

Основные сведения
DNS — это база данных, содержащая, в основном, информацию о сопоставлении имён сетевых объектов их IP-адресам. «В основном» — потому что там и ещё кое-какая информация хранится. А точнее, ресурсные записи (Resource Records — RR) следующих типов:
А — то самое сопоставление символьного имени домена его IP адресу.
АААА — то же что А, но для адресов IPv6.
CNAME — Canonical NAME — псевдоним. Если надо чтобы сервер с неудобочитаемым именем, типа nsk-dc2-0704-ibm, на котором вертится корпоративный портал, откликался также на имя portal, можно создать для него ещё одну запись типа А, с именем portal и таким же IP-адресом.
MX — Mail eXchanger — указатель на почтовый обменник. Как и CNAME, представляет собой символьный указатель на уже имеющуюся запись типа A, но кроме имени содержит также приоритет. MX-записей может быть несколько для одного почтового домена, но в первую очередь почта будет отправляться на тот сервер, для которого указано меньшее значение в поле приоритета. В случае его недоступности — на следующий сервер и т.д.
NS — Name Server — содержит имя DNS-сервера, ответственного за данный домен. Естественно для каждой записи типа NS должна быть соответствующая запись типа А.
SOA — Start of Authority — указывает на каком из NS-серверов хранится эталонная информация о данном домене, контактную информацию лица, ответственного за зону, тайминги хранения информации в кэше.
SRV — указатель на сервер, держатель какого-либо сервиса (используется для сервисов AD и, например, для Jabber). Помимо имени сервера содержит такие поля как Priority (приоритет) — аналогичен такому же у MX, Weight (вес) — используется для балансировки нагрузки между серверами с одинаковым приоритетом — клиенты выбирают сервер случайным образом с вероятностью на основе веса и Port Number — номер порта, на котором сервис «слушает» запросы.
Все вышеперечисленные типы записей встречаются в зоне прямого просмотра (forward lookup zone) DNS. Есть ещё зона обратного просмотра (reverse lookup zone) — там хранятся записи типа PTR — PoinTeR — запись противоположная типу A. Хранит сопоставление IP-адреса его символьному имени.
Кроме того, сами зоны, хранящие в себе информацию о домене, бывают двух типов (классически):
Основная (primary) — представляет собой текстовый файл, содержащий информацию о хостах и сервисах домена. Файл можно редактировать.
Дополнительная (secondary) — тоже текстовый файл, но, в отличие от основной, редактированию не подлежит. Стягивается автоматически с сервера, хранящего основную зону. Увеличивает доступность и надёжность.
Для регистрации домена в интернет, надо чтоб информацию о нём хранили, минимум, два DNS-сервера.
В Windows 2000 появился такой тип зоны как интегрированная в AD — зона хранится не в текстовом файле, а в базе данных AD, что позволяет ей реплицироваться на другие контроллеры доменов вместе с AD, используя её механизмы репликации. Основным плюсом данного варианта является возможность реализации безопасной динамической регистрации в DNS. То есть записи о себе могут создать только компьютеры — члены домена.
В Windows 2003 появилась также stub-зона — зона-заглушка. Она хранит информацию только о DNS-серверах, являющихся полномочными для данного домена. То есть, NS-записи. Что похоже по смыслу на условную пересылку (conditional forwarding), которая появилась в этой же версии Windows Server, но список серверов, на который пересылаются запросы, обновляется автоматически.
Открытые ip-адреса
Любому компьютеру, который непосредственно подключен к интернету, присваивается
открытый (public) IP-адрес. Открытый IP-адрес позволяет перемещаться в
интернете с помощью различных классов адресов, которые образуют идентификатор
(ID) сети и адрес узла (см.
“Описание Active Directory”
).
Открытые IP-адреса назначаются провайдерам услуг
интернета (Internet Service Provider, ISP), такими организациями, как LIR (Local
Internet Registry – Локальный реестр интернет), NIR (National Internet Registry –
Национальный реестр интернет) и RIR (Regional Internet Registry – Региональный реестр
интернет). Ниже приводится список доступных организаций RIR:
По мере роста интернета быстро снижается доступный запас открытых адресов
IPv4. Чтобы несколько узлов одной сети, использующие частные адреса, могли использовать
один открытый адрес интернет, были созданы прокси-серверы и несколько
протоколов для маршрутизаторов, такие как NAT (Network Address Translation –
Трансляция [преобразование] сетевых адресов) и PAT (Port Address Translation – Трансляция
[преобразование] адресов портов).
NAT и PAT делают это, добавляя номер порта
к IP-адресу входящих и исходящих пакетов. Маршрутизаторы затем отслеживают
номера портов, назначенные получателям, а также рабочую станцию или
устройство, которое является получателем во внутренней сети.
Из внешнего мира кажется, что каждый PC в вашей сети использует один IP-адрес;
это дает дополнительный уровень безопасности и анонимности при доступе
к серверам Internet, для которых требуется, чтобы определенные порты имели взаимно
однозначное соответствие с адресами.
К примерам таких серверов можно отнести
сервер SMTP (Simple Mail Transfer Protocol), сервер POP3 (Post Office Protocol
версии 3) и серверы FTP, каждый из которых можно статически отображать с помощью
NAT или PAT, используя тот же адрес, что и другие узлы данной сети.
Например, предположим, что у вас имеется два сервера во внутренней сети. Один
из них – это Windows Server 2003, предоставляющий услуги FTP (порты 20 и 21); ему
назначен частный IP-адрес 10.1.2.1. Еще одному серверу Windows 2003, на котором
работает Exchange 2003, предоставляющий почтовые услуги SMTP (порт 25)
и POP3
(порт 110), назначен адрес 10.1.2.2. С помощью NAT и одного маршрутизируемого
открытого адреса 207.212.78.108 все, что поступает для портов 20 и 21, отправляется
на сервер FTP, и все, что поступает для портов 25 и 110, отправляется на сервер, где
работает Exchange 2003.
Служба трансляции имен интернета
DNS (англ. DomainNameSystem — система доменных имён) — компьютерная распределённая система для получения информации о доменах. Чаще всего используется для получения IP-адреса по имени хоста (компьютера или устройства), получения информации о маршрутизации почты, обслуживающих узлах для протоколов в домене (SRV-запись).
Распределённая база данных DNS поддерживается с помощью иерархии DNS-серверов, взаимодействующих по определённому протоколу.Основой DNS является представление об иерархической структуре доменного имени и зонах. Каждый сервер, отвечающий за имя, может делегировать ответственность за дальнейшую часть домена другому серверу (с административной точки зрения — другой организации или человеку), что позволяет возложить ответственность за актуальность информации на серверы различных организаций (людей), отвечающих только за «свою» часть доменного имени.
DNS обладает следующими характеристиками:
1. Распределённостьадминистрирования. Ответственность за разные части иерархической структуры несут разные люди или организации.
2. Распределённость хранения информации. Каждый узел сети в обязательном порядке должен хранить только те данные, которые входят в его зону ответственности и (возможно) адреса корневых DNS-серверов.
3. Кеширование информации. Узел может хранить некоторое количество данных не из своей зоны ответственности для уменьшения нагрузки на сеть.
4. Иерархическая структура, в которой все узлы объединены в дерево, и каждый узел может или самостоятельно определять работу нижестоящих узлов, или делегировать (передавать) их другим узлам.
5. Резервирование. За хранение и обслуживание своих узлов (зон) отвечают (обычно) несколько серверов, разделённые как физически, так и логически, что обеспечивает сохранность данных и продолжение работы даже в случае сбоя одного из узлов.
DNS важна для работы Интернета, так как для соединения с узлом необходима информация о его IP-адресе, а для людей проще запоминать буквенные (обычно осмысленные) адреса, чем последовательность цифр IP-адреса. В некоторых случаях это позволяет использовать виртуальные серверы, например, HTTP-серверы, различая их по имени запроса. Первоначально преобразование между доменными и IP-адресами производилось с использованием специального текстового файла hosts, который составлялся централизованно и автоматически рассылался на каждую из машин в своей локальной сети. С ростом Сети возникла необходимость в эффективном, автоматизированном механизме, которым и стала DNS.
Ключевыми понятиями DNS являются:
Доме́н (англ. domain — область) — узел в дереве имён, вместе со всеми подчинёнными ему узлами (если таковые имеются), то есть именованная ветвь или поддерево в дереве имен. Структура доменного имени отражает порядок следования узлов в иерархии; доменное имя читается слева направо от младших доменов к доменам высшего уровня (в порядке повышения значимости), корневым доменом всей системы является точка (‘.’), ниже идут домены первого уровня (географические или тематические), затем — домены второго уровня, третьего и т. д. (например, для адреса ru.wikipedia.org домен первого уровня — org, второго wikipedia, третьего ru). На практике точку в конце имени часто опускают, но она бывает важна в случаях разделения между относительными доменами и FQDN (англ. FullyQualifedDomainName, полностью определённое имя домена).
Поддомен (англ. subdomain) — подчинённый домен (например, wikipedia.org — поддомен домена org, а ru.wikipedia.org — домена wikipedia.org). Теоретически такое деление может достигать глубины 127 уровней, а каждая метка может содержать до 63 символов, пока общая длина вместе с точками не достигнет 254 символов. Но на практике регистраторы доменных имён используют более строгие ограничения. Например, если у вас есть домен вида mydomain.ru, вы можете создать для него различные поддомены вида mysite1.mydomain.ru, mysite2.mydomain.ru и т. д.
Ресурсная запись — единица хранения и передачи информации в DNS. Каждая ресурсная запись имеет имя (то есть привязана к определенному Доменному имени, узлу в дереве имен), тип и поле данных, формат и содержание которого зависит от типа.
