

Хранилище данных – компьютерная технология, которая не является количественной величиной СИ. Компьютерная информация представлена в числовых формах «1» и «0» в различных типах хранилищ. Главной единицей хранения цифровых данных является байт, а в байте 8 бит. Виртуальные данные измеряются в таких единицах, как бит, байт, килобайт (КБ), мегабайт (МБ), гигабайт (ГБ), терабайт (ТБ), петабайт или эксабайт.
Конвертер единиц цифрового Хранилища данных.
Добрый день!
Изучая лекцию “Нюансы работы с вещественными числами” первого квеста (раздел 2. Устройство чисел с плавающей точкой) и дополнительные лекции по теме, многие, должно быть, столкнулись со множеством вопросов на эту тему. Изначально я постаралась дать сама себе необходимые ответы, а теперь предлагаю их вам в помощь для полноценного понимания в последовательном логическом порядке.
1. Десятичные и двоичные системы счисления.
1.1 Десятичная система счисления — одна из наиболее распространённых систем, именно ей мы пользуемся при любых НЕ компьютерных математических вычислениях в школе, в вузе, в жизни. В ней используются цифры 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 (арабские) – всего 10 цифр. Также есть римская запись чисел, которая, однако, практически не применяется сейчас.
В десятичной системе счет ведется единицами, десятками, сотнями, тысячами, десятками тысяч, сотнями тысяч, миллионами и т.д. – иными словами, это все разряды числа. Разряд числа – это
(место) цифры в записи числа. Самый младший разряд натуральных чисел (и самый малозначимый) – это разряд единиц (самый правый). Почему он самый малозначимый? Потому что, отбросив единичный разряд числа, само число изменится минимально( например, числа 345 и 340). Далее второй разряд – это разряд десятков и т.д.
Что это все значит? Возьмем любое целое число в десятичной системе и разложим его на разряды.
3297 = 3*1000 + 2*100 + 9*10 + 7
Таким образом получаем, что в числе 3297 содержится 3 единицы четвертого разряда (то есть 3 тысячи), 2 единицы третьего разряда (2 сотни), 9 единиц второго разряда (9 десятков) и 7 единиц первого разряда. Иными словами, это число три тысячи двести девяносто семь и оно является, соответственно,
.
А что же с разрядами дробных (вещественных) чисел? Разряды дробных чисел (их дробной части) называются: десятые, сотые, тысячные, десятитысячные и т.д. Чем дальше от запятой (от целой части числа) разряд – тем он менее значим (отбросив его, значение числа мало поменяется). Для примера возьмем любое дробное число, представленное в виде десятичной дроби:
25,076 = 2*10 + 5 +0*0,1 + 7*0,01 +6*0,001
Таким образом, получаем, что в дробном числе 25,076 содержится 2 десятка, 5 единиц, 0 десятых, 7 сотых и 6 тысячных.
В десятичной системе используются 10 цифр и кратные 10-и разряды – отсюда и название “десятичная”.
1.2
Двоичная система счисленияхранятся совсем по-другому
– об этом будет рассказано далее. А пока давайте научимся переводить числа из одной системы счисления в другую.
2. Перевод целых и дробных чисел из десятичной системы в двоичную и наоборот.2.1 Перевод из десятичной системы в двоичную.
2.1.1 Целые числа.
Для того, чтобы перевести целое десятичное число в двоичную систему счисления, необходимо разделить это число на 2, записать остаток от деления (он всегда равен 0 или 1, в зависимости от того, четное число или нечетное), а результат деления снова поделить на 2, снова записать остаток от деления (0 или 1), а результат от второго деления снова поделить на 2. Так продолжать до тех пор, пока результат деления не станет равным единице. Далее запишем все полученные нули и единицы в обратном порядке, начиная с самого последнего результата деления, всегда равного 1.
Важное примечание. Конечным результатом последовательного деления ЛЮБОГО ЦЕЛОГО ЧИСЛА на 2 всегда в итоге будет единица
! Если результат больше 1 – мы продолжаем делить этот результат на 2,пока не получим единиц в результате. А нулем (0) результат деления на 2 может быть только в единственном случае – это деление самого нуля на 2.
Пример.
Переведем число 145 из десятичной системы в двоичную.
145/2 = 72 (остаток 1)
72/2 = 36 (остаток 0)
36/2 = 18 (остаток 0)
18/2 = 9 (остаток 0)
9/2 = 4 (остаток 1)
4/2 = 2 (остаток 0)
2/2 = 1 (остаток 0)
Теперь “собираем” наше двоичное число в обратном порядке. Получаем число 10010001. Готово!
Интересный нюанс 1. Переведем число 1 из десятичной системы в двоичную. В двоичной системе это число также будет записано как 1. Ведь конечный результат деления на 2, который должен быть равен 1, уже равен самому числу 1.
1₁₀ = 1₂
Интересный нюанс 2. Переведем число 0 из десятичной системы в двоичную. В двоичной системе это число также будет записано как 0.
0₁₀ = 0₂
2.1.2 Дробные числа.
А как перевести дробные числа в двоичную систему?
Чтобы перевести десятичную дробь в двоичную систему счисления, необходимо:
а)
целую часть дроби
перевести в двоичную систему согласно изученному алгоритму в пункте 2.1.1
б)
дробную часть дроби
умножить на 2, записать полученную цифру результата ДО запятой (всегда равна 0 или 1, что логично), далее ТОЛЬКО дробную часть полученного результата снова умножить на 2, снова записать полученную цифру результата ДО запятой (0 или 1) и так далее, пока дробная часть результата умножения не станет равна 0 или до требуемого количества знаков после запятой (требуемой точности) (равно количеству умножений на 2).
