
Enable data deduplication
Enable data deduplication
This section will enable data deduplication.
It will take approximately 20 minutes to complete this section.
Read through all steps below and watch the quick video before
continuing.
Copy the script below into your favorite text
editor.$WindowsRemotePowerShellEndpoint # e.g. "fs-0123456789abcdef.example.com"From the Amazon FSx console,
click the link to the STG326 – SAZ file system and
select the Network & security tab. Copy the
Windows Remote PowerShell Endpoint of the file system to the
clipboard (e.g. fs-0123456789abcdef.example.com).Return to your favorite text editor and replace
“windows_remote_powershell_endpoint” with the Windows
Remote PowerShell Endpoint of STG326 – SAZ. Copy the
updated script.Go to the remote desktop session for your Windows Instance 0.
Click Start >> Windows PowerShell.
Run the updated script in the Windows PowerShell window.
NOTE: Complete the next few steps using the remote PowerShell session
to the FSx file server.
Review the PowerShell function commands for data deduplication
available using the Amazon FSx CLI for remote management on
PowerShell.- Run the command in the Remote Windows PowerShell
Session.
- Run the command in the Remote Windows PowerShell
What commands are available?
Enable data depduplication for the entire FSx file system.
- Run the command in the Remote Windows PowerShell
Session.
- Run the command in the Remote Windows PowerShell
Examine your data deduplication environment using the commands in
the table below.
| Command |
| Get-FSxDedupConfiguration |
| Get-FSxDedupStatus |
| Get-FSxDedupJob |
| Get-FSxDedupMetadata |
| Get-FSxDedupSchedule |
| Measure-FSxDedupFileMetadata -path “D:\share” |
Were all these commands successful? Why not?
When is the next scheduled “Optimization” task?
End the remote PowerShell session. Run Exit-PSSession.
Close the PowerShell window. Run exit.
Create new data deduplication optimization schedule
Read through all steps below and watch the quick video before
continuing.

Copy the script below into your favorite text
editor.$WindowsRemotePowerShellEndpoint # e.g. "fs-0123456789abcdef.example.com"From the Amazon FSx console,
click the link to the STG326 – SAZ file system and
select the Network & security tab. Copy the
Windows Remote PowerShell Endpoint of the file system to the
clipboard (e.g. fs-0123456789abcdef.example.com).Return to your favorite text editor and replace
“windows_remote_powershell_endpoint” with the Windows
Remote PowerShell Endpoint of STG326 – SAZ. Copy the
updated script.Go to the remote desktop session for your Windows Instance 0.
Click Start >> Windows PowerShell.
Run the updated script in the Windows PowerShell window.
Complete the next few steps using the remote PowerShell session to the
FSx file server.
Create a new data deduplication optimization schedule.
- Run the command in the Remote Windows PowerShell
Session.
- Use the table values when prompted.
Prompt Value Name DailyOptimization Type Optimization - Run the command in the Remote Windows PowerShell
What time will the optimization start?
Examine the different options available to data deduplication jobs.
- Run the command in the Remote Windows PowerShell
Session.
- Run the command in the Remote Windows PowerShell
Copy the command below into your favorite text editor and
update the start_time parameter with the current time plus 2
minutes. Look at the clock in bottom right corner of the remote
desktop window. Add 2 minutes to this time and replace the
start_time parameter with this value. (i.e. 5:32pm). This time
is in UTC.
Set-FSxDedupSchedule -Name DailyOptimization -Start start_timeRun the updated command in the Windows PowerShell window.
Wait for the time of the DailyOptimization scheduled job to pass
(i.e. 1 minute after the start_time you entered above) and Run the
command below to check the status.Run the command in the Remote Windows PowerShell Session.
Did the optimization schedule run?
- Look at the LastOptimizationTime value of the Get-FSxDedupStatus
output.
- Look at the LastOptimizationTime value of the Get-FSxDedupStatus
How many files were optimized and how much space is saved?
- Find the corresponding Get-FSxDedupStatus output for the command
attributes in the table below
Attribute LastOptimizationResult OptimizedFilesCount OptimizedFilesSavingsRate OptimizedFilesSize SavedSpace - Find the corresponding Get-FSxDedupStatus output for the command
Do you see any optimization? Why not?
- Run the command in the Remote Windows PowerShell
Session.