Зона — часть дерева доменных имен (включая ресурсные записи), размещаемая как единое целое на некотором сервере доменных имен (DNS-сервере, см. ниже), а чаще — одновременно на нескольких серверах (см. ниже). Целью выделения части дерева в отдельную зону является передача ответственности (см. ниже) за соответствующий домен другому лицу или организации. Это называется делегированием (см. ниже). Как связная часть дерева, зона внутри тоже представляет собой дерево. Если рассматривать пространство имен DNS как структуру из зон, а не отдельных узлов/имен, тоже получается дерево; оправданно говорить о родительских и дочерних зонах, о старших и подчиненных. На практике, большинство зон 0-го и 1-го уровня (‘.’, ru, com, …) состоят из единственного узла, которому непосредственно подчиняются дочерние зоны. В больших корпоративных доменах (2-го и более уровней) иногда встречается образование дополнительных подчиненных уровней без выделения их в дочерние зоны.
Делегирование — операция передачи ответственности за часть дерева доменных имен другому лицу или организации. За счет делегирования в DNS обеспечивается распределенность администрирования и хранения. Технически делегирование выражается в выделении этой части дерева в отдельную зону, и размещении этой зоны на DNS-сервере (см. ниже), управляемом этим лицом или организацией. При этом в родительскую зону включаются «склеивающие» ресурсные записи (NS и А), содержащие указатели на DNS-сервера дочерней зоны, а вся остальная информация, относящаяся к дочерней зоне, хранится уже на DNS-серверах дочерней зоны.
DNS-сервер — специализированное ПО для обслуживания DNS, а также компьютер, на котором это ПО выполняется. DNS-сервер может быть ответственным за некоторые зоны и/или может перенаправлять запросы вышестоящим серверам.
DNS-клиент — специализированная библиотека (или программа) для работы с DNS. В ряде случаев DNS-сервер выступает в роли DNS-клиента.
Авторитетность (англ. authoritative) — признак размещения зоны на DNS-сервере. Ответы DNS-сервера могут быть двух типов: авторитетные (когда сервер заявляет, что сам отвечает за зону) и неавторитетные (англ. Non-authoritative), когда сервер обрабатывает запрос, и возвращает ответ других серверов. В некоторых случаях вместо передачи запроса дальше DNS-сервер может вернуть уже известное ему (по запросам ранее) значение (режим кеширования).
DNS-запрос (англ. DNS query) — запрос от клиента (или сервера) серверу. Запрос может быть рекурсивным или нерекурсивным (см. Рекурсия).
Система DNS содержит иерархию DNS-серверов, соответствующую иерархии зон. Каждая зона поддерживается как минимум одним авторитетным сервером DNS (от англ. authoritative — авторитетный), на котором расположена информация о домене.
Имя и IP-адрес не тождественны — один IP-адрес может иметь множество имён, что позволяет поддерживать на одном компьютере множество веб-сайтов (это называется виртуальный хостинг). Обратное тоже справедливо — одному имени может быть сопоставлено множество IP-адресов: это позволяет создавать балансировку нагрузки. Для повышения устойчивости системы используется множество серверов, содержащих идентичную информацию, а в протоколе есть средства, позволяющие поддерживать синхронность информации, расположенной на разных серверах. Существует 13 корневых серверов, их адреса практически не изменяются.
DNS работает в режиме вопрос/ответ. Допустим Вы ввели в строке своего браузера ipipe.ru. Рассмотрим работу DNS пошагово:
Шаг 1. Ваш браузер об IP адресе ipipe.ru ничего не знает и с запросом IP адреса ipipe.ru, через специальную программу resolver обращается к локальному серверу имен.
Локальный DNS сервер это сервер имен Вашей локальной сети или DNS сервер Вашего Интернет провайдера (если вы используете DialUp). Откуда браузеру известно о существовании этого локального DNS? Спросите Вы. Все очень просто: При настройках сетевого подключения Вы прописываете IP адреса DNS серверов (предпочитаемого и/или альтернативного) один из которых будет отвечать на запросы посылаемые Вашим браузером через resolver – это и есть локальный или местный сервер Вашей сети. Если Вы используете модемное подключение (через телефонную линию) то для Вас местным сервером имен – будет DNS сервер Вашего провайдера. IP адрес этого сервера также будет прописан в настройках сетевого подключения, не зависимо от того как осуществлялась настройка (вручную или автоматически). Вы всегда сможете посмотреть IP адрес Вашего локального DNS сервера. Для этого достаточно посмотреть свойства сетевого подключения, используемого на Вашем компьютере.
Шаг 2. Запрос на IP адрес ipipe.ru доходит до местного сервера имен. Этот сервер об этом IP адресе ничего не знает, и посылает запрос одному из корневых серверов “.” (root).
Шаг 3. Корневой сервер отдает локальному серверу IP адрес сервера, который поддерживает зону .ru.
Шаг 4. Далее по полученному адресу локальный сервер имен обращается к DNS серверу, который поддерживает .ru.
Шаг 5. Этот DNS сервер по полученному запросу отдает IP адрес сервера, который поддерживает зону ipipe.ru.
Шаг 6. Местный DNS сервер с запросом IP адреса ipipe.ru обращается к DNS серверу зоны ipipe.ru.
Шаг 7. Локальный сервер имен получает IP адрес ipipe.ru. от DNS сервера зоны ipipe.ru.
Шаг 8. Получив адрес ipipe.ru локальный DNS сервер сообщает его Вашему браузеру.
Теперь браузер занет IP адрес ipipe.ru и напрямую обращается к серверу, на котором расположен сайт ipipe.ru.
Имя хоста и IP-адрес не тождественны — хост с одним IP-адресом может иметь множество имён, что позволяет поддерживать на одном компьютере множество веб-сайтов (это называется виртуальный хостинг). Обратное тоже справедливо — одному имени может быть сопоставлено множество хостов: это позволяет создавать балансировку нагрузки.
Запрос на определение имени обычно не идёт дальше кеша DNS, который помнит (ограниченное время) ответы на запросы, проходившие через него ранее. Организации или провайдеры могут по своему усмотрению организовывать кэш DNS. Вместе с ответом приходит информация о том, сколько времени следует хранить эту запись в кэше.
Для повышения устойчивости системы используется множество серверов, содержащих идентичную информацию. Существует 13 корневых серверов, расположенных по всему миру и привязанных к своему региону, их адреса никогда не меняются, а информация о них есть в любой операционной системе.
Протокол DNS использует для работы TCP- или UDP-порт 53 для ответов на запросы. Традиционно запросы и ответы отправляются в виде одной UDP датаграммы. TCP используется в случае, если ответ больше 512 байт, или в случае AXFR-запроса.
Обратный DNS-запрос
DNS используется в первую очередь для преобразования символьных имён в IP-адреса, но он также может выполнять обратный процесс. Для этого используются уже имеющиеся средства DNS. Дело в том, что с записью DNS могут быть сопоставлены различные данные, в том числе и какое-либо символьное имя. Существует специальный домен in-addr.arpa, записи в котором используются для преобразования IP-адресов в символьные имена. Например, для получения DNS-имени для адреса 11.22.33.44 можно запросить у DNS-сервера запись 44.33.22.11.in-addr.arpa, и тот вернёт соответствующее символьное имя. Обратный порядок записи частей IP-адреса объясняется тем, что в IP-адресах старшие биты расположены в начале, а в символьных DNS-именах старшие (находящиеся ближе к корню) части расположены в конце.
Записи DNS
Наиболее важные категории DNS записей:
· Запись A (addressrecord) или запись адреса связывает имя хоста с адресом IP. Например, запрос A-записи на имя referrals.icann.org вернет его IP адрес — 192.0.34.164
· Запись CNAME (canonicalnamerecord) или каноническая запись имени (псевдоним) используется для перенаправления на другое имя
· Запись MX (mailexchange) или почтовый обменник указывает сервер(а) обмена почтой для данного домена.
· Запись PTR (pointer) или запись указателя связывает IP хоста с его каноническим именем. Запрос в домене in-addr.arpa на IP хоста в reverse форме вернёт имя (FQDN) данного хоста (см. Обратный DNS-запрос). Например, (на момент написания), для IP адреса 192.0.34.164: запрос записи PTR 164.34.0.192.in-addr.arpa вернет его каноническое имя referrals.icann.org.
· Запись NS (nameserver) указывает на DNS-серверы для данного домена.
· Запись SOA (StartofAuthority) указывает, на каком сервере хранится эталонная информация о данном домене.
§
Классификация методов аутентификации
В зависимости от степени доверительных отношений, структуры, особенностей сети и удаленности объекта проверка может быть односторонней или взаимной. Также различают однофакторную и строгую (криптографическую) аутентификации. Из однофакторных систем, наиболее распространенными на данный момент являются парольные системы аутентификации. У пользователя есть идентификатор и пароль, т.е. секретная информация, известная только пользователю (и возможно – системе), которая используется для прохождения аутентификации. В зависимости от реализации системы, пароль может быть одноразовым или многоразовым. Рассмотрим основные методы аутентификации по принципу нарастающей сложности.
Базовая аутентификация
При использовании данного вида аутентификации имя пользователя и пароль включаются в состав веб-запроса (HTTPPOST или HTTPGET). Любой перехвативший пакет, легко узнает секретную информацию. Даже если контент с ограниченным доступом не слишком важен, этот метод лучше не использовать, так как пользователь может применять один и тот же пароль на нескольких веб-сайтах. Опросы Sophos показывают, что 41% в 2006 г. и 33% в 2009 г. пользователей применяют для всей своей деятельности в Интернете всего один пароль, будь то сайт банка или районный форум. Также из недостатков парольной аутентификации следует отметить невысокий уровень безопасности – пароль можно подсмотреть, угадать, подобрать, сообщить посторонним лицам и т.д
Дайджест-аутентификация – аутентификация, при которой пароль пользователя передается в хешированном виде. Казалось бы, что по уровню конфиденциальности паролей этот тип мало чем отличается от предыдущего, так как атакующему все равно, действительно ли это настоящий пароль или только хеш от него: перехватив сообщение, он все равно получает доступ к конечной точке. Но это не совсем так – пароль хэшируется всегда с добавлением произвольной строки символов, которая генерируется на каждое соединение заново. Таким образом при каждом соединении генерируется новый хэш пароля и перехват его ничего не даст. Дайджест-аутентификация поддерживается всеми популярными серверами и браузерами.
