pip install os subprocessСоздание запроса с помощью curl и os
Пакет os — максимально простой пакет. Выполнение запроса curl без обработки ответа занимает всего две строки кода. Вам просто нужно передать файл cookie, описанный в предыдущем примере, и результат будет записан в файл output.txt:
import os
os.system('curl -o output.txt --cookie "greeting=hello" -k https://curl.se')Если вы хотите обработать ответ в Python, а не записывать его в файл, вам следует использовать пакет subprocess, о котором мы расскажем в следующем разделе.
Следующий код выполняет тот же оператор, но вместо записи ответа в файл выводит stdout и stderr в виде кортежа. Затем этот вывод можно обработать с помощью других пакетов Python, таких, как Beautiful Soup:
import shlex
import subprocess
shell_cmd = shlex.split('curl --cookie "greeting=hello" -k https://curl.se')
process = subprocess.Popen(shell_cmd, stdout = subprocess.PIPE, stderr = subprocess.PIPE, text = True, shell = True )
std_out, std_err = process.communicate()
std_out.strip(), std_errИспользование PycURL
Вместо взаимодействия с вашим терминалом на Python вы можете использовать пакет PycURL. Если вы пользователь Linux, вам повезло, поскольку вы можете установить PycURL с помощью pip:
pip install pycurl
pip install certifiВам нужно установить certifi для взаимодействия по протоколу HTTPS. Если у вас возникнут проблемы, следуйте этим инструкциям из Stack Overflow.
Хотя PycURL также можно установить и на Windows, это очень неприятное занятие. Если вы попытаетесь установить его через pip, он выдаст ошибку:
Please specify --curl-dir=/path/to/built/libcurlПоэтому вам нужно установить его из исходного кода, что “не для слабонервных из-за множества возможных зависимостей, каждая из которых имеет свою структуру каталогов, стиль конфигурации, параметры и особенности”.
Рекомендуем придерживаться пакета requests для основных сетевых запросов, если вы работаете на Windows.
Использование переменных окружения
Что интересно, cURL поддерживает функции подстановки и перестановки.
Например, можно использовать такой синтаксис:
Данные, записанные в фигурных скобках через запятую, будут последовательно перебираться скриптом.
Если нужно обозначить диапазон числовых значений, можно задействовать квадратные скобки, например, так:
Начиная с версии cURL 8.3 в утилиту добавлена поддержка переменных. Создание переменных реализовано через атрибут –variable.
–expand-url = “https://example.com/api//method”
Крайне важно задействовать именно двойные кавычки, так как одинарные не поддерживают работу с переменными (они будут восприниматься как обычный текст).
В приведённом выше примере мы сначала объявили переменную DATA и сразу же присвоили ей дефолтное значение default (значение по умолчанию будет использовано утилитой в случае, если переменная будет пустой на момент обращения к ней).
Обращение к переменной выполняется с помощью конструкции .
Плюс, при работе cURL можно задействовать переменные, которые объявляются на уровне оболочки (в shell-скриптах). Тут тоже главное не забыть о двойных кавычках:
your-variable = XXX
Как создавать запросы с PycURL
Следующая часть статьи будет посвящена созданию различных типов запросов с помощью пакета PycURL.
Создание запроса GET с помощью PycURL
Самый простой запрос, который вы можете сделать с помощью PycURL, — это запрос GET. По сути, это шаблон для всех других шаблонов в данном разделе.
В следующем коде можно выделить 5 шагов:
- Импорт всех необходимых пакетов
- Создание 2-х объектов: буфер, в котором запрос curl будет хранить свой ответ, и объект curl, который используется для выполнения запроса.
- Введение параметров запроса: URL-адрес, пункт назначения и проверка SSL.
- Выполнение запроса.
- Результат выполнения запроса.