- Run the command in the Remote Windows PowerShell
What is the MinimumFileAgeDays attribute value?
Update the data deduplication configuration and set the minimum file
age days attribute to 0.- Run the command in the Remote Windows PowerShell
Session.
Set-FSxDedupConfiguration -MinimumFileAgeDays- Run the command in the Remote Windows PowerShell
Update the DailyOptimization data deduplication schedule to Run in 2
minutes.Copy the command below into your favorite text editor and
update the start_time parameter with the current time plus 2
minutes. Look at the clock in bottom right corner of the remote
desktop window. Add 2 minutes to this time and replace the
start_time parameter with this value. (i.e. 5:32pm)
Set-FSxDedupSchedule -Name DailyOptimization -Start start_timeRun the updated command in the Remote Windows PowerShell
Session.Wait for the time of the DailyOptimization scheduled job to pass
(i.e. 1 minute after the start_time you entered above) and Runthe
command below to check on the status.Run the command in the Remote Windows PowerShell Session.
Did the optimization schedule run?
- Look at the LastOptimizationTime value of the Get-FSxDedupStatus
output.
- Look at the LastOptimizationTime value of the Get-FSxDedupStatus
Continue to re-Runthe Get-FSxDedupJob command every few minutes to
check on the status of the job. This may take 5-10 minutes depending
on the amount of data you creating during the test performance
section.Continue with the tutorial while the data deduplication job runs in
the background.If the Get-FSxDedupJob command returns an error, then there are no
more active jobs and the job has completed.Run the command in the Remote Windows PowerShell Session.
How many files were optimized and how much space is saved?
- Find the corresponding Get-FSxDedupStatus output for the command
attributes in the table below.
Attribute LastOptimizationResult OptimizedFilesCount OptimizedFilesSavingsRate OptimizedFilesSize SavedSpace - Find the corresponding Get-FSxDedupStatus output for the command
End the remote PowerShell session. Run Exit-PSSession.
Close the PowerShell window. Run exit.

Here is a quick guide on how to disable Data Deduplication. In this example I disabled Data Deduplication for my F: volume.
1. Make sure no applications or services are writing data to the volume.
2. Check the actual size of your content, and make sure you have the space available on the disk (with room to spare)
3. Unoptimize the data by running the below PowerShell command and wait until it finishes.
Start-DedupJob -Type Unoptimization -Volume F: -Full -WaitNotes
- The Unoptimization command above, when finished, will also disable data deduplication on the volume to prevent further data deduplication on the volume. You can verify this via the Get-DeDupeVolume cmdlet.
- The Disable-DedupVolume cmdlet should only be used when you want to keep content with data deduplication but prevent more content from being deduplicated.
- Unoptimizing a volume can take a good while, and also, the -Wait parameter is quite useful, because otherwise you need to monitor the dedup job process via the Get-DedupJob cmdlet to know when it’s done.
Speed
Unoptimizing a volume can take so much time, it’s sometimes quicker to copy the deduplicated data to a volume on another disk, format the volume on the first disk, and copy the data back.
As an example, unoptimizing only 40 GB of content can take 10 minutes.
Windows автоматически создает скрытый системный каталог System Volume Information в корне любого подключенного диска с файловой системой NTFS (будь то локальный HDD/SSD диск или съемный USB накопитель). Часто размер каталог System Volume Information может достигать десятки и сотни гигабайт и занимать большую часть диска. В этой статье мы разберемся зачем нужен каталог System Volume Information, что в нем хранится, и как его корректно очистить.

Что хранится в каталоге System Volume Information?
Системный каталог System Volume Information находится в корне любого диска Windows и скрыт по умолчанию. Чтобы увидеть этот каталог, разрешите отображать защищенные системных файлов в проводнике Windows: Options -> View -> снимите чекбокс на пункте Hide protected operation system files (Recommended).