HTTPS
Протокол HTTPS позволяет шифровать все данные, передаваемые между браузером и сервером, а не только имена пользователей и пароли. Протокол HTTPS (основанный на системе безопасности SSL) следует использовать в случае, если пользователи должны вводить важные личные данные — адрес, номер кредитной карты или банковские сведения. Однако использование данного протокола значительно замедляет скорость доступа.
Аутентификация по предъявлению цифрового сертификата
Механизмы аутентификации с применением цифровых сертификатов, как правило, используют протокол с запросом и ответом. Сервер аутентификации отправляет пользователю последовательность символов, так называемый запрос. В качестве ответа выступает запрос сервера аутентификации, подписанный с помощью закрытого ключа пользователя. Аутентификация с открытым ключом используется как защищенный механизм аутентификации в таких протоколах как SSL, а также может использоваться как один из методов аутентификации в рамках протоколов Kerberos и RADIUS.
Аутентификация по Cookies
Множество различных сайтов используют в качестве средства аутентификации cookies, к ним относятся чаты, форумы, игры. Если cookie удастся похитить, то, подделав его, можно аутентифицироваться в качестве другого пользователя. В случае, когда вводимые данные плохо фильтруются или не фильтруются вовсе, похитить cookies становится не очень сложным предприятием. Чтобы как-то улучшить ситуации используется защита по IP-адресу, то есть cookies сессии связываются с IP-адресом, с которого изначально пользователь ауторизовывался в системе. Однако IP-адрес можно подделать используя IP-спуфинг, поэтому надеяться на защиту по IP-адресу тоже нельзя. На данный момент большинство браузеров используют куки с флагом HTTPonly, который запрещает доступ к cookies различным скриптам.
Децентрализованная аутентификация
Одним из главных минусов таких систем является то, что взлом дает доступ сразу ко многим сервисам.
OpenID
Открытая децентрализованная система аутентификации пользователей. OpenID позволяет пользователю иметь один логин-пароль для различных веб-сайтов. Безопасность обеспечивается подписыванием сообщений. Передача ключа для цифровой подписи основана на использовании алгоритма Диффи — Хеллмана, также возможна передача данных по HTTPS. Возможные уязвимости OpenID:
· подверженфишинговым атакам. Например, мошеннический сайт может перенаправить пользователя на поддельный сайт OpenID провайдера, который попросит пользователя ввести его секретные логин и пароль.
· уязвим перед атакой человек посередине
Аутентификация по OpenID сейчас активно используется и предоставляется такими гигантами, как BBC, Google, IBM, MicrosoftMySpace, PayPal, VeriSign, Yandex и Yahoo!
OpenAuth
Используется для аутентификации AOL пользователей на веб-сайтах. Позволяет им пользоваться сервисами AOL, а также любыми другими надстроенными над ними. Позволяет проходить аутентификацию на сайтах, не относящихся к AOL, при этом не создавая нового пользователя на каждом сайте. Протокол функционирует похожим на OpenID образом. Также приняты дополнительные меры безопасности:
· данные сессии (в том числе информация о пользователе) хранятся не в cookies.
· cookies аутентификации шифруются алгоритмом ‘PBEWithSHAAnd3-KeyTripleDES-CBC’
· доступ к cookies аутентификации ограничен определенным доменом, так что дрyгие сайты не имеют к ним доступа (в том числе сайты AOL)
OAuth
OAuth позволяет пользователю разрешить одному интернет-сервису получить доступ к данным пользователя на другом интернет-сервисе. Протокол используется в таких системах, как Twitter, Google (Google также поддерживает гибридный протокол, объединяющий в себе OpenID и OAuth)
Отслеживание аутентификации самим пользователем
Во многом безопасность пользователей в Интернете зависит от поведения самих пользователей. Так например, Google показывает с какого IP адреса включены пользовательские сесcии, логирует авторизацию, также позволяет осуществить следующие настройки:
· передача данных только по HTTPS.
· Google может детектировать, что злоумышленник использует ваш аккаунт (друзья считают ваши письма спамом, последняя активность происходила в нехарактерное для вас время, некоторые сообщения исчезли …)
· отслеживание списка третьих сторон, имеющих доступ к используемым пользователем продуктам Google
Зачастую пользователю сообщается с какого IP адреса он последний раз проходил аутентификацию.
Многофакторная аутентификация
Для повышения безопасности на практике используют несколько факторов аутентификации сразу. Однако, при этом важно понимать, что не всякая комбинация нескольких методов является многофакторной аутентификацией. Используются факторы различной природы:
Свойство, которым обладает субъект. Например, биометрия, природные уникальные отличия: лицо, отпечатки пальцев, радужная оболочка глаз, капиллярные узоры, последовательность ДНК.
Знание – информация, которую знает субъект. Например, пароль, пин-код.
Владение – вещь, которой обладает субъект. Например, электронная или магнитная карта, флеш-память.
В основе одного из самых надёжных на сегодняшний день методов многофакторной аутентификации лежит применение персональных аппаратных устройств – токенов. По сути, токен – это смарт-карта или USB-ключ. Токены позволяют генерировать и хранить ключи шифрования, обеспечивая тем самым строгую аутентификацию.
Использование классических «многоразовых» паролей является серьёзной уязвимостью при работе с чужих компьютеров, например в интернет-кафе. Это подтолкнуло ведущих производителей рынка аутентификации к созданию аппаратных генераторов одноразовых паролей. Такие устройства генерируют очередной пароль либо по расписанию (например, каждые 30 секунд), либо по запросу (при нажатии на кнопку). Каждый такой пароль можно использовать только один раз. Проверку правильности введённого значения на стороне сервера проверяет специальный сервер аутентификации, вычисляющий текущее значение одноразового пароля программно. Для сохранения принципа двухфакторности аутентификации помимо сгенерированного устройством значения пользователь вводит постоянный пароль.
Протокол FTP.
FileTransferProtocol (FTP)– сетевой протокол, предназначенный для передачи файлов в компьютерных сетях. Протокол FTP позволяет подключаться к серверам FTP, просматривать содержимое каталогов и загружать файлы с сервера или на сервер, кроме того, возможен режим передачи файлов между серверами.
Функции протокола FTP
– решение задач разделения доступа к файлам на удаленных хостах
– прямое или косвенное использование ресурсов удаленных компьютеров
– обеспечение независимости клиента от файловых систем удаленных хостов
– эффективная и надежная передачи данных.
Схемаработы FTP.
Простейшая схема работы протокола FTP представлена на рисунке 7. В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора протокола пользователя средствами.

Рис.7. Простейшая схема работы протокола FTP
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с согласованными в сессии управления параметрами.
Канал данных устанавливается для того же хоста, что и канал управления, через который ведется настройка канала данных. Канал данных может быть использован как для приема, так и для передачи данных.
Алгоритм работы протокола FTP:
Сервер FTP использует в качестве управляющего соединение на TCP порт 21, который всегда находится в состоянии ожидания соединения со стороны пользователя FTP.
После того как устанавливается управляющее соединение модуля “Интерпретатор протокола пользователя” с модулем сервера — “Интерпретатор протокола сервера”, пользователь (клиент) может отправлять на сервер команды. FTP-команды определяют параметры соединения передачи данных: роль участников соединения (активный или пассивный), порт соединения (как для модуля “Программа передачи данных пользователя”, так и для модуля “Программа передачи данных сервера”), тип передачи, тип передаваемых данных, структуру данных и управляющие директивы, обозначающие действия, которые пользователь хочет совершить (например, сохранить, считать, добавить или удалить данные или файл и другие).
После того как согласованы все параметры канала передачи данных, один из участников соединения, который является пассивным (например, “Программа передачи данных пользователя”), становится в режим ожидания открытия соединения на заданный для передачи данных порт. После этого активный модуль (например, “Программа передачи данных сервера”) открывает соединение и начинает передачу данных.
После окончания передачи данных, соединение между “Программой передачи данных сервера” и “Программой передачи данных пользователя” закрывается, но управляющее соединение “Интерпретатора протокола сервера” и “Интерпретатора протокола пользователя” остается открытым. Пользователь, не закрывая сессии FTP, может еще раз открыть канал передачи данных.
Основу передачи данных FTP составляет механизм установления соединения между соответствующими портами и выбора параметров передачи. Каждый участник FTP-соединения должен поддерживать порт передачи данных по умолчанию. По умолчанию “Программа передачи данных пользователя” использует тот же порт, что и для передачи команд (обозначим его “U”), а “Программа передачи данных сервера” использует порт L-1, где “L”- управляющий порт. Однако, участниками соединения используются порты передачи данных, выбранные для них “Интерпретатором протокола пользователя”, поскольку из управляющих процессов участвующих в соединении, только “Интерпретатор протокола пользователя” может изменить порты передачи данных как у “Программы передачи данных пользователя”, так и у “Программы передачи данных сервера”.
Пассивная сторона соединения должна до того, как будет подана команда “начать передачу”, “слушать” свой порт передачи данных. Активная сторона, подающая команду к началу передачи данных, определяет направление перемещения данных.
После того как соединение установлено, между “Программой передачи данных сервера” и “Программой передачи данных пользователя” начинается передача. Одновременно по каналу “Интерпретатор протокола сервера” — “Интерпретатор протокола пользователя” передаются уведомления о получении данных. Протокол FTP требует, чтобы управляющее соединение было открыто, пока по каналу обмена данными идет передача. Сессия FTP считается закрытой только после закрытия управляющего соединения.