Затем необходимо записать полученную последовательность записанных нулей и единиц ПО ПОРЯДКУ после точки, разделяющей целую и дробную части вещественного (дробного) числа.
Пример 1.
Переведем число 2.25 (2 целых 25 сотых) из десятичной системы в двоичную. В двоичной системе дробь будет равна 10.01. Как мы это получили?
Число состоит из целой части ( до точки) – это 2 и дробной части – это 0.25.
1) Перевод целой части:
2/2 = 1 (остаток 0)
Целая часть будет 10.
2)Перевод дробной части.
0.25 * 2 = 0.5 (0)
0.5 * 2 = 1.0
Дробная часть стала в результате последовательного умножения на 2 стала равна 0. Прекращаем умножение.
Теперь “собираем” дробную часть ПО ПОРЯДКУ – получаем 0.01 в двоичной системе.
3)Складываем целую и дробную части – получаем, что десятичная дробь 2.25 будет равна двоичной дроби 10.01.
Пример 2.
Переведем число 0.116 из десятичной системы в двоичную.
0.116 * 2 = 0.232 (0)
0.232 * 2 = 0.464 (0)
0.464 * 2 = 0.928 (0)
0.928 * 2 = 1.856
//отбрасываем целую часть данного результата
0.856 * 2 = 1.712
//отбрасываем целую часть данного результата
0.712 * 2 = 1.424
//отбрасываем целую часть данного результата
0.424 * 2 = 0.848 (0)
Как мы видим, умножение продолжается и продолжается, дробная часть результат никак не становится равной 0. Тогда решим, что мы переведем нашу десятичную дробь в двоичную с точностью до 7 знаков (бит) после точки (в дробной части). Вспоминаем, что мы же изучали про малозначимые разряды – чем дальше разряд (бит) от целой части, тем легче мы можем им пренебречь (объяснение в разделе 1 лекции, кто забыл).
Получаем двоичную дробь 0.0001110 с точностью до 7 бит после точки.
2.2.1 Целые числа.
Для того, чтобы перевести целое число из двоичной системы счисления в десятичную, необходимо разбить это число на разряды (биты) и каждый разряд (бит) умножить на число 2 в определенной положительной степени ( данная степень начинает отсчет справа налево от самого младшего (правого бита) и начинается с 0).
Иными словами, степень двойки равна номеру данного бита (но это негласное правило можно использовать только в случае перевода целых чисел, так как у дробных чисел нумерация битов начинается в дробной части, которая переводится в десятичную систему по-другому).
Далее нужно сложить полученные произведения.
Пример.
Переведем двоичное число 110011 в десятичную систему счисления.
110011₂ = 1*2⁵ + 1*2⁴ + 0*2³ + 0*2² + 1*2¹ + 1*2º = 32 +16 +0 + 0 + 2 + 1 = 51₁₀
В итоге получаем число 51 в двоичной системе.
Для информации, ниже приведена таблица первых степеней числа 2.

! Обратите внимание, нулевая степень числа всегда равна 1.
2.2.2 Дробные числа.
Для того, чтобы перевести двоичное дробное (вещественное) число в десятичное, необходимо:
а) перевести его целую часть в десятичную согласно алгоритму из пункта 2.2.1;
б) перевести его дробную часть следующим образом. Нужно представить дробную часть в виде суммы произведений разрядов на двойку, возведенную в определенную отрицательную степень (степень для первого разряда после точки(после целой части дроби) будет равна -1, для второго разряда после точки равна -2 и т.д.) Результат данной суммы и будет дробной частью числа в десятичной системе.
Пример.
Переведем число 10111.01 в двоичную систему.
10111.01₂ = (1*2⁴ + 0*2³ + 0*2² + 1*2¹ + 1*2º) . (0*2ˉ¹ + 1*2ˉ²) = (16 + 0 + 4 + 2 + 1) . (0 + 0.25) = 23.25₁₀
В итоге получаем число 23.25 в десятичной системе счисления.
Таблица первых отрицательных степеней 2 приведена ниже.

2.2.3 Общая формула перевода чисел из двоичной системы в десятичную.
Приведем общую формулу перевода чисел из двоичной системы в десятичную (и целой, и дробной частей).

В памяти компьютера типы float и double ( вещественные типы с плавающей точкой) хранятся в экспоненциальном нормализованном виде, но основанием степени выбрано число 2 вместо 10. Это связано с тем, что, как сказано выше, все данные в компьютере представлены в двоичной форме (битами). Под число отводится определённое количество компьютерной памяти.
Представим положительное число 15.2 в нормализованном экспоненциальном виде:
1.52*10¹.
Далее представим его двоичного “близнеца” 1111.00110011001 также в экспоненциальной нормализованной форме записи, пользуясь тем же самым алгоритмом:
1)Основание будет равно 2
2) Мантисса будет равна 1.11100110011001
3)Степень будет положительной и равна 3 (смещение точки на 3 бита влево) в десятичной системе. Переведем ее в двоичную систему: 11.
Таким образом, в двоичном экспоненциальном нормализованном виде это будет число
1.11100110011001 * 2¹¹.4.3 Хранение экспоненциальной нормализованной двоичной формы числа float в памяти компьютера.