# Preparation
import pycurl
import certifi
from io import BytesIO
# Set buffer and Curl object.
buffer = BytesIO()
c = pycurl.Curl()
# Set request options.
## Set the request destination.
c.setopt(c.URL, 'http://pycurl.io/')
## Set the buffer as the destination of the request's response.
c.setopt(c.WRITEDATA, buffer)
## Refer to the installed certificate authority bundle for validating the SSL certificate.
c.setopt(c.CAINFO, certifi.where())
# Execute and close the request.
c.perform()
c.close()
# Print the buffer's content with a Latin1 (iso-8859-1) encoding.
body = buffer.getvalue()
data = body.decode('iso-8859-1')
print(data)Выполнение POST-запроса с помощью PycURL
Выполнение запроса POST с помощью PycURL схоже с выполнением запроса GET. Однако к нему добавляется дополнительная опция: тело POST. В следующем фрагменте кода задается ключевое значение и кодировка URL для обеспечения адекватной обработки:
# Preparation
import pycurl
import certifi
from io import BytesIO
# Set buffer and Curl object.
buffer = BytesIO()
c = pycurl.Curl()
# Set request options.
## Set the request destination.
c.setopt(c.URL, 'http://pycurl.io/')
## Set the request's body.
post_body = {'greeting': 'hello'}
postfields = urlencode(post_body)
c.setopt(c.POSTFIELDS, postfields)
## Set the buffer as the destination of the request's response.
c.setopt(c.WRITEDATA, buffer)
## Refer to the installed certificate authority bundle for validating the SSL certificate.
c.setopt(c.CAINFO, certifi.where())
# Execute and close the request.
c.perform()
c.close()
# Print the buffer's content with a Latin1 (iso-8859-1) encoding.
body = buffer.getvalue()
print(body.decode('iso-8859-1'))Выполнение запроса PUT с PycURL
Запрос POST, который вы создали в предыдущем разделе, также можно отправить как запрос PUT. Вместо того чтобы отправлять ключевое значение в теле запроса, вы отправите его в виде представления файла, закодированного в UTF-8. Этот метод также можно использовать для загрузки файлов:
import pycurl
import certifi
from io import BytesIO
c = pycurl.Curl()
# Set request options.
## Set the request destination.
c.setopt(c.URL, 'http://pycurl.io/')
## Set data for the PUT request.
c.setopt(c.UPLOAD, 1)
data = '{"greeting": "hello"}'
buffer = BytesIO(data.encode('utf-8'))
c.setopt(c.READDATA, buffer)
## Refer to the installed certificate authority bundle for validating the SSL certificate.
c.setopt(c.CAINFO, certifi.where())
# Execute and close the request.
c.perform()
c.close()Загрузка файла с помощью PycURL
Следующий фрагмент демонстрирует, как можно загрузить файл с помощью PycURL. Запрашивается случайное изображение в формате JPEG, открывается поток записи на some_image.jpg и передается в PycURL в качестве места назначения для файла:
import pycurl
import certifi
c = pycurl.Curl()
# Set the request destination.
c.setopt(c.URL, 'http://pycurl.io/some_image.jpg')
# Refer to the installed certificate authority bundle for validating the SSL certificate.
c.setopt(c.CAINFO, certifi.where())
# Execute and close the request.
with open('some_image.jpg', 'w') as f: c.setopt(c.WRITEFUNCTION, f.write) c.perform()
c.close()Загрузка и обработка веб-страницы с помощью PycURL
Поскольку многие случаи использования PycURL связаны с парсингом веб-страниц, далее описывается, как вы можете обрабатывать ответ на запрос с помощью Beautiful Soup, популярного пакета для анализа HTML-файлов.
Для начала установите Beautiful Soup 4 с помощью pip:
pip install beautifulsoup4Затем поместите следующий сниппет сразу после первого фрагмента PycURL, который сделал запрос GET. Это заставит Beautiful Soup обработать данные ответа.
Для демонстрации используется метод find_all, чтобы найти все элементы параграфа, и вывести содержимое отдельных параграфов:
from bs4 import BeautifulSoup
# Parsing data using BeautifulSoup
soup = BeautifulSoup(data, 'html.parser')
# Find all paragraphs
paragraphs = soup.find_all('p')
for p in paragraphs: print(p.text)Использование прокси с PycURL
Масштабный веб-скрапинг лучше всего работает, когда вы используете прокси. Преимущество заключается в том, что вы можете параллельно имитировать поведение пользователей в браузере, при этом ваш парсер не будет отмечен как бот или с аномальным поведением.
В заключительном разделе вы узнаете, как создать запрос с PycURL через прокси. Для этого нужны настройки параметров запроса, как вы делали это ранее. Мы представляем 4 настройки, однако вы можете настроить их под свою ситуацию:
- Для облегчения задачи включены небезопасные прокси.