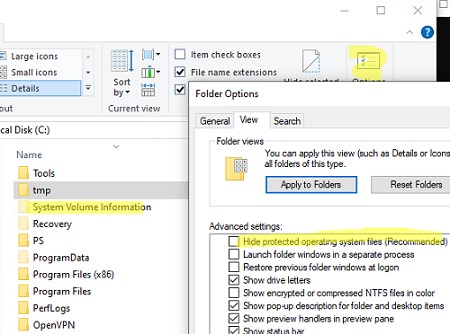
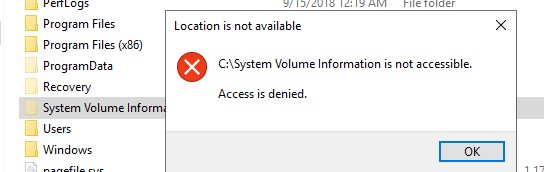
Доступ к этому каталогу есть только у системы (учетная запись NT AUTHORITY\SYSTEM ). Даже встроенный администратор Windows не может открыть и просмотреть содержимое каталога System Volume Information. При его в проводнике появится ошибка доступа:
Расположение недоступно Нет доступа к C:\System Volume Information Отказано в доступе
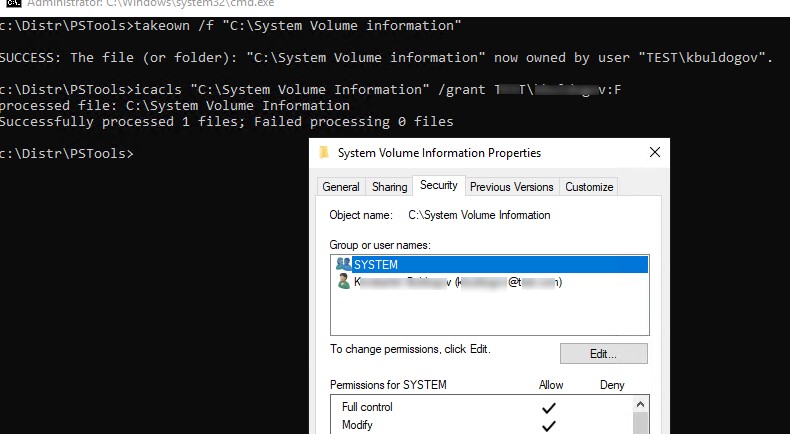
Чтобы открыть каталог System Volume Information можно назначить свою учетную запись владельцем и предоставить NTFS права. Например, с помощью команд:
takeown /f "C:\System Volume information"
icacls "C:\System Volume Information" /grant Corp\kbuldogov:F
Но особого смысла в этом нет. Кроме того, вы можете по неосторожности удалить в папке важные файлы.
Восстановить исходные права доступа на каталоге System Volume Information:
icacls "C:\System Volume Information" /setowner "NT Authority\System"
icacls "C:\System Volume Information" /remove corp\kbuldogov
Для просмотра содержимого каталога System Volume Information нужно запустить консоль PowerShell с правами SYSTEM;
PsExec.exe -i -s powershell.exe
Вывести содержимое каталога и отсортировать файлы в порядке уменьшения размера:

Размер каталога можно получить такой командой PowerShell:
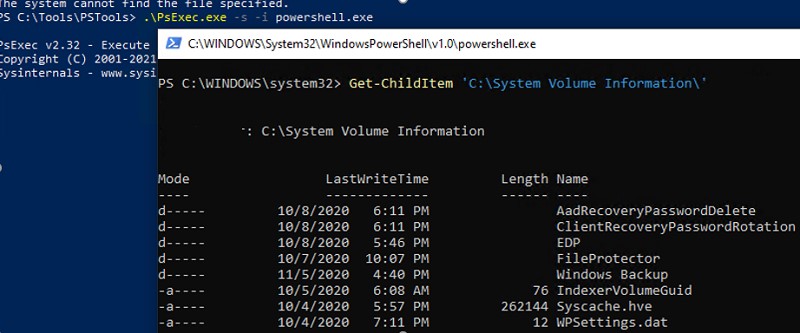
Что же хранится в каталоге System Volume Information? Мне удалось найти информацию о следующих службах, хранящих свои файлы в этой папке (список не является исчерпывающим):
- WindowsImageBackup — данные точек восстановления системы на клиентских системах или резервные копии System State, сделанные через Windows Server Backup (wbadmin), на серверных ОС;
- База данных службы индексирования (Indexing Service), используемая для быстрого поиска файлов (в том числе для поиска в Outlook);
- База данных Distributed Link Tracking Service;
- Снапшоты (теневые копии) дисков, создаваемые службой Volume Shadow Copy , которые можно использовать для восстановления старых версий файлов. Для каждого снапшота создается отдельный файл без расширения с длинным ID;

- Настройки дисковых квот NTFS;
- База и чанки службы дедупликации файлов;
- База репликации DFSR (dfsr.db);
- Файл WPSettings.dat службы хранилища (StorSvc);
- На USB накопителях в этом каталоге хранится файл IndexerVolumeGuid, в котором хранится уникальная метка диска, используемая службой поиска Windows;
- AppxProgramDataStaging, AppxStaging – резервные копии UWP приложений Windows (можно использовать для восстановления после удаления приложений Microsoft Store);
- Лог утилиты проверки диска CHKDSK
- AadRecoveryPasswordDelete и ClientRecoveryPasswordRotation – служебные каталоги BitLocker, используемые при хранении ключа восстановления BitLocker в AD или Azure Entra ID
Примечание. Не удаляете вручную файлы в каталоге System Volume Information, т.к. в нем хранится важная информация, в том числе необходимая для восстановления системы.