Итак, мы разобрались, что вещественное число будет храниться в памяти компьютера в экспоненциальной нормализованной двоичной форме.
Как же оно будет выглядеть в памяти?
Возьмем тип float. Под каждое число типа float компьютер выделяет 32 бита. Они распределяются следующим образом.
На данном рисунке схематично представлена выделенная память для числа типа float размером в 32 бита в компьютере.

Чтобы не тратить бит на определение знака степени, у чисел float прибавляютсмещение к экспоненте в половину байта +127(0111 1111).
Таким образом, вместо диапазона степеней от 2ˉ¹²⁷ до 2¹²⁷, компьютер хранит диапазон степеней от 0 до +254 – все значения степеней положительны, лишний байт на знак тратить не надо.
Получается, что величина показателя степени смещена наполовину относительно возможного значения.
Это значит, что для получения фактического значения степени экспоненты необходимо вычесть это смещение из хранящегося в памяти значения. Если сохраненное в памяти значение степени экспоненты меньше смещения (+127), значит степень экспоненты отрицательная: это логично.
Пример.
Выполним смещение отрицательной степени -18. Прибавляем к ней смещение +127, получаем значение степени +108 (не забываем степень 0 в расчете). Переведем степень в двоичный вид:
1101100
Но на степень же выделено 8 бит памяти, а тут мы получаем 7-ми битное число. На место пустого, незанятого старшего разряда (бита) компьютер добавляет 0.
Итог данная степень будет храниться в памяти компьютера в виде 01101100.
Смотрим: +108 < +127, значит, степень действительно по факту отрицательная.
Рассмотрим следующую интересную таблицу:

В ней приведены все возможные значения степеней нормализованных форм чисел float в двоичной и десятичной системах. Как мы видим, в двоичной системе +127 как раз составляет половину целого байта (8 бит).
3) Оставшиеся 23 бита отводят для мантиссы.
Но у нормализованной двоичной мантиссы старший бит (он же целая часть нормализованной мантиссы) всегда равен 1 (называется неявная единица), так как число мантиссы лежит в диапазоне 1<=M<2 (а также вспоминаем пункт 2.1.1 лекции). Единственное исключение – число 0.
Нет смысла записывать единицу в отведенные 23 бита и тратить память, поэтому в отведенные 23 бита записывают остаток от мантиссы (ее дробную часть). Выходит, что по сути значащая часть числа float имеет длину 24, из которых хранится на один бит меньше.
Важный нюанс. Вспомним, что при переводе десятичных дробных чисел в двоичные часто дробная часть в двоичной системе получалась огромной. А у нас всего лишь 32 бита на хранение числа float.
В данном случае самые младшие, малозначимые разряды двоичной дроби (вспоминаем пункт 2.1.2 данной лекции) не войдут в выделенную память и компьютер ими пренебрежет. Точность числа потеряется, но, согласитесь, минимально.
Иными словами, точность дробных чисел типа float составляет 6-7 десятичных знаков.4.4 Хранение экспоненциальной нормализованной двоичной формы числа double в памяти компьютера.
Хранение вещественных чисел типа double осуществляется в памяти компьютера таким же образом, как и у чисел float, за исключением некоторых характеристик.
На число типа double в памяти компьютера отведено 64 бита. Они распределяются следующим образом (также по порядку слева направо):
1) Знаковый бит (см. пункт 4.3). Мы понимаем, что номер этого бита будет 63.
2)Степень (порядок). На ее хранение у чисел double выделяется 11 бит. Также осуществляется смещение степени, но у чисел double оно будет равно +1023.3)Мантисса (значащая часть). На ее хранение у чисел double выделяется 52 бита (разряда). Также точно целая часть мантиссы (неявная единица) в памяти не хранится.
Также стоит отметить, что точность дробных чисел типа double составляет около 16 десятичных знаков.
4.5 Примеры представления вещественного числа десятичной системы в памяти компьютера.
И завершающим пунктом нашей лекции будет пример перевода дробного числа десятичной системы счисления в форму его хранения в памяти компьютера для закрепления понимания темы.
Пример 1.
Возьмем число -4.25 типа float.
Представим его в экспоненциальном нормализованном виде в двоичной системе счисления, вспоминая все, что проходили в этой лекции.
1) Переводим целую часть числа в двоичную форму:
4/2= 2 (остаток от деления 0)
2/2 = 1 (остаток от деления 0)
Целая часть будет равна 100 в двоичной системе.
2)Переводим дробную часть числа в двоичную форму.
0.25*2 = 0.5 (0)
0.5*2 = 1.0
Дробная часть будет равна 0.01 в двоичной системе.
3) Таким образом, -4.25₁₀ = -100.01₂.
4) Переведем число -100.01₂ в экспоненциальный нормализованный вид в двоичной системе счисления (значит, основание степени будет 2).
-100.01₂ = -1.0001 *2²
Переведем значение степени из десятичного формата в двоичный.
2/2=1 (остаток 0)
Степень равна 10₂.
Получаем, что число -4.25₁₀ в своей двоичной экспоненциальной нормализованной форме будет равно -1.0001 * 2¹º
Запишем, как это будет выглядеть в памяти компьютера. Знаковый бит будет равен 1 (число отрицательное).
Смещение экспоненты равно 2+127 = 129₁₀ = 10000001₂
У мантиссы откидываем неявную единицу, получаем 00010000000000000000000 ( незанятые младшие биты заполняем нулями
).
Итог. 1 10000001 00010000000000000000000 – вот таким образом число -4.25 хранится в памяти компьютера.