- Прокси настроен.
- Скрипт аутентифицируется на сервере.
- Прокси устанавливается как
HTTPS.
# Enable insecure proxies
c.setopt(c.PROXY_SSL_VERIFYHOST, 0)
c.setopt(c.PROXY_SSL_VERIFYPEER, 0)
# Set proxy server
c.setopt(pycurl.PROXY, <YOUR_HTTPS_PROXY_SERVER>)
# Authenticate with the proxy server
c.setopt(pycurl.PROXYUSERPWD, f"{<YOUR_USERNAME>}:{<YOUR_PASSWORD>}")
# Set proxy type to https
c.setopt(pycurl.PROXYTYPE, 2)Эти параметры можно вставить в любом месте ранее описанного фрагмента кода, чтобы запрос перенаправлялся через прокси-сервер.
Настройка cURL для постоянной работы через прокси
Для работы с прокси в cURL используется атрибут «» или «».
Но согласитесь, что каждый раз вводить одни и те же данные не очень удобно. А что, если данные прокси вообще каждый раз меняются?
Для этих ситуаций есть несколько типовых решений. О них ниже.
Прокси для cURL в переменных
Если нет задачи полного перебора списка с прокси-серверами, то можно обойтись максимально простой записью.
Так мы создали переменную и заполнили её значением.
Осталось вызывать переменную там, где это нужно. В случае с прокси это может выглядеть так:
curl -x $yourproxy https://blog.froxy.com/ru/what-is-data-parsing
Вариант с перебором списка прокси будет заметно сложнее – см. раздел выше про использование переменных окружения.
Ну или вместо атрибута «» или «» можно использовать специальные атрибуты:
Синтаксис у них аналогичный.
Прокси в псевдонимах (алиасах)
Теперь представим, что вам нужно работать с командной строкой, но не хочется каждый раз вводить параметры коннекта cURL к одному и тому же прокси-серверу.
Наиболее интересный выход для такой рутины – создание ссылки (алиаса или псевдонима). Выполняется это командой alias (в Linux-системах).
Пример ярлыка с готовыми параметрами подключения прокси:
Теперь, чтобы выполнить запрос к нужному сайту или задействовать иные параметры утилиты, вместо стандартного вызова curl достаточно обратиться к нашему алиасу:
Вместо xcurl вы можете использовать любое другое имя, главное, чтобы оно не совпадало с именами других системных утилит и легко запоминалось/вводилось в терминале.
В Windows тоже есть команда alias, но работает она совсем по-другому. Чтобы создать ярлык для новой команды, нужно будет поработать с реестром и с .bat/.cmd файлами.
Использование файла .curlrc
Все настройки утилиты cURL, которые связаны с конкретным пользователем, сохраняются в его домашнем каталоге:
Обратите внимание, точка в начале файла говорит о том, что он является скрытым. Чтобы отобразить его в проводнике (файловом менеджере), нужно активировать опцию показа скрытых файлов.
Ну, или можно напрямую обратиться к редактированию конфига через командную строку:
Nano – это текстовый редактор для консоли, вместо него можно использовать софт с графическим интерфейсом, например, Gedit.
Если файл не существует, просто создайте его (фактически, команда, приведённая выше для консоли, никак не изменится).
Впишите настройку прокси в файл и сохраните его:
Готово, теперь можно использовать cURL как обычно, параметры прокси будут подтягиваться по умолчанию:
Зачем использовать curl с Python?
Несмотря на то, что curl является универсальным инструментом, все же есть одна основная причина, по которой вы захотите использовать его с Python: Python может автоматизировать ваши запросы. Представляем 3 случая, когда эта комбинация является полезной:
Веб-скрапинг
Веб-скрапинг — это практика сбора (часто больших) объемов данных с одной или нескольких веб-страниц. Чтобы собрать данные с помощью Python, люди часто используют библиотеку requests. Для рекурсивного парсинга вы можете использовать wget. Однако для продвинутых случаев парсинга со сложными вызовами HTTP(S) идеально подходит curl с Python.
Хотя данные с веб-страницы можно собрать с помощью одной команды curl, которая генерирует и обрабатывает запрос HTTP(S), она не может делать это рекурсивно. Встраивая curl в код Python, вы можете имитировать путь навигации по сайту, манипулируя такими элементами, как параметры запроса, cookie и пользовательские агенты.