Как правило, сервер FTP ответственен за открытие и закрытие канала передачи данных. Сервер FTP должен самостоятельно закрыть канал передачи данных в следующих случаях:
Сервер закончил передачу данных в формате, который требует закрытия соединения.
· Сервер получил от пользователя команду “прервать соединение”.
· Пользователь изменил параметры порта передачи данных.
· Было закрыто управляющее соединение.
· Возникли ошибки, при которых невозможно возобновить передачу данных.
Протокол SMTP.
SMTP(англ. SimpleMailTransferProtocol — простой протокол передачи почты) — это сетевой протокол, предназначенный для передачи электронной почты в сетях TCP/IP.
SMTP используется для отправки почты от пользователей к серверам и между серверами для дальнейшей пересылки к получателю. Для приёма почты почтовый клиент должен использовать протоколы POP3 или IMAP.
Данные передаются при помощи TCP, при этом обычно используется порт 25 или 587. При передаче сообщений между серверами обычно используется порт 25.
Чтобы доставить сообщение до адресата, необходимо переслать его почтовому серверу домена, в котором находится адресат. Для этого обычно используется запись типа MX (англ. MaileXchange — обмен почтой) системы DNS. Если MX запись отсутствует, то для тех же целей может быть использована запись типа A. Некоторые современные реализации SMTP-серверов для определения сервера, обслуживающего почту в домене адресата, также могут задействовать SRV-запись.
Сервер SMTP — это конечный автомат с внутренним состоянием. Клиент передает на сервер строку команда<пробел>параметры<перевод строки>. Сервер отвечает на каждую команду строкой, содержащей код ответа и текстовое сообщение, отделенное пробелом. Код ответа — число от 100 до 999, представленное в виде строки, трактующийся следующим образом:
· 2ХХ — команда успешно выполнена
· 3XX — ожидаются дополнительные данные от клиента
· 4ХХ — временная ошибка, клиент должен произвести следующую попытку через некоторое время
· 5ХХ — неустранимая ошибка
Текстовая часть ответа носит справочный характер и предназначен для человека, а не программы.
Изначально SMTP не поддерживал единой схемы авторизации. В результате этого спам стал практически неразрешимой проблемой, так как было невозможно определить, кто на самом деле является отправителем сообщения — фактически можно отправить письмо от имени любого человека. В настоящее время производятся попытки решить эту проблему при помощи спецификаций SPF, Sender ID, YahooDomainKeys. Единой спецификации на настоящий момент не существует.
Протокол доставки POP3.
POP3 (англ. PostOfficeProtocolVersion 3) — это сетевой протокол, используемый для получения сообщений электронной почты с сервера. Обычно используется в паре с протоколом SMTP.

Рис. 10. Схема «Клиент-сервер по протоколу POP3»
Описание протокола РОРЗ
Рассмотрим представленную на Рис. 10. схему «Клиент-сервер по протоколу POP3». Конструкция протокола РОРЗ обеспечивает возможность пользователю обратиться к своему почтовому серверу и изъять накопившуюся для него почту. Пользователь может получить доступ к РОР-серверу из любой точки доступа к Интернет. При этом он должен запустить специальный почтовый агент (UA), работающий по протоколу РОРЗ, и настроить его для работы со своим почтовым сервером. Итак, во главе модели POP находится отдельный персональный компьютер, работающий исключительно в качестве клиента почтовой системы (сервера). Подчеркнем также, что сообщения доставляются клиенту по протоколу POP, а посылаются по-прежнему при помощи SMTP. То есть на компьютере пользователя существуют два отдельных агента-интерфейса к почтовой системе – доставки (POP) и отправки (SMTP). Разработчики протокола РОРЗ называет такую ситуацию “раздельные агенты” (split UA). Концепция раздельных агентов кратко обсуждается в спецификации РОРЗ.
В протоколе РОРЗ оговорены три стадии процесса получения почты: авторизация, транзакция и обновление. После того как сервер и клиент РОРЗ установили соединение, начинается стадия авторизации. На стадии авторизации клиент идентифицирует себя для сервера. Если авторизация прошла успешно, сервер открывает почтовый ящик клиента и начинается стадия транзакции. В ней клиент либо запрашивает у сервера информацию (например, список почтовых сообщений), либо просит его совершить определенное действие (например, выдать почтовое сообщение). Наконец, на стадии обновления сеанс связи заканчивается. Далее перечислены команды протокола РОРЗ, обязательные для работающей в Интернет реализации минимальной конфигурации.
Команды протокола POP версии 3 (для минимальной конфигурации)
USER Идентифицирует пользователя с указанным именем
PASS Указывает пароль для пары клиент-сервер
QUIT Закрывает TCP-соединение
STAT Сервер возвращает количество сообщений в почтовом ящике плюс размер почтового ящика
LIST Сервер возвращает идентификаторы сообщений вместе с размерами сообщений (параметром команды может быть идентификатор сообщения)
RETR Извлекает сообщение из почтового ящика (требуется указывать аргумент-идентификатор сообщения)
DELE Отмечает сообщение для удаления (требуется указывать аргумент – идентификатор сообщения)
NOOP Сервер возвращает положительный ответ, но не совершает никаких действий
LAST Сервер возвращает наибольший номер сообщения из тех, к которым ранее уже обращались
RSET Отменяет удаление сообщения, отмеченного ранее командой DELE
В протоколе РОРЗ определено несколько команд, но на них дается только два ответа: ОК (позитивный, аналогичен сообщению-подтверждению АСK) и -ERR (негативный, аналогичен сообщению “не подтверждено” NAK). Оба ответа подтверждают, что обращение к серверу произошло и что он вообще отвечает на команды. Как правило, за каждым ответом следует его содержательное словесное описание. В RFC 1225 есть образцы нескольких типичных сеансов РОРЗ. Сейчас мы рассмотрим несколько из них, что даст возможность уловить последовательность команд в обмене между сервером и клиентом.
Авторизация пользователя
После того как программа установила TCP-соединение с портом протокола РОРЗ (официальный номер 110), необходимо послать команду USER с именем пользователя в качестве параметра. Если ответ сервера будет ОК, нужно послать команду PASS с паролем этого пользователя:
CLIENT: USER kcope ERVER: ОК CLIENT: PASS secret SERVER: ОКkcope’smaildrop has 2 messages (320 octets) (Впочтовомящикеkcopeесть 2 сообщения (320 байтов) …)
Транзакции РОРЗ
После того как стадия авторизации окончена, обмен переходит на стадию транзакции. В следующих примерах демонстрируется возможный обмен сообщениями на этой стадии.
Команда STAT возвращает количество сообщений и количество байтов в сообщениях:
CLIENT: STAT
SERVER: ОК 2 320
Команда LIST (без параметра) возвращает список сообщений в почтовом ящике и их размеры:
CLIENT: LIST
SERVER: ОК 2 messages (320 octets)
SERVER: 1 120
SERVER: 2 200
SERVER: . …
Команда NOOP не возвращает никакой полезной информации, за исключением позитивного ответа сервера. Однако позитивный ответ означает, что сервер находится в соединении с клиентом и ждет запросов:
CLIENT: NOOP
SERVER: ОК
Следующие примеры показывают, как сервер POP3 выполняет действия. Например, команда RETR извлекает сообщение с указанным номером и помещает его в буфер местного UA:
CLIENT: RETR 1 SERVER: OK 120 octets SERVER: <the POPS server sends the entire message here> (РОРЗ-сервервысылаетсообщениецеликом) SERVER: . . . . . .
Команда DELE отмечает сообщение, которое нужно удалить:
CLIENT: DELE 1
SERVER: OK message 1 deleted … (сообщение 1 удалено) CLIENT: DELE 2 SERVER: -ERRmessage 2 alreadydeletedсообщение 2 ужеудалено)
Команда RSET снимает метки удаления со всех отмеченных ранее сообщений:
CLIENT: RSET
SERVER: OK maildrop has 2 messages (320 octets)
(в почтовом ящике 2 сообщения (320 байтов) )
Как и следовало ожидать, команда QUIT закрывает соединение с сервером:
CLIENT: QUIT SERVER: OK dewey POP3 server signing off CLIENT: QUIT SERVER: OK dewey POP3 server signing off (maildrop empty) CLIENT: QUIT SERVER: OK dewey POP3 server signing off (2 messages left)
Обратите внимание на то, что отмеченные для удаления сообщения на самом деле не удаляются до тех пор, пока не выдана команда QUIT и не началась стадия обновления. В любой момент в течение сеанса клиент имеет возможность выдать команду RSET, и все отмеченные для удаления сообщения будут восстановлены.
§
Web-кэш, часто называемыйпрокси-сервером, представляет собой сеть, которая выполняет HTTP-запросы от имени сервера-источника. Web-кэш имеет собственное дисковое устройство хранения информации, содержащее ранее запрашивавшиеся копии объектов. Как показано на рис. 2.25, браузер пользователя можно настроить таким образом, чтобы все создаваемые HTTP-запросы сначала направлялись в web-кэш.
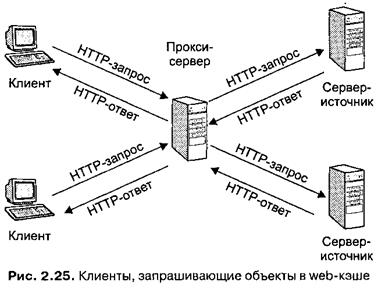
Алгоритм использования кэш-сервера выглядит следующим образом.
1. Браузер устанавливает TCP-соединение с кэш-сервером и посылает ему запрос объекта.
2. Кэш-сервер проверяет наличие локальной копии требуемого объекта и в случае ее обнаружения формирует ответное сообщение и отсылает объект браузеру.
3. Если локальная копия отсутствует, кэш-сервер устанавливает ТСР-соединение с сервером-источником и посылает ему запрос на получение объекта. Сервер-источник обрабатывает запрос и отсылает требуемый объект кэш-серверу.