Пример 2.
Переведите число 0.75₁₀ типа float в двоичный формат хранения в памяти компьютера.
Результат должен быть 0 01111110 10000000000000000000000.
Благодарю за внимание.
Обстоятельно о подсчёте единичных битов
Время на прочтение
Я хотел бы подарить сообществу Хабра статью, в которой стараюсь дать достаточно полное описание подходов к алгоритмам подсчёта единичных битов в переменных размером от 8 до 64 битов. Эти алгоритмы относятся к разделу так называемой «битовой магии» или «битовой алхимии», которая завораживает своей красотой и неочевидностью многих программистов. Я хочу показать, что в основах этой алхимии нет ничего сложного, и вы даже сможете разработать собственные методы подсчёта единичных битов, познакомившись с фундаментальными приёмами, составляющими подобные алгоритмы.
Прежде чем мы начнём, я сразу хочу предупредить, что это статья не для новичков в программировании. Мне необходимо, чтобы читатель в общих чертах представлял себе простейшие битовые операции (побитовое «и», «или», сдвиг), хорошо владел шестнадцатеричной системой счисления и достаточно уверенно пользовался воображением, представляя в нём не всегда короткие битовые последовательности. По возможности, всё будет сопровождаться картинками, но сами понимаете, они лишь упрощают, но не заменяют полное представление.
Среди читателей, возможно, будут такие, кому проще посмотреть всё то же самое на видео. Я записал такое видео (58 минут), в котором в формате презентации изложено в точности всё то же самое, что будет ниже по тексту, но может немного в другом стиле, более сухо и строго, тогда как текст я попытался немного оживить. Поэтому изучайте материал так, как кому удобнее.
Сейчас будут последовательно описаны алгоритмы, порождаемые тем или иным набором алхимических приёмов, в каждом разделе будет таблица сравнения времени работы для переменных разного размера, а в конце будет сводная таблица по всем алгоритмам. Во всех алгоритмах используются псевдонимы для чисел без знака от 8 до 64 бит.
typedef unsigned char u8;
typedef unsigned short int u16;
typedef unsigned int u32;
typedef unsigned long long u64;
Наивный подход
Очевидно, что битовая алхимия применяется вовсе не для того, чтобы блистать на собеседовании, а с целью существенного ускорения программ. Ускорения по отношению к чему? По отношению к тривиальным приёмам, которые могут прийти в голову, когда нет времени более детально вникнуть в задачу. Таковым приёмом и является наивный подход к подсчёту битов: мы просто «откусываем» от числа один бит за другим и суммируем их, повторяя процедуру до тех пор, пока число не станет равным нулю.
Я не вижу смысла что-либо комментировать в этом тривиальном цикле. Невооружённым взглядом ясно, что если старший бит числа n равен 1, то цикл вынужден будет пройтись по всем битам числа, прежде чем доберётся до старшего.
Меняя тип входного параметра u8 на u16, u32 и u64 мы получим 4 различные функции. Давайте протестируем каждую из них на потоке из 232 чисел, подаваемых в хаотичном порядке. Понятно, что для u8 у нас 256 различных входных данных, но для единообразия мы всё равно прогоняем 232 случайных чисел для всех этих и всех последующих функций, причём всегда в одном и том же порядке (за подробностями можно обратиться к коду учебной программы из архива).
Время в таблице ниже указано в секундах. Для тестирования программа запускалась трижды и выбиралось среднее время. Погрешность едва ли превышает 0,1 секунды. Первый столбец отражает режим компилятора (32-х битовый исходный код или 64-х битовый), далее 4 столбца отвечают за 4 варианта входных данных.
Как мы видим, скорость работы вполне закономерно возрастает с ростом размера входного параметра. Немного выбивается из общей закономерности вариант, когда числа имеют размер 64 бита, а подсчёт идёт режиме x86. Ясное дело, что процессор вынужден делать четырёхкратную работу при удвоении входного параметра и даже хорошо, что он справляется всего лишь втрое медленнее.
Первая польза этого подхода в том, что при его реализации трудно ошибиться, поэтому написанная таким образом программа может стать эталонной для проверки более сложных алгоритмов (именно так и было сделано в моём случае). Вторая польза в универсальности и относительно простой переносимости на числа любого размера.
Трюк с «откусыванием» младших единичных битов
Этот алхимический приём основан на идее обнуления младшего единичного бита. Имея число n, мы можем произнести заклинание n=n&(n-1), забирая у числа n его младшую единичку. Картинка ниже для n=232 прояснит ситуацию для людей, впервые узнавших об этом трюке.
Код программы не сильно изменился.
Теперь цикл выполнится ровно столько раз, сколько единиц в числе n. Это не избавляет от худшего случая, когда все биты в числе единичные, но значительно сокращает среднее число итераций. Сильно ли данный подход облегчит страдания процессора? На самом деле не очень, а для 8 бит будет даже хуже. Напомню, что сводная таблица результатов будет в конце, а здесь в каждом разделе будет своя таблица.
Предподсчёт
Не будем торопиться переходить к «жёстким» заклинаниям, рассмотрим последний простой приём, который может спасти даже самого неопытного мага. Данный вариант решения задачи не относится напрямую к битовой алхимии, однако для полноты картины должен быть рассмотрен в обязательном порядке. Заведём две таблицы на 256 и 65536 значений, в которых заранее посчитаны ответы для всех возможных 1-байтовых и 2-байтовых величин соответственно.