Удалить теневые копии в папке System Volume Information
Чаще всего проблема большого размера каталога System Volume Information вызван файлами теневых копий, которые создала служба VSS. Чем чаще создаются теневые копии и чем чаще изменяются файлы на диске, тем быстрее растет размер этого каталога.
На скриншоте ниже видно, что в папке System Volume Information есть системный файл размером больше 120 Гб.
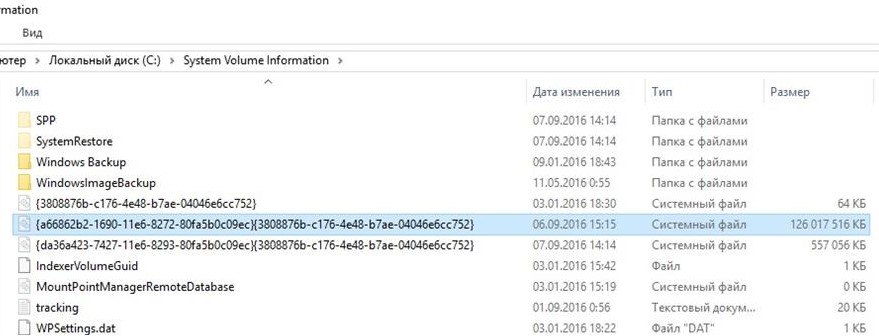
Для быстрой очистки каталога System Volume Information можно удалить старые теневые копии. Чтобы вывести информацию о дисках, для которых служба VSS создает теневые копии, выполните:
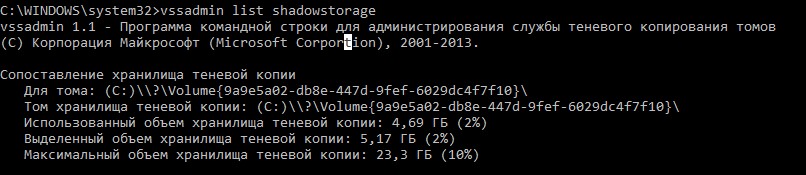
vssadmin 1.1 - Программа командной строки для администрирования службы теневого копирования томов
(C) Корпорация Майкрософт (Microsoft Corportion), 2001-2013.
Сопоставление хранилища теневой копии
Для тома: (C:)\\?\Volume{9a9e5a02-db8e-447d-9fef-6029dc4f7f10}\
Том хранилища теневой копии: (C:)\\?\Volume{9a9e5a02-db8e-447d-9fef-6029dc4f7f10}\ Использованный объем хранилища теневой копии: 4,69 ГБ (2%)
Выделенный объем хранилища теневой копии: 5,17 ГБ (2%)
Максимальный объем хранилища теневой копии: 23,3 ГБ (10%)Утилита покажет текущий и максимальный размер данных теневой копии для каждого диска. По умолчанию для хранения данных теневых копий резервируется 10% диска.
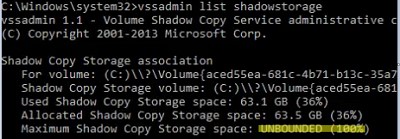
На скриншоте ниже видно, что максимальный размер теневых копий (
Maximum Shadow Copy Storage space: UNBOUNDED (100%)
) не ограничен. В этом случае файлы теневых копий VSS могут занять весь диск.
Настройки квот VSS на дисках могут изменить программы резервного копирования, которые вы устанавливали на компьютер.