4. После получения объекта кэш-сервер сохраняет его копию на локальном накопителе информации и передает объект браузеру через открытое ранее ТСР-со-единение.
Кэширование получило широкое распространение в Интернете по трем причинам. Первая заключается в том, что кэш-серверы способны значительно сократить время выполнения запроса пользователя, в особенности если скорость передачи между пользователем и кэш-сервером превышает скорость передачи между пользователем и сервером-источником. Вторая причина популярности механизма кэширования состоит в том, что он способен значительно снизить трафик между локальными сетями и Интернетом. Это позволяет, в свою очередь, сократить расходы на дорогостоящие линии связи, соединяющие локальные сети с Интернетом. Наконец, третья причина успеха кэширования заключается в том, что оно позволяет с большой скоростью распространять ресурсы среди пользователей.
Несколько территориально распределенных кэш-серверов могут объединяться и функционировать совместно.Взаимодействие внутри системы осуществляется при помощи протоколов HTTP и ICP (InternetCachingProtocol — протокол Интернет-кэширования). ICP представляет собой протокол прикладного уровня, описанный в документе RFC 2186 и позволяющий кэш-серверу обратиться к другому кэш-серверу для быстрого поиска требуемого объекта. При наличии искомого объекта осуществляется его передача по протоколу HTTP.
Протокол ICP активно используется в системах совместного кэширования и поддерживается бесплатно распространяемым популярным приложением для кэш-серверов Squid.
Альтернативным вариантом систем совместного кэширования являются кластеры кэшей, как правило, расположенные внутри одной локальной сети. Объединение отдельных кэшей в кластеры обусловливается тем, что первые не всегда имеют накопители информации достаточного объема или не способны обеспечить обработку трафика.
Однако, решая проблему недостаточной мощности отдельных кэш-серверов, кластерная система порождает проблему выбора: какому из кэшей кластера следует направлять запрос объекта. Эта проблема решается путем маршрутизации с использованием хеш-функций. В наиболее простой форме подобной маршрутизации браузер выполняет хэширование URL-адреса запрашиваемого объекта и на основе полученного результата формирует запрос с адресом соответствующего кэш-сервера. Поскольку все браузеры используют одну и ту же хэш-функцию, объект никогда не будет содержаться более чем в одном кэше кластера, и при наличии объекта в кластере браузер сможет однозначно определить, в каком именно кэше находится объект. Маршрутизация с помощью хэш-функций лежит в основе протокола маршрутизации кэш-массива (CacheArrayRoutingProtocol, CARP).
23. Сети распределения ресурсов (CDN) (CDN-компания, CDN-сервер, распределительный CDN узел)
Интернет-провайдеры арендуют и устанавливают кэш-серверы, чтобы повысить качество обслуживания своих пользователей. Как было показано в подразделе «Web-кэширование» данного раздела, применение кэш-серверов способно значительно сократить время доставки наиболее востребованных ресурсов пользователям.В конце 1990-х годов широкое распространение получила еще одна технология распределения ресурсов — технология CDN (ContentDistributionNetwork — сети распределения ресурсов).
Сеть доставки (и дистрибуции) контента (ContentDistributionNetwork, CDN) — географически распределённая сетевая инфраструктура, позволяющая оптимизировать доставку и дистрибуцию контента конечным пользователям в сети Интернет. Использование контент-провайдерами CDN способствует увеличению скорости загрузки интернет-пользователями аудио-, видео-, программного, игрового и других видов цифрового контента в точках присутствия сети CDN.
Обычно CDN-компания функционирует по следующему плану.
1. Компания устанавливает множество (порядка сотен) CDN-серверов, распределенных в Интернете. Как правило, CDN-серверы располагаются в центрах Интернет-хостинга, принадлежащих сторонним компаниям и представляющих собой здания с большим числом хостов внутри. Обычно центры Интернет-хостинга подключены к Интернет-провайдерам нижнего звена и расположены вблизи их сетей доступа.
2. Компания копирует ресурсы своих потребителей на CDN-серверы. Когда потребитель обновляет свои ресурсы, CDN-компания заменяет старое содержимое серверов новым.
3. Компания обеспечивает такое обслуживание, при котором CDN-сервер осуществляет обработку запроса за минимальное время. Для этого выбирается либо такой CDN-сервер, который территориально наиболее близок к пользователю, либо такой, на пути к которому нет перегруженных узлов.
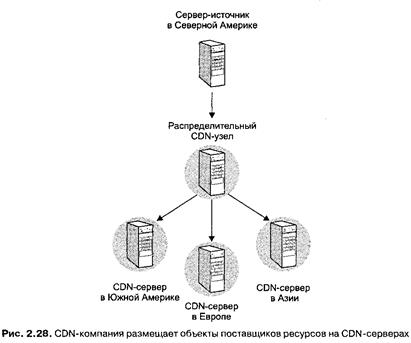
На рис. 2.28 представлена схема взаимодействия между поставщиком ресурсов и CDN-компанией. Сначала поставщик ресурсов определяет объекты, которые он хотел бы сделать распределенными с помощью CDN (остальные объекты могут распространяться без участия CDN). Нужные объекты отсылаются узлу распределения CDN, который, в свою очередь, доставляет их на все CDN-серверы.
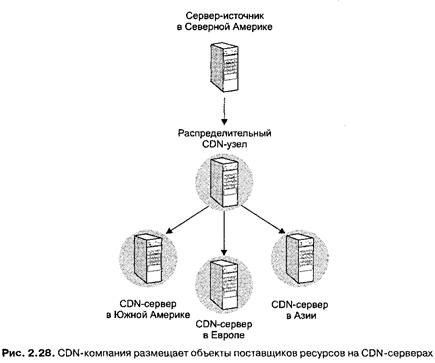
На рис. 2.29 приведена иллюстрация этапов выполнения запроса на получение документа с помощью CDN. Сначала браузер получает базовый HTML-файл с сервера-источника, затем обращается к полномочному серверу имен, который определяет IP-адрес «наилучшего» CDN-сервера, и, наконец, запрашивает распределенные объекты у CDN-сервера. Обратите внимание на то, что приведенная схема не требует внесения изменений в протоколы HTTP и DNS или применения каких-либо дополнительных средств.
§
Динамическая маршрутизация используется для общения маршрутизаторов друг с другом. Маршрутизаторы передают друг другу информацию о том, какие сети в настоящее время подключены к каждому из них. Маршрутизаторы общаются, используя протоколы маршрутизации.
Внутренние протоколы маршрутизации.
Протокол маршрутной информации (RoutingInformationProtocol) — один из самых простых протоколов маршрутизации. Применяется в небольших компьютерных сетях, позволяет маршрутизаторам динамически обновлять маршрутную информацию (направление и дальность в хопах), получая ее от соседних маршрутизаторов.
Когда маршрутизатор отправляет обновление RIP, он добавляет к метрике маршрута, которую он использует, 1 и отправляет соседу. Сосед получает обновление, в котором указано какую метрику для полученного маршрута ему использовать.
Маршрутизатор отправляет каждые 30 секунд все известные ему маршруты соседним маршрутизаторам. Но, кроме этого, для предотвращения петель и для улучшения времени сходимости, используются дополнительные механизмы:
Splithorizon — если маршрут достижим через определенный интерфейс, то в обновление, которое отправляется через этот интерфейс не включается этот маршрут;
Triggeredupdate — обновления отправляются сразу при изменении маршрута, вместо того чтобы ожидать когда истечет Updatetimer;
Routepoisoning — это принудительное удаление маршрута и перевод в состояние удержания, применяется для борьбы с маршрутными петлями.
Poisonreverse — Маршрут помечается, как не достижимый, то есть с метрикой 16 и отправляется в обновлениях.
В обновлениях RIPv2 могут передаваться до 25 сетей.
Таймеры протокола
Updatetimer — частота отправки обновлений протокола, по истечению таймера отправляется обновление. По умолчанию равен 30 секундам.
Invalidtimer — Если обновление о маршруте не будет получено до истечения данного таймера, маршрут будет помечен как Invalid, то есть с метрикой 16. По умолчанию таймер равен 180 секундам.
Flushtimer (garbagecollectiontimer) — По умолчанию таймер равен 240 секундам, на 60 больше чем invalidtimer. Если данный таймер истечет до прихода обновлений о маршруте, маршрут будет исключен из таблицы маршрутизации. Если маршрут удален из таблицы маршрутизации то, соответственно, удаляются и остальные таймеры, которые ему соответствовали.
Holddowntimer — Запуск таймера произойдет после того, как маршрут был помечен как не достижимый. До истечения данного таймера маршрут будет находиться в памяти для предотвращения образования маршрутной петли и по этому маршруту передается трафик. По умолчанию равен 180 секундам. Таймер не является стандартным, добавлен в реализации Cisco.
В базе данных маршрутов хранятся такие маршруты:
· все маршруты, которые были получены по протоколу RIP,
· все непосредственно присоединённые сети, которые RIP анонсирует соседям,
· суммарныемаршруты.
OSPF (OpenShortestPathFirst) — протокол динамической маршрутизации, основанный на технологии отслеживания состояния канала (link-statetechnology).
OSPF использует 5 типов пакетов:
Hello — используется для обнаружения соседей и построения отношений соседства с ними.
DatabaseDescription (DBD) — проверяет синхронизацию базы данных между маршрутизаторами.
Link-StateRequest (LSR) — запрашивает определенные записи о состоянии каналов от маршрутизатора к маршрутизатору.
Link-StateUpdate (LSU) — отправляет определенные записи о состоянии каналов в ответ на запрос.
Link-StateAcknowledgment (LSAck) — подтверждает получение других типов пакетов.
Описание работы протокола.
1. Маршрутизаторы обмениваются hello-пакетами через все интерфейсы, на которых активирован OSPF. Маршрутизаторы, совместно использующие общий канал передачи данных, становятся соседями, когда они приходят к договоренности об определенных параметрах, указанных вихhello-пакетах.