Теперь программа для 1 байта будет выглядеть так
Чтобы рассчитать число бит в более крупных по размеру числах, их нужно разбить на байты. Например, для u32 может быть вот такой код:
Или такой, если мы применяем таблицу предподсчёта для 2-х байт:
Ну а дальше вы догадались, для каждого варианта размера входного параметра n (кроме 8 бит) может существовать два варианта предподсчёта, в зависимости от того, которую из двух таблиц мы применяем. Думаю, читателю понятно, почему мы не можем просто так взять и завести таблицу BitsSetTableFFFFFFFF, однако вполне могут существовать задачи, где и это будет оправданным.
Быстро ли работает предподсчёт? Всё сильно зависит от размера, смотрите таблицы ниже. Первая для однобайтового предподсчёта, а вторая для двухбайтового.
Интересный момент: для режима x64 предподсчёт для u64 работает заметно быстрее, возможно, это особенности оптимизации, хотя подобное не проявляется во втором случае.
Важное замечание: данный алгоритм с использованием предподсчёта оказывается выгодным только лишь при соблюдении следующих двух условий:
у вас есть лишняя память,
вам требуется выполнять расчёт числа единичных битов намного больше раз, чем размер самой таблицы, то есть имеется возможность «отыграть» время, потраченное на предварительное заполнение таблицы каким-то из нехитрых алгоритмов. Пожалуй, можно также иметь в виду экзотическое условие, которое на практике всегда выполнено. Вы должны гарантировать, что обращение к памяти само по себе быстрое и не замедляет работу других функций системы. Дело в том, что обращение к таблице может выбросить из кэша то, что там было изначально и замедлить таким образом какой-то другой участок кода. Косяк это вы вряд ли найдёте быстро, однако подобные чудовищные оптимизации едва ли кому-то понадобятся на практике при реализации обычных программ.
Умножение и остаток от деления
Возьмем же наконец более сильные зелья с нашей алхимической полки. С помощью умножения и остатка от деления на степень двойки без единицы можно делать довольно интересные вещи. Начнём творить заклинание с одного байта. Для удобства обозначим все биты одного байта латинскими буквами от «a» до «h». Наше число n примет вид:
Умножение n’ = n⋅0x010101 (так, через префикс «0x», я обозначаю шестнадцатеричные числа) делает ни что иное как «тиражирование» одного байта в трёх экземплярах:
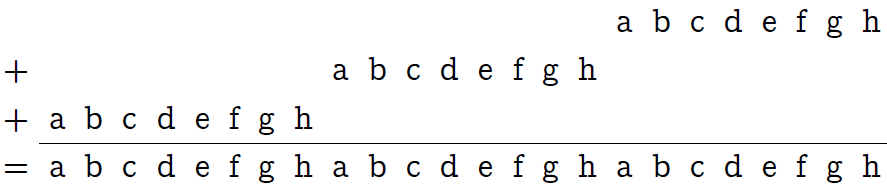
Теперь разобьём мысленно наши 24 бита на 8 блоков по 3 бита в каждом (см. нижеследующую картинку, первую строку таблички). Затем с помощью побитового «и» с маской 0x249249 (вторая строка таблички) обнулим в каждом блоке два старших бита.

Третья строка таблицы поясняет шестнадцатеричную запись маски. В последней строке показан результат, которого мы добивались: все биты исходного байта содержаться каждый в своём трёхбитовом блоке, но в ином порядке (порядок нам и не важен).
Теперь внимание: мы должны сложить эти 8 блоков – и получим сумму наших бит!
Оказывается, что остаток от деления некоторого числа A на 2k-1 как раз даёт сумму k-битовых блоков числа A, тоже взятую по модулю 2k-1.
То есть от полученного нами числа нужно взять остаток от деления на 23-1 (семь) — и мы получаем сумму наших 8-и блоков по модулю 7. Беда в том, что сумма бит может быть равна 7 или 8, в таком случае алгоритм выдаст 0 и 1 соответственно. Но давайте посмотрим: в каком случае мы можем получить ответ 8? Только когда n=255. А в каком случае можем получить 0? Только когда n=0. Поэтому если алгоритм после взятия остатка на 7 даст 0, то либо мы на входе получили n=0, либо в числе ровно 7 единичных бит. Суммируя эту рассуждение, получаем следующий код:
В случае когда n имеет размер 16 бит можно разбить его на две части по 8 бит. Например, так:
Для случая 32-х и 64-х бит подобное разбиение не имеет смысла уже даже в теории, умножение и остаток от деления с тремя ветвлениями будут слишком дорого стоить, если выполнять их 4 или 8 раз подряд. Но я оставил для вас пустые места в нижеследующей таблице, поэтому если вы мне не верите – заполните их, пожалуйста, сами. Там скорее всего будут результаты, сравнимые с процедурой CountBits1, если у вас похожий процессор (я не говорю о том, что здесь возможны оптимизации с помощью SSE, это уже будет другой разговор).
Данный трюк, конечно, можно сделать и без ветвлений, но тогда нам нужно, чтобы при разбиении числа на блоки в блок вместились все числа от 0 до 8, а этого можно добиться лишь в случае 4-битовых блоков (и больше). Чтобы выполнить суммирование 4-битовых блоков, нужно подобрать множитель, который позволит правильно «растиражировать» число и взять остаток от деления на 24-1=15, чтобы сложить получившиеся блоки. Опытный алхимик (который знает математику) легко подберёт такой множитель: 0x08040201. Почему он выбран таким?