Успешно изменен размер для соответствия хранилища теневой копии
После этого (в Windows 10 и 11) выведите список имеющихся теневых копий для системного диска C: с датами их создания:
Чтобы освободить место, удалите самую старую теневую копию:

Можете удалить все VSS снимки:
Также вы можете изменить настройки службы восстановления Windows, которая создает точки восстановления из панели управления System Protection (Защита системы). Выполните команду
systempropertiesprotection
, выберите системный диск и нажмите на кнопку Configure (Настроить).
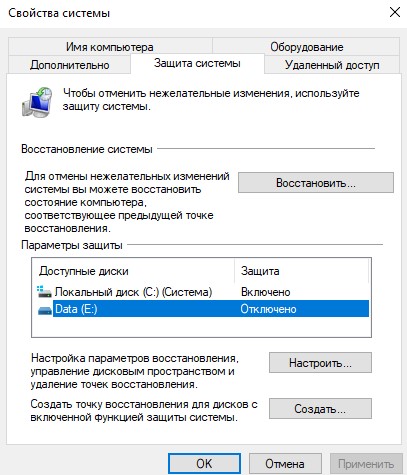
- Включить/отключить защиту системы;
- Узнать текущий размер места под хранение резервных копий образа;
- Изменить настройки квот для хранения точек восстановления;
- Удалить все имеющиеся точки восстановления.
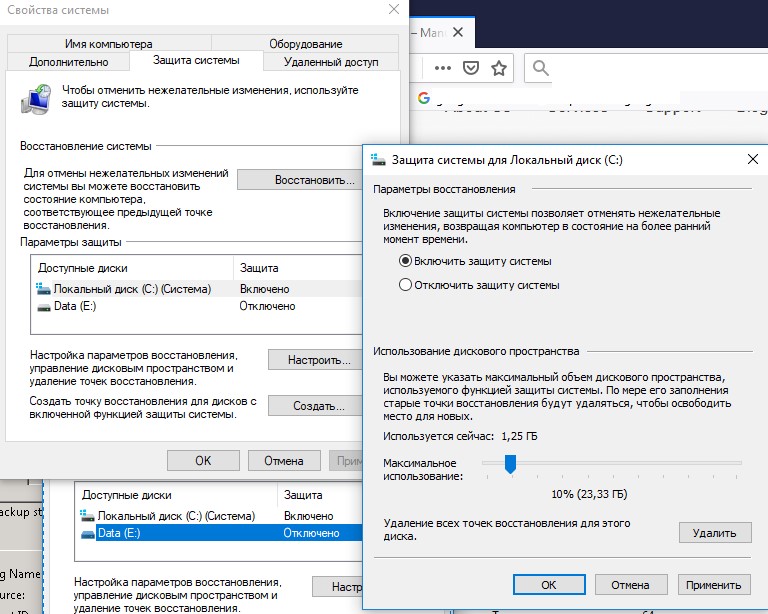
Также для уменьшения размера каталога System Volume Information вы можете:
- Перенести данные VSS снимков на другой NTFS диск (
vssadmin add shadowstorage /for=c: /on=d: /maxsize=30%
); - Отключить/перенастроить функцию История файлов Windows;
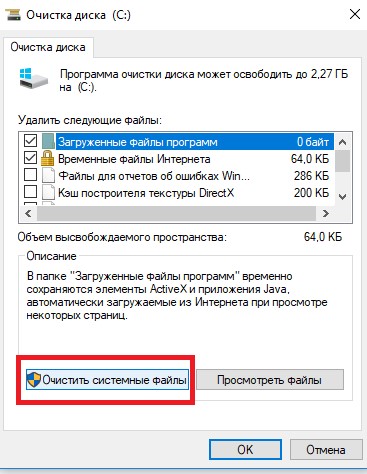
- Выполнить очистку системных файлов на диске с помощью встроенной утилиты cleanmgr.exe (свойства диска -> Очистка диска).