2. На следующем этапе работы протокола маршрутизаторы будут пытаться перейти в состояние смежности со своими соседями. Переход в состояние смежности определяется типом маршрутизаторов, обменивающихсяhello-пакетами, и типом сети, по которой передаются hello-пакеты. OSPF определяет несколько типов сетей и несколько типов маршрутизаторов. Пара маршрутизаторов, находящихся в состоянии смежности, синхронизирует между собой базу данных состояния каналов.
3. Каждый маршрутизатор посылает объявление о состоянии канала маршрутизаторам, с которыми он находится в состоянии смежности.
4. Каждый маршрутизатор, получивший объявление от соседа, записывает информацию, передаваемую в нем, в базу данных состояния каналов маршрутизатора и рассылает копию объявления всем другим своим соседям.
5. Рассылая объявления через зону, все маршрутизаторы строят идентичную базу данных состояния каналов маршрутизатора.
6. Когда база данных построена, каждый маршрутизатор использует алгоритм “кратчайший путь первым” (shortestpathfirst) для вычисления графа без петель, который будет описывать кратчайший путь к каждому известному пункту назначения с собой в качестве корня. Этот граф — дерево кратчайшего пути.
Каждый маршрутизатор строит таблицу маршрутизации, основываясь на своем дереве кратчайшего пути.
Типы сетей, поддерживаемые протоколом OSPF
· Широковещательные сети со множественным доступом (Ethernet, TokenRing)
· Точка-точка (T1, E1, коммутируемый доступ)
· Нешироковещательные сети со множественным доступом (NonBroadcastMultipleAccess, NBMA) (Framerelay)
В разных типах сетей работа OSPF отличается. В том числе отличается процесс установления отношений соседства и настройки протокола.
Типы маршрутизаторов
Внутренний маршрутизатор (internalrouter) — маршрутизатор, все интерфейсы которого принадлежат одной зоне. У таких маршрутизаторов только одна база данных состояния каналов.
Пограничный маршрутизатор (areaborderrouter, ABR) — соединяет одну или больше зон с магистральной зоной и выполняет функции шлюза для межзонального трафика. У пограничного маршрутизатора всегда хотя бы один интерфейс принадлежит магистральной зоне. Для каждой присоединенной зоны маршрутизатор поддерживает отдельную базу данных состояния каналов.
Магистральный маршрутизатор (backbonerouter) — маршрутизатор, у которого всегда хотя бы один интерфейс принадлежит магистральной зоне. Определение похоже на пограничный маршрутизатор, однако магистральный маршрутизатор не всегда является пограничным. Внутренний маршрутизатор интерфейсы которого принадлежат нулевой зоне, также является магистральным.
Пограничный маршрутизатор автономной системы (AS boundaryrouter, ASBR) — обменивается информацией с маршрутизаторами, принадлежащими другим автономным системам или не-OSPF маршрутизаторами. Пограничный маршрутизатор автономной системы может находиться в любом месте автономной системы и быть внутренним, пограничным или магистральным маршрутизатором.
При разделении автономной системы на зоны, маршрутизаторам принадлежащим к одной зоне не известна информация о детальной топологии других зон.
Разделение на зоны позволяет:
· Снизить нагрузку на ЦП маршрутизаторов за счёт уменьшения количества перерасчётов по алгоритму OSPF
· Уменьшить размер таблиц маршрутизации
· Уменьшить количество пакетов обновлений состояния канала
Каждой зоне присваивается идентификатор зоны (area ID). Идентификатор может быть указан в десятичном формате или в формате записи IP-адреса. Однако идентификаторы зон не являются IP-адресами и могут совпадать с любым назначенным IP-адресом.
Существует несколько типов зон.
1. Магистральная зона (backbonearea) (известная также как нулевая зона или зона 0.0.0.0) – формирует ядро сети OSPF.
2. Стандартная зона (standardarea) -обычная зона, которая создается по умолчанию, принимает обновления каналов, суммарные маршруты и внешние маршруты.
3. Тупиковая зона (stubarea)-не принимает информацию о внешних маршрутах для автономной системы, но принимает маршруты из других зон.
4. Totallystubbyarea – не принимает информацию о внешних маршрутах для автономной системы и маршруты из других зон.
5. Not-so-stubbyarea (NSSA)- передает объявления о состоянии внешних каналов автономной системы.
Внешние протоколы маршрутизации.
Существуют протоколы маршрутизации, которые называются протоколами внешних маршрутизаторов (EGP – exteriorgatewayprotocols) или протоколами междоменной маршрутизации (interdomainroutingprotocols). Они предназначены для общения между маршрутизаторами, находящихимися в разных автономных системах. Исторически (и к большому сожалению) предшественником всех EGP был протокол с тем же самым именем: EGP. Более новый EGP – протокол пограничных маршрутизаторов (BGP – BorderGatewayProtocol) в настоящее время используется между магистралью NSFNET и некоторыми региональными сетями, которые подключены к магистрали. Планируется, что BGP заменит собой EGP.
Системы, поддерживающие BGP, обмениваются информацией о доступности сети с другими BGP системами. Эта информация включает в себя полный путь по автономным системам, по которым должен пройти траффик (поток данных), чтобы достичь этих сетей. Эта информация адекватна построению графа соединений AS (автономных систем). При этом возникает возможность легко обходить петли маршрутизации, а также упрощается процесс принятия решений о маршрутизации.
Во-первых, необходимо сказать, что IP датаграмма в AS может принадлежать как к локальному траффику, так и к транзитному траффику. Локальный – это траффик у которого источник и пункт назначения находятся в одной AS. При этом IP адреса источника и назначения указывает на хосты, принадлежащие одной автономной системе. Весь остальной траффик называется транзитным. Основное преимущество использования BGP в Internet заключается в уменьшении транзитного траффика.
Автономная система может принадлежать к следующим категориям:
1. Ограниченная (stub) AS автономная система имеет единственное подключение к одной внешней автономной системе. В такой автономной системе присутствует только локальный траффик.
2. Многоинтерфейсная (multihomed) AS имеет подсоединение к нескольким удаленным автономным системам, однако по ней запрещено прохождение транзитного траффика.
3. Транзитная (transit) AS имеет подключение к нескольким автономным системам и в соответствии с ограничениями может пропускать через себя как локальный, так и транзитный траффик.
Общая топология Internet состоит из транзитных, многоинтерфейсных и ограниченных автономных систем. Ограниченные и многоинтерфейсные автономные системы не нуждаются в использовании BGP – они могут использовать EGP, чтобы обмениваться информацией о доступности с транзитными автономными системами.
BGP позволяет использовать маршрутизацию, основанную на политических решениях (policy-basedrouting). Все правила определяются администратором автономной системы и указываются в конфигурационных файлах BGP. “Политические решения” не являются частью протокола, однако позволяют делать выбор между маршрутами, когда существует несколько альтернативных, и позволяют управлять перераспределением информации. Решения принимаются в соответствии с вопросами безопасности или экономической целесообразности.
BGP отличается от RIP или OSPF тем, что BGP использует TCP в качестве транспортного протокола. Две системы, использующие BGP, устанавливают TCP соединения между собой и затем обмениваются полными таблицами маршрутизации BGP. Обновления представляются в виде изменений таблицы маршрутизации (таблица не передается целиком).
BGP это протокол вектора расстояний, однако, в отличие от RIP (который объявляет пересылки к пункту назначения), BGP перечисляет маршруты к каждому пункту назначения (последовательность номеров автономных систем к пункту назначения). При этом исчезают некоторые проблемы, связанные с использованием протоколов вектора расстояний. Каждая автономная система идентифицируется 16-битным номером.
BGP определяет выход из строя канала или хоста на другом конце TCP соединения путем регулярной отправки сообщения “оставайся в живых” (keepalive) своим соседям. Рекомендуемое время между этими сообщениями составляет 30 секунд. Сообщение “оставайся в живых”, которое используется на уровне приложений, независимо от TCP опций “оставайся в живых”.
§
Помимо протокола IP, используемого для передачи данных, в Интернете есть несколько управляющих протоколов, применяемых на сетевом уровне, к которым относятся ICMP, ARP, IGMP, RARP, ВООТР и DHCP.
IСМР – протокол управляющих сообщений Интернета (коды ICMP)
За работой Интернета следят маршрутизаторы. Когда случается что-то неожиданное, о происшествии сообщается по протоколу ICMP (InternetControlMessageProtocol — протокол управляющих сообщений Интернета), используемому также для тестирования Интернета. Протоколом ICMP определено около дюжины типов сообщений. Каждое ICMP-сообщение вкладывается в IP-пакет.
Основные типы ICMP сообщений
Сообщение АДРЕСАТ НЕДОСТУПЕН используется, когда подсеть или маршрутизатор не могут обнаружить пункт назначения или когда пакет с битом DF (не фрагментировать) не может быть доставлен, так как путь ему преграждает сеть с маленьким размером пакетов.
Сообщение ВРЕМЯ ИСТЕКЛО посылается, когда пакет игнорируется, так как его счетчик уменьшился до нуля. Это событие является признаком того, что пакеты двигаются по замкнутым контурам, что имеется большая перегрузка или установлено слишком низкое значение таймера.
Сообщение ПРОБЛЕМА ПАРАМЕТРА указывает на то, что обнаружено неверное значение в поле заголовка. Это является признаком наличия ошибки в программном обеспечении хоста, отправившего этот пакет, или промежуточного маршрутизатора.
Сообщение ГАШЕНИЕ ИСТОЧНИКА ранее использовалось для усмирения хостов, которые отправляли слишком много пакетов. Хост, получивший такое сообщение, должен был снизить обороты. В настоящее время подобное сообщение редко используется, так как при возникновении перегрузки подобные пакеты только подливают масла в огонь, еще больше загружая сеть. Теперь борьба с перегрузкой в Интернете осуществляется в основном на транспортном уровне. Это будет подробно обсуждаться в главе 6.