Дело в том, что нам необходимо, чтобы все биты исходного числа заняли правильные позиции в своих 4-битовых блоках (картинка выше), а коль скоро 8 и 4 не являются взаимно простыми числами, обычное копирование 8 битов 4 раза не даст правильного расположения нужных битов. Нам придётся добавить к нашему байту один нолик, то есть тиражировать 9 битов, так как 9 взаимно просто с 4. Так мы получим число, имеющее размер 36 бит, но в котором все биты исходного байта стоят на младших позициях 4-битовых блоков. Осталось только взять побитовое «и» с числом 0x111111111 (вторая строка на картинке выше), чтобы обнулить по три старших бита в каждом блоке. Затем блоки нужно сложить.
При таком подходе программа подсчёта единичных битов в байте будет предельно простой:
Недостаток программы очевиден: требуется выход в 64-битовую арифметику со всеми вытекающими отсюда последствиями. Можно заметить, что в действительности данная программа задействует только 33 бита из 64-х (старшие 3 бита обнуляются), и в принципе можно сообразить, как перенести данные вычисления в 32-х битовую арифметику, но рассказы о подобных оптимизациях не входят в тему этого руководства. Давайте пока просто изучать приёмы, а оптимизировать их вам придётся самим уже под конкретную задачу.
Ответим на вопрос о том, какого размера может быть переменная n, чтобы данный трюк правильно работал для неё. Коль скоро мы берём остаток от деления на 15, такая переменная не может иметь размер больше 14 бит, в противном случае придётся применить ветвление, как мы делали это раньше. Но для 14 бит приём работает, если добавить к 14-ти битам один нолик, чтобы все биты встали на свои позиции. Теперь я буду считать, что вы в целом усвоили суть приёма и сможете сами без труда подобрать множитель для тиражирования и маску для обнуления ненужных битов. Покажу сразу готовый результат.
Эта программа выше показывает, как мог бы выглядеть код, будь у вас переменная размером 14 бит без знака. Этот же код будет работать с переменной в 15 бит, но при условии, что максимум лишь 14 из них равные единице, либо если случай, когда n=0x7FFF мы разберём отдельно. Это всё нужно понимать для того, чтобы написать правильный код для переменной типа u16. Идея в том, чтобы сначала «откусить» младший бит, посчитать биты в оставшемся 15-ти битовом числе, а затем обратно прибавить «откушенный» бит.
Здесь точно также можно было вместо трех ветвлений взять 3 остатка от деления, но я выбрал ветвистый вариант, на моём процессоре он будет работать лучше.
Для n размером 64 бита мне не удалось придумать подходящего заклинания, в котором было бы не так много умножений и сложений. Получалось либо 6, либо 7, а это слишком много для такой задачи. Другой вариант — выход в 128-битовую арифметику, а это уже не пойми каким «откатом» для нас обернётся, неподготовленного мага может и к стенке отшвырнуть 🙂
Давайте лучше посмотрим на время работы.
Очевидным выводом из этой таблицы будет то, что 64-х битовая арифметика плохо воспринимается в 32-х битовом режиме исполнения, хотя в целом-то алгоритм неплох. Если вспомнить скорость алгоритма предподсчёта в режиме x64 для однобайтовой таблицы для случая u32 (24,79 с), то получим, что данный алгоритм отстаёт всего лишь на 25%, а это повод к соревнованию, воплощённому в следующем разделе.
Замена взятия остатка на умножение и сдвиг
Недостаток операции взятия остатка всем очевиден. Это деление, а деление – это долго. Разумеется, современные компиляторы знают алхимию и умеют заменять деление на умножение со сдвигом, а чтобы получить остаток, нужно вычесть из делимого частное, умноженное на делитель. Тем не менее, это всё равно долго! Оказывается, что в древних свитках заклинателей кода сохранился один интересный способ оптимизации предыдущего алгоритма. Мы можем суммировать k-битовые блоки не взятием остатка от деления, а ещё одним умножением на маску, с помощью которой обнуляли лишние биты в блоках. Вот как это выглядит для n размером в 1 байт.
Для начала снова тиражируем байт трижды и удаляем по два старших бита у каждого 3-битового блока с помощью уже пройденной выше формулы 0x010101⋅n & 0x249249.

Каждый трёхбитовый блок я для удобства обозначил заглавной латинской буквой. Теперь умножаем полученный результат на ту же самую маску 0x249249. Маска содержит единичный бит в каждой 3-й позиции, поэтому такое умножение эквивалентно сложению числа самого с собой 8 раз, каждый раз со сдвигом на 3 бита:
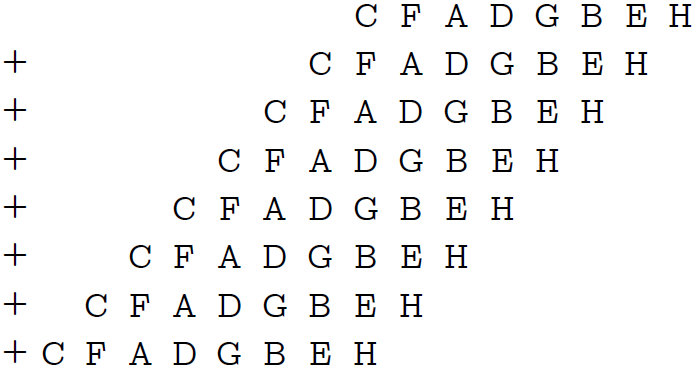
Что мы видим? Биты с 21 по 23 и дают нам нужную сумму! При этом переполнения в каком-либо из блоков справа невозможно, так как там ни в одном блоке не будет числа, большего 7. Проблема лишь в том, что если наша сумма равна 8, мы получим 0, но это не страшно, ведь этот единственный случай можно рассмотреть отдельно.