В Windows Server для резервного копирования состояния системы обычно используется Windows Server Backup (WSB). Можно удалить старые версии копий system state с помощью команды:
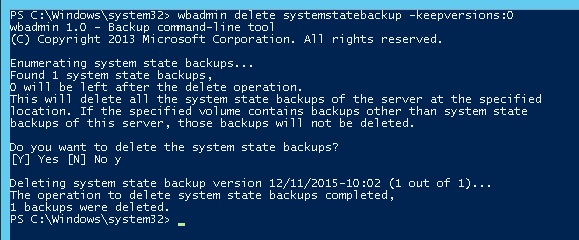
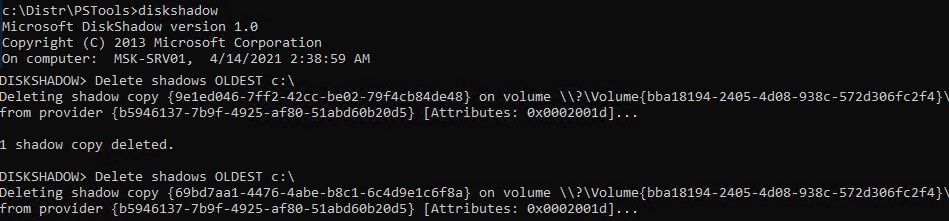
Для быстрой очистки старых версий резервных копий состояния системы (system state) и снапшотов в Windows Server используйте утилиту diskshadow:
DiskShadow
Delete shadows OLDEST c:\
При каждом запуске команды удаляется самая старая теневая копия (снапшот) диска.
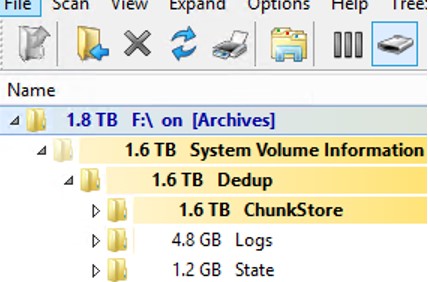
Очистка System Volume Information после удаления файлов на томе с дедупликацией
При анализе содержимого каталога System Volume Information в Windows Server вы можете заметить, что много места занимает каталог Dedup\ChunkStore. Это означает, что на диске включена дедупликация файлов.
Служба дедупликации при нахождении одинаковых чанков в файлах заменяет их на ссылку на уникальный чанк, который сохраняется в каталог System Volume Information. Если вы переместили или удалили оптимизированные файлы с дедуплицированного тома, старые чанки не удаляются немедленно. Эти блоки удаляются специальным заданием сбора мусора (GarbageCollection), которое запускается раз в неделю.
Не отключайте полностью дедупликацию для тома (
Start-DedupJob -Volume D: -Type Unoptimization
), пока не убедитесь что на диске достаточно достаточно свободного места для хранения де-оптимизированных файлов.
Чтобы немедленно запустить процедуру удаления неиспользуемых чанков, выполните команду PowerShell:
start-dedupjob -Volume C:-Type GarbageCollection
Следующее задание проверит целостность оставшихся чанков:
start-dedupjob -Volume C: -Type DataScrubbing
Для мониторинга этих задач используйте командлет:
После окончания задач неиспользуемые чанки в каталоге System Volume Information будут удалены.
Сегодня я кратко расскажу вам как включить дедупликацию данных в клиентских ОС – Windows 10 и Windows 11, добавив функционал из Windows Server, причем не какие-то сторонние бинарники, а оригинальные, подписанные файлы Microsoft, которые к тому же будут обновляться через Windows Update.
В этой статье не будет описания дедупликации данных, – разве что совсем кратко что это такое, и не будет сравнения решений разных вендоров. Я дам ниже ссылки на достойные, на мой взгляд, статьи других авторов и готов буду отвечать на вопросы, если их зададут ниже в виде комментария или в ПМ.
Начать знакомство рекомендую с базовой теории Введение в дедупликацию данных / Хабр (habr.com) от компании Veeam, затем почитать о том, что такое дедупликация Microsoft – Обзор и настройка средств дедупликации в Windows Server 2012 / Хабр (habr.com) – статья моего бывшего коллеги по Microsoft Георгия говорит о том, как настраивается дедупликация NTFS в Windows Server 2012. В последующих изданиях Windows Server 2012R2, 2016, 2019, 2022 и 2025 функционал развивался, появилась поддержка ReFS, стало возможно (неочевидным способом) дедуплицировать системный том, расширились компоненты управления, – но для конечного пользователя все остается там же. Установили одним кликом, включили для диска, забыли. В заключение подготовительной информации – тем кого действительно интересует кроссплатформенные решения и их сравнения, предложу ознакомиться со статьей Илии Карина – Dedup Windows vs Linux, MS снова “удивит”? / Хабр (habr.com) – его не должны заподозрить в рекламе Microsoft, его сравнение подходов, и результат меня самого удивил. У меня на такую большую исследовательскую работу сил и возможностей нет, – почитайте. И имейте в виду, что если вы используете последний Windows 11, то и компоненты дедупликации в нем будут последние, от Windows Server 2025, то есть с еще более впечатляющим результатом.