Навигацию даже не нужно исправлять. За счет того, что он зависит от соскобленного содержимого, каждый новый запрос может быть полностью динамичным.
Тестирование и отладка
Использование curl на собственном сайте кажется глупым, но оно полезно в контексте тестирования и отладки. Дело в том, что тестирование или отладка одной, или нескольких функций приложения часто является трудоемкой задачей. Его необходимо тестировать периодически и с различными настройками или параметрами. Несмотря на то, что существует множество готовых инструментов для тестирования, Python и curl упрощают настройку некоторых быстрых тестов.
Например, если вы выпускаете новый процесс оформления заказа для своего (сложного) онлайн-сервиса, который использует файлы cookie, полагается на реферер, имеет незначительные различия для каждого браузера (т.е. пользовательский агент) и упаковывает все этапы процесса оформления заказа в тело POST-запроса, ручное тестирование может занять вечность. В Python вы можете создать словарь со всем набором параметров и отправить запрос с помощью curl для каждой возможной комбинации.
Автоматизация рабочего процесса
Помимо тестирования, отладки и просмотра веб-страниц, curl можно использовать для автоматизации рабочих процессов. Например, многие конвейеры интеграции данных начинаются с повторяющегося дампа экспорта данных, такого как файл CSV или Apache Parquet. С приложением Python, которое опрашивает новые файлы на (S)FTP-сервере, копирование дампов данных можно быть полностью автоматизировано.
Или рассмотрите настройку почтовых ящиков. Представьте, сколько ежедневных задач можно было бы автоматизировать, если бы приложение могло опрашивать сообщения электронной почты, содержащие запрос. Опрашивая новые сообщения по протоколу POP3 или IMAP, приложения Python могут запускаться, когда почтовый ящик получает определенное электронное письмо.
Установка cURL
Во всех последних версиях операционных систем Windows, начиная со сборки 1803 (Windows 10) и выше, есть встроенный клиент cURL. Но тут есть нюансы. Системное решение работает как командлет Invoke-WebRequest. Соответственно, предполагается использование изменённого синтаксиса, вследствие чего будут недоступны многие параметры командной строки.
Поэтому, если вы хотите использовать стандартный интерфейс cURL, нужно выбрать одно из нескольких решений:
- Прямое обращение к файлу curl.exe (при желании можно скачать актуальную версию сборки cURL для Windows с официального сайта утилиты).
- Установка окружения WSL (Windows Subsystem Linux). Фактически это специализированная виртуальная машина.
- Ручная установка любого Linux-дистрибутива в среде виртуализации (VirtualBox и аналоги).
Установка cURL в большинстве случаев не потребуется. Во всех популярных дистрибутивах связка из библиотеки и утилиты есть в наличии.
Если при вызове команды curl в терминале система ругается на отсутствующий исполняемый файл, то можно установить программу с помощью штатного пакетного менеджера, например:
- Для дистрибутивов на базе Debian/Ubuntu – sudo apt-get install curl
- Для дистрибутивов на базе Fedora/CentOS/RHEL – yum install curl
- Для дистрибутивов на базе ArchLinux – pacman -Sy curl
cURL установлена во всех Mac OS по умолчанию. Чтобы начать использование утилиты, просто откройте приложение «Терминал» и начните вводить команды.
Подведем итог
В этой статье мы подробно рассказали о комбинации curl и Python, а также показали, почему следует использовать их вместе для генерации сложных запросов для веб-скрапинга и тестирования приложений. Вы увидели несколько примеров, демонстрирующих универсальность PycURL для создания множества сетевых запросов.
В качестве альтернативы вы можете использовать прокси-сеть Bright Data и IDE веб-парсера, которая была разработана специально для выполнения всей тяжелой работы разработчиков. Таким образом, вы можете сосредоточиться на работе с полученными данными, а не беспокоиться о том, как обойти механизмы защиты от парсинга.
Кредитная карта не требуется
Выводы и рекомендации
С библиотекой cURL бесшовно интегрируются многие языки веб-программирования. Пример документации для PHP. Поэтому скрипты автоматизации парсинга смогут заиграть новыми красками буквально в несколько дополнительных строк кода.
Вместе с тем, обывателям cURL точно не подойдёт ввиду сложности синтаксиса и тяжёлого понимания принципов работы.