По сути, мы взяли код из предыдущего раздела и заменили в нём взятие остатка от деления на 7 на умножение, сдвиг и побитовое «И» в конце. При этом вместо 3-х ветвлений осталось лишь одно.
Чтобы составить аналогичную программу для 16 бит, нам нужно взять код из предыдущего раздела, в котором показано как это делается с помощью взятия остатка от деления на 15 и заменить данную процедуру умножением. При этом нетрудно заметить то, какие условия можно убрать из кода.
Для 32-х бит мы делаем то же самое: берём код из предыдущего раздела и, порисовав немного на бумаге, соображаем, каким будет сдвиг, если заменить остаток на умножение.
Для 64-х бит я тоже не смог придумать чего-то такого, чтобы не заставляло бы мой процессор выполнять роль печки.
Приятно удивили результаты для режима x64. Как и ожидалось, мы обогнали предподсчёт с однобайтовой таблицей для случая u32. Можно ли вообще обогнать предподсчёт? Хороший вопрос 🙂
Параллельное суммирование
Пожалуй, это самый распространённый трюк, который очень часто повторяют друг за другом не вполне опытные заклинатели, не понимая, как он точно работает.
Начнём с 1 байта. Байт состоит из 4-х полей по 2 бита, сначала просуммируем биты в этих полях, произнеся что-то вроде:
Вот пояснительная картинка к данной операции (по-прежнему, обозначаем биты одного байта первыми латинскими буквами):
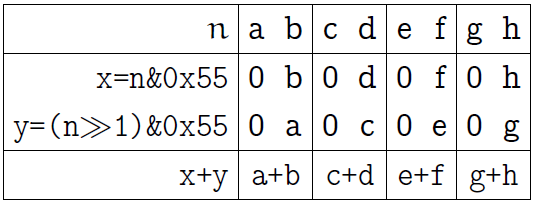
Одно из побитовых «И» оставляет только младшие биты каждого двухбитового блока, второе оставляет старшие биты, но сдвигает их на позиции, соответствующие младшим битам. В результате суммирования получаем сумму смежных битов в каждом двухбитовом блоке (последняя строка на картинке выше).
Теперь сложим парами числа, находящиеся в двухбитовых полях, помещая результат в 2 четырёхбитовых поля:
Нижеследующая картинка поясняет результат. Привожу её теперь без лишних слов:
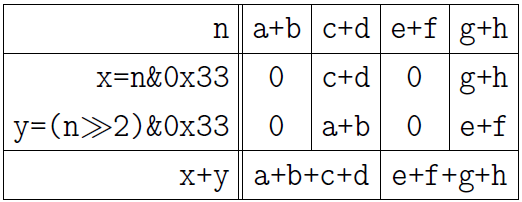
Наконец, сложим два числа в четырёхбитовых полях:
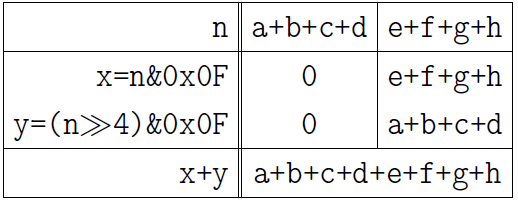
Действуя по аналогии, можно распространить приём на любое число бит, равное степени двойки. Число строк заклинания равно двоичному логарифму от числа бит. Уловив идею, взгляните вскользь на 4 функции, записанных ниже, чтобы убедиться в правильности своего понимания.
В качестве упражнения я бы хотел предложить доказать самостоятельно то, почему нижеследующий код будет точным отображением предыдущего. Для первой строки я даю подсказку, но не смотрите в неё сразу:
Аналогичные варианты оптимизации возможны и для остальных типов данных.
Ниже приводятся две таблицы: одна для обычного параллельного суммирования, а вторая для оптимизированного.
В целом мы видим, что оптимизированный алгоритм работает хорошо, но проигрывает обычному в режиме x86 для u64.
Комбинированный метод
Мы видим, что наилучшие варианты подсчёта единичных битов – это параллельный метод (с оптимизацией) и метод тиражирования с умножением для подсчёта суммы блоков. Мы можем объединить оба метода, получая комбинированный алгоритм.
Первое, что нужно сделать — выполнить первые три строки параллельного алгоритма. Это даст нам точную сумму битов в каждом байте числа. Например, для u32 выполним следующее:
Теперь наше число n состоит из 4 байт, которые следует рассматривать как 4 числа, сумму которых мы ищем:
Мы можем найти сумму этих 4-х байт, если умножим число n на 0x01010101. Вы теперь хорошо понимаете, что означает такое умножение, для удобства определения позиции, в которой будет находиться ответ, привожу картинку:
Ответ находится в 3-байте (если считать их от 0). Таким образом, комбинированный приём для u32 будет выглядеть так:
Он же для u16:
Он же для u64:
Скорость работы этого метода вы можете посмотреть сразу в итоговой таблице.