Итак, дедупликация данных исторически появилась у Microsoft еще во времена Windows 2000 для задач инсталляции ОС по сети, когда вы храните массу одинаковых файлов. Компонента называлась Single Instance Storage и для пользовательских файлов была неприменима. С выходом Windows Storage Server 2003/2008 функционал стал доступен в OEM поставках со специальным оборудованием. В коробочные Windows Server 2003/2003R2/2008/2008R2 функционал не входил, а Storage Server особого распространения не получил.
Ситуация изменилась с выходом Windows Server 2012, – теперь в любой серверной ОС дедупликация стала частью роли файлового сервера. Функционал неплохо развивался, не только в крупных LTSC сборках сервера, но и в выходящих раз в полгода Semi-annual изданиях получал новые возможности.
Я, не буду в данной статье глубоко копать в архитектуру пакетов из которых собирается ОС Windows, но думаю, что не открою вам тайны, сказав что клиентские ОС от серверных отличаются по сути незначительно. Да, там есть много чего “серверного” или наоборот, в них нет много чего “клиентского” (пример Bluetooth или IrDA), но в целом они растут от одного корня. И в те счастливые годы, когда сборки Windows Server и клиентской Windows основаны на одном ядре, мы можем легко заимствовать часть функционала от сервера к клиенту, или наоборот.
О сборках и версиях. Версией у Microsoft сейчас принято называть четырехзначное число, состоящее из двух последних цифр года и двух цифр месяца. Например, версии Windows 10 May 2019 Update была 1903, а номер сборки начинался с цифр 10.0.18362 (или коротко 18362), ей в пару шел Windows Server 1903 (он же 19H1). Простым обновленим они обновлялись до Windows 10 November 2019 Update и Windows Server 1909 (19H2). Далее с появлением Windows 10 May 2020 Update (и Windows Server версии 2004 или 20H1) и до конца поддержки Windows 10 воцарилось царство сборок 10.0.1904х (19041, 19042, 19043, 19044 и 19045). Простыми обновлениями любая из этих ОС обновлялась до последней. И если вы применяли к клиентской ОС какие-либо компоненты от серверной, – те обновлялись вместе с клиентской ОС (о чем будет еще немного позднее).
С выходом Windows 11 в октябре 2021 (версия 21H2 сборка 10.0.22000) ситуация несколько испортилась, – версий Windows Server на этом ядре не было. Равно как и не было их на базе ядер 22621/22631 для Windows 11 2022/2023 Update.
Сейчас, к счастью, снова наступает время длительной сборки 10.0.26100, на базе которой основаны Windows 11 24H2 и Windows Server 2025, и уже сейчас понятно, что следующее издание Windows 11 в 2025 году будет лишь добавочным обновлением, – то есть совместимым с файлами Windows Server 2025, который тоже в рамках Annual релизов получит обновления Server Core.
Итак, хватит лирики, давайте приступим к практике. Я не буду глубоко рассказывать как именно создаются пакеты для переноски между ОС, – если будет интерес, пишите в комментариях, возможно, это стоит отдельной статьи. Но я дам ссылку на утилиту SxSv1, которая позволяет из любой установленной или подмонтированной (WIM) ОС экспортировать компоненты. Ниже я даю примеры на пакеты, которые я этой утилитой экспортировал из ознакомительных образов Windows Server 1903/19H1, 2004/20H1 и 2025/24H1. Вы можете легко сделать то же самое, – тут нет никакого пиратства. Получите рабочее, но неподдерживаемое решение, – что с ним делать судить вам самим. Да, оно будет получать обновления функционала на Windows 11 24H1 через Windows Update, если такие обновления будут входить в кумулятивное обновление, – которое у Windows 11 и Windows Server 2025 общее.