Сообщение ПЕРЕАДРЕСОВАТЬ посылается хосту, отправившему пакет, когда маршрутизатор замечает, что пакет адресован неверно.
Сообщения ЗАПРОС ОТКЛИКА и ОТКЛИК посылаются, чтобы определить, достижим ли и жив ли конкретный адресат. Получив сообщение ЗАПРОС ОТКЛИКА, хост должен отправить обратно сообщение ОТКЛИК. Сообщения ЗАПРОС ВРЕМЕННОГО ШТАМПА и ОТКЛИК С ВРЕМЕННЫМ ШТАМПОМ имеют то же назначение, но при этом в ответе проставляется время получения сообщения и время отправления ответа. Это сообщение используется для измерения производительности сети.
ARP — протокол разрешения адресов

При рассылке хостом 1 по сети Ethernet широковещательного пакета с вопросом: «Кому принадлежит IP-адрес 192.31.65.5?» Этот пакет будет получен каждой машиной сети Ethernet 192.31.65.0, а хост 2 ответит на вопрос своим Ethernet-адресом Е1. Таким образом, хост 1 узнает, что IP-адрес 192.31.65.5 принадлежит хосту с Ethernet-адресом Е2. Протокол, который задает подобный вопрос и получает ответ на него, называется ARP (AddressResolutionProtocol — протокол разрешения адресов) и описан в RFC 826. Он работает почти на каждой машине в Интернете.
Преимущество протокола ARP над файлами конфигурации заключается в его простоте. Системный администратор должен всего лишь назначить каждой машине IP-адрес и решить вопрос с маской подсети. Все остальное сделает протокол ARP.
Затем программное обеспечение протокола IP хоста 1 создает Ethernet-кадр для Е2, помещает в его поле полезной нагрузки IP-пакет, адресованный 192.31.65.5, и посылает его по сети Ethernet. Сетевая карта Ethernet хоста 2 обнаруживает кадр, замечает, что он адресован ей, считывает его и вызывает прерывание. Ethernet-драйвер извлекает IP-пакет из поля полезной нагрузки и передает его IP-программе, которая, видя, что пакет адресован правильно, обрабатывает его.
Существуют различные методы повышения эффективности протокола АRР. Во-первых, машина, на которой работает протокол ARP, может запоминать результат преобразования адреса на случай, если ей придется снова связываться с той же машиной. В следующий раз она найдет нужный адрес в своем кэше, сэкономив, таким образом, на рассылке широковещательного пакета. Скорее всего, хосту 2 понадобится отослать ответ на пакет, что также потребует от него обращения к ARP для определения адреса отправителя. Этого обращения можно избежать, если отправитель включит в ARP-пакет свои IP- и Ethernet-адреса. Когда широковещательный ARP-пакет прибудет на хост 2, пара (192.31.65.7, El) будет сохранена хостом 2 в ARP-кэше для будущего использования. Более того, эту пару адресов могут сохранить у себя все машины сети Ethernet.
Кроме того, каждая машина может рассылать свою пару адресов во время загрузки. Обычно эта широковещательная рассылка производится в виде ARP-naкета, запрашивающего свой собственный IP-адрес. Ответа на такой запрос быть не должно, но все машины могут запомнить эту пару адресов. Если ответ все же придет, это будет означать, что двум машинам назначен один и тот же IP-адрес. При этом вторая машина должна проинформировать системного администратора и прекратить загрузку.
Чтобы разрешить изменение соответствий адресов, например, при поломке и замене сетевой карты на новую (с новым Ethernet-адресом), записи в ARP-кэше должны устаревать за несколько минут.
Многоадресное (групповое) вещание и протокол IGMP
Групповое вещание (multicast) требует некоторых расширений в протоколах узлов. IGMP (InternetGroupManagementProtocol — протокол управления группами). Поддержка группового вещания узлами может быть реализована на трех уровнях:
— не поддерживается.
— поддерживается передача групповых сообщений (необходимые дополнительные средства минимальны).
— поддерживается передача и прием.
Каждый из адресов диапазона класса D (224.0.0.0—239.0.0.0) представляет идентификатор вещательной группы. Группы делятся на постоянные (permanent) и временные (transient). Адреса постоянных групп назначаются административно. Для временных групп адреса выделяются динамически из незанятых постоянными. Адрес 224.0.0.0 использовать запрещается. Адрес 224.0.0.1 (all-hostsaddress) используется как общий адрес для всех абонентов группового вешания, непосредственно подключенных к конкретной подсети. Адрес 224.0.0.2 (allrouters) используется для обращения ко всем маршрутизаторам IGMP. Эти два адреса служат для распространения информации по протоколу IGMP. Нет способа задать групповой адрес сразу всех узлов глобальной сети. Группы получателей формируются динамически, узел может быть членом нескольких групп.
Распространение межсетевого группового трафика управляется протоколом IGMP. Все сообщения этого протокола передаются по адресам 224.0.0.1 и 224.0.0.2, поле TTL=1, так что сообщение не выходит за пределы, доступные непосредственно по локальному интерфейсу. Узел, желающий вступить в группу, передает сообщение HostMembershipReport, в котором указывается идентификатор группы. Для верности это сообщение он повторяет 1-2 раза (подтверждений в IGMP не предусматривается). Маршрутизатор, поддерживающий IGMP, принимает это сообщение и заносит идентификатор в свою таблицу с привязкой к порту, от которого получено сообщение. Маршрутизатор периодически посылает запросы HostMembershipQuery, на которые отвечают узлы, считающие себя членами какой-либо группы. Если на пару опросов для определенной группы никто не отозвался, маршрутизатор исключает эту группу из своей таблицы. Для сокращения избыточного служебного трафика узлы отвечают не сразу, а через случайный интервал времени. Если за время этой задержки узел, собравшийся ответить, услышал такой же ответ от другого узла, он свой ответ аннулирует. О выходе из группы узел явно не сообщает, он просто перестает отвечать на опросы. Протокол IGMP используется и для обмена информацией об используемых группах между маршрутизаторами, поддерживающими групповую пересылку. Маршрутизаторы организуют пересылку пакетов группового вещания между портами, для которых в таблицы занесены соответствующие идентификаторы. Конечно, распространение этого трафика контролируется и средствами сетевого администрирования.
Групповое вещание позволяет экономить трафик при количестве получателей более одного: рассылка одной и той же информации нескольким получателям обычными двухточечными средствами приводила бы к росту трафика пропорционально количеству приемников. Групповое вещание позволяет организовать аудио и видеовещание по сети передачи данных. Вышеописанные средства не страхуют от ошибочной доставки пакетов, эта страховка достигается протокольными средствами (идентификации, аутентификации, шифрования) высших протокольных уровней. Механизм динамического назначения идентификаторов групп должен выполняться высокоуровневыми протоколами.
Версия IGMP V.2, обратно совместимая с исходной. В версии 2 введены следующие изменения:
– Определен выбор маршрутизатора-опросчика IGMP — для каждой локальной сети им будет маршрутизатор с наименьшим IP-адресом.
– Определен новый тип сообщения — Group-SpecificQuery, в котором указывается список групп, принадлежность к которым интересует маршрутизатор в данный момент.
– Определено новое сообщение LeaveGroup, которым хост явно указывает на намерение выйти из группы (групп). Сообщение посылается по спецпальному адресу 224.0.0.2 (allrouters).
Эти меры нацелены на экономию полосы пропускания — сокращение лишнего группового трафика.
Версия 3 предполагает возможность выбора источников, данные от которых интересуют групповых получателей. До сих пор, как только узлы заявляли о вхождении в какую-либо группу, маршрутизаторы доставляли им пакеты от всех источников (их может быть множество) данной группы. Теперь сообщением InclusionGroup-SourceReport хост заказывает трафик интересующих источников, а сообщением ExclusionGroup-SourceReport отказывается от его получения. Таким образом сеть освобождается от ненужного трафика.
Для передачи группового трафика требуется сеть маршрутизаторов (и коммутаторов), поддерживающих протоколы IGMP. Поскольку’ в глобальной сети на это способны далеко не все маршрутизаторы, применяют туннелированпе. Пакеты с групповыми адресами инкапсулируются в обычные одноадресные пакеты (IP-Over-IP) и в таком виде пересылаются между шлюзами. Туннели, по которым проходят инкапсулированные пакеты, соединяют шлюзы, расположенные в «островках» сети, на которых имеется полная поддержка группового вещания. В шлюзе на конце туннеля многоадресные пакеты извлекаются из одноадресных и далее рассылаются в пределах «островка» вышеописанным способом. Построение магистральной сети распространения группового трафика MulticastBackbone (MBONE), являющееся нетривиальной задачей, отметим лишь, что для передачи этого трафика используются протоколы DVMRP (DistanceVectorMulticastRoutingProtocol), MOSPF (Multicast OSPF) или PIM (Protocol-IndependentMulticast).
Протоколы RARP, ВООТР и DHCP
Протокол ARP решает проблему определения по заданному IP-адресу Ethernet-адреса хоста. Иногда бывает необходимо решить обратную задачу, то есть по заданномуEthernet-адресу определить IP-адрес. В частности, эта проблема возникает при загрузке бездисковой рабочей станции. Обычно такая машина получает двоичный образ своей операционной системы от удаленного файлового сервера. Но как ей узнать его IP-адрес?
Первым для решения проблемы был разработан протокол RARP (ReverseAddressResolutionProtocol — протокол обратного определения адреса). Этот протокол позволяет только что загрузившейся рабочей станции разослать всем свой Ethernet-адрес и сказать: «Мой 48-разрядный Ethernet-адрес — 14.04.05.18.01.25. Знает ли кто-нибудь мой IP-адрес?» RARP-сервер видит этот запрос, ищет Ethernet-адрес в своих файлах конфигурации и посылает обратно соответствующий IP-адрес.