Итоговое сравнение
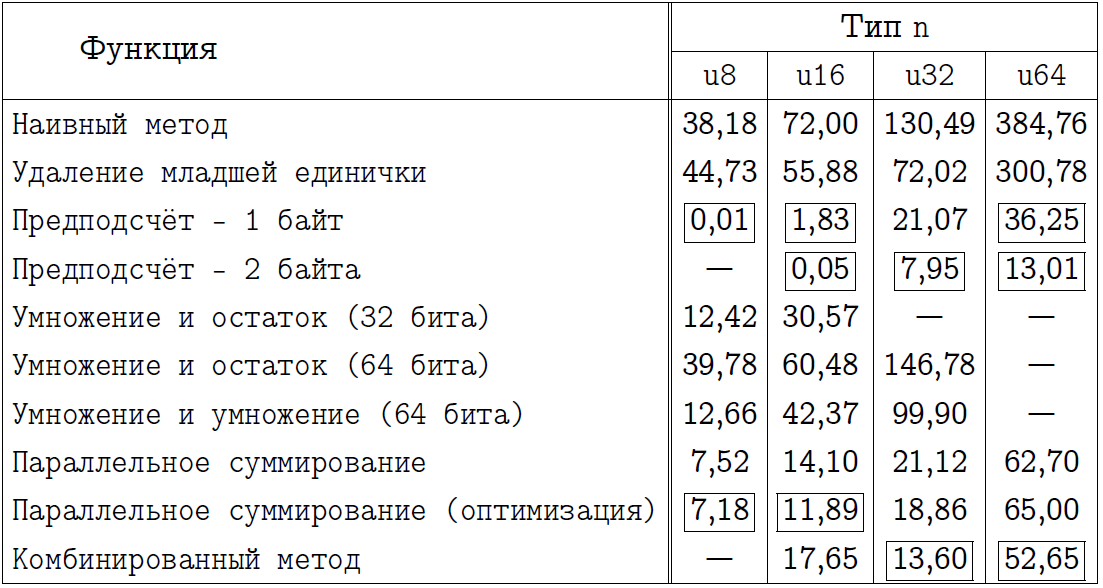
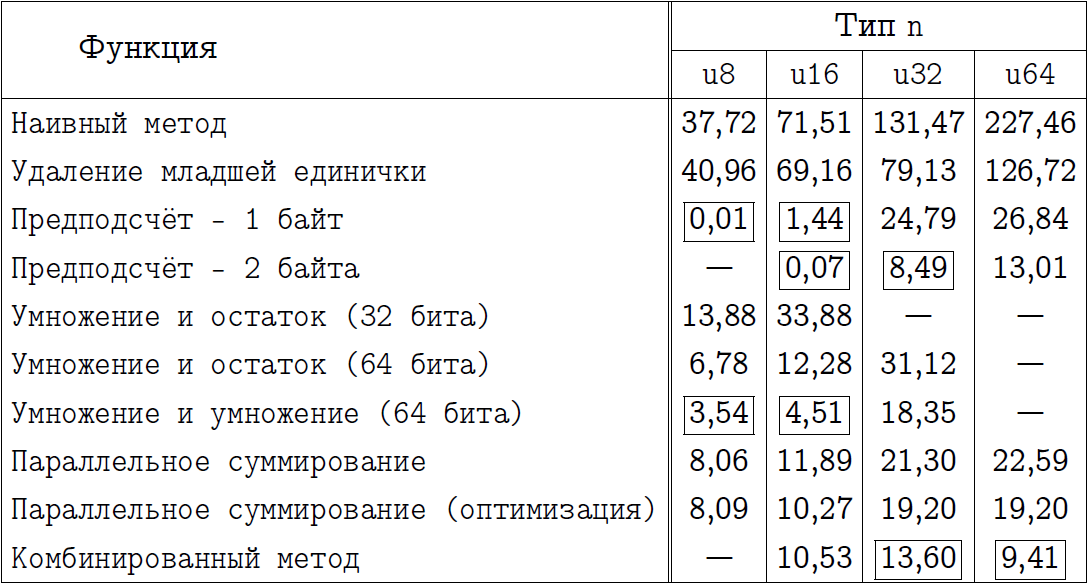
Я предлагаю читателю самостоятельно сделать интересующие его выводы, изучив две нижеследующие таблицы. В них я обозначил название методов, программы к которым мы реализовали, а также пометил прямоугольной рамкой те подходы, которые я считаю наилучшими в каждом конкретном случае. Тех, кто думал, что предподсчёт всегда выигрывает, ожидает небольшой сюрприз для режима x64.
Итоговое сравнения для режима компиляции x86.
Итоговое сравнения для режима компиляции x64.
Замечание
Ни в коем случае не рассматривайте итоговую таблицу как доказательство в пользу того или иного подхода. Поверьте, что на вашем процессоре и с вашим компилятором некоторые числа в такой таблице будут совершенно иными. К сожалению, мы никогда не можем точно сказать, который из алгоритмов окажется лучше в том или ином случае. Под каждую задачу нужно затачивать конкретный метод, а универсального быстрого алгоритма, к сожалению, не существует.
Я изложил те идеи, о которых знаю сам, но это лишь идеи, конкретные реализации которых в разных комбинациях могут быть очень разными. Объединяя эти идеи разными способами, вы можете получать огромное количество разных алгоритмов подсчёта единичных битов, каждый из которых вполне может оказаться хорошим в каком-то своём случае.
Спасибо за внимание. До новых встреч!
UPD: Инструкция POPCNT из SSE4.2 не включена в список тестирования, потому что у меня нет процессора, который поддерживает SSE4.2.