Собственно ссылки. Файлы дедупликации для Windows 10 версий 1903 и 1909 (сборок 10.0.18362 и 10.0.18363). Файлы дедупликации Windows 10 2004/21H2/22H2 (сборок 19041, 19042, 19043, 19044 и 19045). Файлы дедупликации Windows 11 24H2 (сборки 26100/26120). Могу периодически обновлять и добавлять сборки, новые ссылки брать тут (старые версии продолжат быть доступны).
Загрузили архив, распаковали, запустили CMD файл от админстратора, перезагрузились, – пользуйтесь. У вас в компонентах появилась искомая дедупликация данных.

При помощи утилиты ddpeval вы можете оценить выигрыш от применения дедупликации данных:

В моем случае все реальные диски давно дедуплицированы, и я делаю демонстрацию на примере VHDX диска одной из ВМ. Там вижу что из 15.57ГБ при включении дедупликации могу освободить 6.19ГБ. Включается дедупликация просто:

Я не ввожу необязательные параметры, всерьез на результат они не влияют. После некоторого времени (оставьте на ночь или запускайте скрипты оптимизации руками) вы сможете посмотреть результат:

В моем случае на диске, объемом 1 ТБ реально занято 380ГБ, а еще 486ГБ оптимизировано дедупликацией. На этом диске у меня лежат виртуальные машины. На диске с бэкапами домашнего компа статистика еще более впечатляющая.

И вот еще с домашнего ноутбука на Windows 10

Кому полезен этот функционал в клиентской ОС? Кто выигрывает от него и может не бояться потери данных? Проговорю отдельно важные моменты:
· Дедуплицированный диск без проблем работает на любой современной системе (Windows 10/11), где функционала дедупликации не установлено. В основу клиентской ОС входит компонент Microsoft-Windows-Dedup-ChunkLibrary, умеющий обработать метаданные дедупликации. Даже переносной дедуплицированный диск, или диск принесенный с другой рабочей станции будет у вас нормально читаться на системе без дедупликации. И вы сможете писать на него без потери данных. Новые записи всегда будут писаться в новые блоки, не используя дедупликацию. Потом, вернув этот диск на систему с дедупликацией, ОС автоматом все оптимизирует.
· Дедупликация может быть неудобна тем, кто использует не LTSC издания Windows, а обновляется регулярно (каждый год новое ядро) – не факт что для следующего ядра будет аналогичная версия Windows Server, с которой можно экспортировать роль. Обновив (upgrade, а не update) ОС с дедупликацией на новую, вы функционал дедупликации потеряете, – данные все останутся доступны, но вот даже отключить дедупликацию вам в обновленной ОС будет нечем.
· Очень важный момент – не пользуйтесь сторонними утилитами по изменению размеров тома для дедуплицированных дисков. Потеряете данные бесповоротно.
На этом я закончу рассказ, ибо это по сути лишь совет энтузиастам – не бойтесь пробовать новый функционал, – в том числе от серверных ОС на клиентских. Как поклонник виртуализации, я, например, кроме дедупликации еще переношу SVHDXflt драйвер в Windows 11, позволяющий делать общий VHDS диск между несколькими ВМ. Но это совсем другая история.
As far as I am aware, Windows Server’s data deduplication feature does not provide a way to return to files that use chunks. But there are a few ways to figure out if there are any connections:
PowerShell and Deduplication Cmdlets:
Utilize PowerShell cmdlets related to data deduplication. Get-DedupStatus and Get-DedupMetadata may provide insight into duplicate volumes and the associated metadata.
Get-DedupStatus -Volume X:
Get-DedupMetadata -Path "X:\System Volume Information\Dedup\ChunkStore\{F3F1DCDF-134B-4A3E-AFD5-5F698E42667A}.ddp\Data\000004ad.00000001.ccc"I copied these commands out of a real, but ancient doc that I had, but it had some formatting errors. You might need to use, maybe combined with a pipe.
Check File Metadata:
Although this won’t directly link to specific chunks, it can help identify files associated with a particular disk area.
Get-Item "X:\System Volume Information\Dedup\ChunkStore\{F3F1DCDF-134B-4But in fact, there is no direct feature from Windows that fit your Approach as I remember in my 20+ Years of Knowledge in IT. It may also be possible that some kind of Third-Party Application can read that kind, but none is known to me nor was required due NTFS always did an impressive outstanding Job with its DD-Feature.