Использование протокола RARP лучше внедрения IP-адреса в образ загружаемой памяти, так как это позволяет использовать данный образ памяти для разных машин. Если бы IP-адреса хранились бы где-то в глубине образа памяти, каждой машине понадобился бы свой отдельный образ.
Недостаток протокола RARP заключается в том, что в нем для обращения к RARP-серверу используется адрес, состоящий из одних единиц (ограниченное широковещание). Однако эти широковещательные запросы не переправляются маршрутизаторами в другие сети, поэтому в каждой сети требуется свой RARP-сервер. Для решения данной проблемы был разработан альтернативный загрузочный протокол ВООТР. В отличие от RARP, он использует UDP-сообщения, пересылаемые маршрутизаторами в другие сети. Он также снабжает бездисковые рабочие станции дополнительной информацией, включающей IP-адрес файлового сервера, содержащего образ памяти, IP-адрес маршрутизатора по умолчанию, а также маску подсети.
Серьезной проблемой, связанной с применением ВООТР, является то, что таблицы соответствия адресов приходится настраивать вручную. Когда к ЛВС подключается новый хост, протокол ВООТР невозможно использовать до тех пор, пока администратор сети не присвоит ему IP-адрес и не пропишет вручную в конфигурационных таблицах пару (Ethernet-адрес, IP-адрес). Для устранения влияния этого фактора протокол ВООТР был изменен и получил новое имя: DHCP (DynamicHostConfigurationProtocol — протокол динамической настройки хостов). DHCP позволяет настраивать таблицы соответствия адресов как вручную, так и автоматически. Этот протокол описан в RFC 2131 и 2132. В большинстве систем он уже практически заменил RARP и ВООТР.
Подобно RARP и ВООТР, DHCP основан на идее специализированного сервера, присваивающего IP-адреса хостам, которые их запрашивают. Такой сервер не обязательно должен быть подключен к той же ЛВС, что и запрашивающий хост. Поскольку сервер DHCP может быть недоступен с помощью широковещательной рассылки, в каждой ЛВС должен присутствовать агент ретрансляции.
Для отыскания своего IP-адреса загружаемая машина широковещательным способом распространяет специальный пакет DISCOVER (Поиск). Агент ретрансляции DHCP перехватывает все широковещательные пакеты, относящиеся к протоколу DHCP. Обнаружив пакет DISCOVER, он превращает его из широковещательного в одноадресный и доставляет DHCP-серверу, который может находиться и в другой ЛВС. Агенту ретрансляции необходимо знать всего одну деталь: IP-адрес DHCP-сервера.
Встает вопрос: на какое время можно выдавать в автоматическом режиме IP-адреса из пула? Если хост покинет сеть и не освободит захваченный адрес, этот адрес будет навсегда утерян. С течением времени будет теряться все больше адресов. Для предотвращения этих неприятностей нужно выдавать IP-адреса не навсегда, а на определенное время. Такая технология называется лизингом. Перед окончанием срока действия лизинга хост должен послать на DHCP-сервер запрос о продлении срока пользования IP-адресом. Если такой запрос не был сделан или в просьбе было отказано, хост не имеет права продолжать использование выданного ранее адреса.
Протоколы передачи данных (протокол PPP, протокол HDLC)
Протокол передачи данных — набор соглашений интерфейса логического уровня, которые определяют обмен данными между различными программами. Эти соглашения задают единообразный способ передачи сообщений и обработки ошибок при взаимодействии программного обеспечения разнесённой в пространстве аппаратуры, соединённой тем или иным интерфейсом.
High-LevelDataLinkControl (HDLC) — бит-ориентированный протокол канального уровня сетевой модели OSI, разработанный ISO.
HDLC может быть использован в соединениях с множественным доступом, но в настоящее время в основном используется в соединениях точка-точка с использованием асинхронного сбалансированного режима (ABM).
Типы станций
Первичная (ведущая) станция (Primaryterminal) ответственна за управление каналом и восстановление его работоспособности. Она производит кадры команд. В соединениях точка-многоточка поддерживает отдельные связи с каждой из вторичных станций.
Вторичная (ведомая) станция (Secondaryterminal) работает под контролем ведущей, отвечая на её команды. Поддерживает только 1 сеанс связи.
Комбинированная станция (Combinedterminal) сочетает в себе функции как ведущей, так и ведомой станций. Производит и команды и ответы. Только соединения точка-точка.
Каждая из станций в каждый момент времени находится в одном из 3 логических состояний :
1. Состояние логического разъединения (LDS — LogicalDisconnectState)
Если вторичная станция находится в режиме нормального разъединения (NDM), то она может принимать кадры только после получения явного разрешения от первичной. Если же в асинхронном режиме разъединения (ADM), то вторичная станция может самовольно инициировать передачу.
2. Состояние инициализации (IS — InitializationState)
Используется для передачи управления на удалённую комбинированную станцию и для обмена параметрами между удалёнными станциями.
3. Состояниепередачиинформации (ITS — Information Transfer State)
Всем станциям разрешено вести передачу и принимать информацию. Станции могут находиться в режимах NRM, ARM, ABM.
HDLC поддерживает три режима логического соединения, отличающиеся ролями взаимодействующих устройств:
Режим нормального ответа (NormalResponseMode, NRM) требует инициации передачи в виде явного разрешения на передачу от первичной станции. После использования канала вторичной станцией (ответа на команду первичной), для продолжения передачи она обязана ждать другого разрешения. Для выбора права на передачу первичная станция проводит круговой опрос вторичных. Используется в основном в соединениях точка-многоточка.
Режим асинхронного ответа (AsynchronousResponseMode, ARM) даёт возможность вторичной станции самой инициировать передачу. В основном используется в соединениях типа кольцо и многоточечных с неизменной цепочкой опроса, так как в этих соединениях одна вторичная станция может получить разрешение на передачу от другой вторичной и в ответ начать передачу. То есть разрешение на передачу передаётся по типу маркера (token). За первичной станцией сохраняются обязанности по инициализации линии, определению ошибок передачи и логическому разъединению. Позволяет уменьшить накладные расходы, связанные с началом передачи.
Асинхронный сбалансированный режим (AsynchronousBalancedMode, ABM) используется комбинированными станциями. Передача может быть инициирована с любой стороны, может происходить в полном дуплексе. В режиме ABM оба устройства равноправны и обмениваются кадрами, которые делятся на кадры-команды и кадры-ответы.
Для обеспечения совместимости между станциями, которые могут менять свой статус(тип), в протоколе HDLC предусмотрены 3 конфигурации канала:
Несбалансированная конфигурация (UN — UnbalancedNormal) обеспечивает работу 1 первичной и одной или нескольких вторичных станций в (симплексном)полудуплексном и полнодуплексном режимах, с коммутируемым или некоммутируемым каналом.
Симметричная конфигурация (UA — UnbalancedAsynchronous) обеспечивает взаимодействие двух двухточечных несбалансированных станций. Используется 1 канал передачи, в который мультиплексируются и команды и ответы. В данное время не используется.
Сбалансированная конфигурация (BA — BalancedAsynchronous) состоит из 2 комбинированных станций. Передача в(симплексном) полудуплексном и полнодуплексном режимах, с коммутируемым или некоммутируемым каналом. Каждая станция несёт одинаковую ответственность за управление каналом.
PPP (англ. Point-to-PointProtocol) — двухточечный протокол канального уровня (DataLink) сетевой модели OSI. Обычно используется для установления прямой связи между двумя узлами сети, причем он может обеспечить аутентификацию соединения, шифрование и сжатие данных. Используется на многих типах физических сетей: нуль-модемный кабель, телефонная линия, сотовая связь и т. д.
Часто встречаются подвиды протокола PPP такие, как Point-to-PointProtocoloverEthernet (PPPoE), используемый для подключения по Ethernet, и иногда через DSL; и Point-to-PointProtocolover ATM (PPPoA), который используется для подключения по ATM AdaptationLayer 5 (AAL5), который является основной альтернативой PPPoE для DSL.PPP представляет собой целое семейство протоколов: протокол управления линией связи (LCP), протокол управления сетью (NCP), протоколы аутентификации (PAP, CHAP), многоканальный протокол PPP (MLPPP).
LinkControlProtocol (LCP) обеспечивает автоматическую настройку интерфейсов на каждом конце (например, установка размера пакетов) и опционально проводит аутентификацию. Протокол LCP работает поверх PPP, то есть начальная PPP связь должна быть до работы LCP.
PPP позволяет работать нескольким протоколам сетевого уровня на одном канале связи. Другими словами, внутри одного PPP-соединения могут передаваться потоки данных различных сетевых протоколов (IP, Novell IPX и т. д.), а также данные протоколов канального уровня локальной сети. Для каждого сетевого протокола используется NetworkControlProtocol (NCP) который его конфигурирует (согласовывает некоторые параметры протокола).
Так как в PPP входит LCP протокол, то можно управлять следующими LCP параметрами:
1. Аутентификация. RFC 1994 описывает ChallengeHandshakeAuthenticationProtocol (CHAP), который является предпочтительным для проведения аутентификации в PPP, хотя PasswordAuthenticationProtocol (PAP) иногда еще используется. Другим вариантом для аутентификации является ExtensibleAuthenticationProtocol (EAP).
2. Сжатие. Эффективно увеличивает пропускную способность PPP соединения, за счет сжатия данных в кадре. Наиболее известными алгоритмами сжатия PPP кадров являются Stacker и Predictor.
3. Обнаружение ошибок. Включает Quality-Protocol и помогает выявить петли обратной связи посредством MagicNumbers RFC 1661.
4. Многоканальность. Multilink PPP (MLPPP, MPPP, MLP) предоставляет методы для распространения трафика через несколько физических каналов, имея одно логическое соединение. Этот вариант позволяет расширить пропускную способность и обеспечивает балансировку нагрузки.


