
Hi! I’m in a bit of a pickle, I can’t install TrueNAS Scale due to “Uncorrectable ECC” errors (reported as kernel panics during the installation), but I don’t understand what’s to blame, it might’ve been my poor choice of RAM.
CPU: Intel Xeon E3-1220 V6 (used, bundled with the motherboard)
Motherboard: Supermicro X11SSM-F (used, bundled with the CPU)
Memory: Samsung 2x32GB ECC UDIMM DDR4 3200 (M391A4G43BB1-CWE) (new, exact product that I bought)
Boot drive: x2 2.5″ Kingston 120GB SSD (new)
Power supply: Seasonic PRIME PX-650 650 Watt Platinum (new, for 10 HDDs)
I’m installing TrueNAS scale off of a USB stick, I get to where it starts extracting stuff and then it fails with kernel panics:
What I tried:
1. Ran memtest86 for 8 hours with both sticks, no errors, all good. Not even in the event log.
2. Tried to install TrueNAS with one stick only, in both different slots, both sticks – no difference, still fails.
3. Tried it with a spare consumer (non-ECC) DDR4 2666MHz RAM, worked pretty well, was able to install TrueNAS and boot into it.
4. Updated the BIOS to the latest available (I had 2.0c, but I saw that the support for 2667MHz RAM was added later), no difference
5. Updated the firmware to the latest just in case, no difference.
Memory is reported correctly is BIOS – 64GB, running at 2400MHz.
Not sure what to try next, so any help would be much appreciated, thanks!
They could be, but it’s not super likely. One, sure, but two?
What’s more likely is an incompatibility between your system and those DIMMs – there may be tweaking you can do in the system firmware setup menu, but it’s very technical, way outside my area of expertise and possibly able to damage hardware.
Wait a minute, 32 GB DIMMs aren’t supposed to work with Xeon E3 v5/v6. I can’t tell you what arcane DDR4 specification is at fault here, just that support for 32 GB DIMMs was a notable feature for Xeon E when it came out.
I really wish it was mentioned in the Hardware Recommendations.
I bought and installed 4x16GB, everything works just fine, so the problem was RAM after all. What an obscure error.
I ran this: https://www.memtest86.com/download.htm – is that the good commercial thing, or was I supposed to run something else?
Now it is not clear on the size per DIMM. But, it states 2 memory channels, (and I can assume 2 DIMMs per channel), with 64GB maximum memory., gives the 4 x 16GB. So, at a guess, 16GB is the maximum DIMM size.
Plus, the SuperMicro page for the system board X11SSM-F has 16GB listed as the maximum DIMM size;
This is not meant to be a criticism, but to help you and others reading this thread that their are hints if you have the right tools. Took me a long time to stumble across Intel Ark site. And, unlike some of the other vendors, SuperMicro actually lists lots of information about it’s system boards.
This is actually one of those things that changes a bit between generations. Some CPUs are fine with larger DIMMs, up to their total maximum addressable capacity per channel, some will just not work.
Actually, I think it’s caused by the DIMMs themselves more so than the CPUs, but the PC DRAM world is opaque and changes often, so I can’t tell you exactly why that is.
Hi, I need some help here. I can’t install TrueNAS Scale due to “Uncorrectable ECC” errors as well, but in my case I already installed the correct RAM size (which is 16GB per DIMM).
Let me explain the details.
CPU: Intel Xeon E3-1245 V5 (used)
Motherboard: Supermicro X11SSM-F (new, bought from wiredzone)
Memory: Micron 2x16GB ECC UDIMM DDR4 3200 (MTA9ASF2G72AZ-3G2R) (new, this was the only Micron ECC UDIMM memory I could get locally, link to the product page)
Boot drive: 1x 2.5″ Adata SU650 SSD 120GB (new)
Power supply: Fractal Design Ion Gold 750W (new, for 8 HDDs)
I’ve got the same BIOS version here:
And exactly the same problem: the machine started extracting stuffs and then failed doing it with kernel panics as seen below
So I’m not sure what went wrong here. Please, help me with this.
Running something else on the machine won’t end well if there’s a problem with the machine.
Four PASSES of memtest? That’s nothing. Try four days or even four weeks. Wait for it to fall over. If the memory is just on the edge, you may need to be more patient or aggressive, such as making sure your memtest is utilizing all cores simultaneously. If you can easily get a warning out of SCALE, you should be able to replicate this without too much effort on Memtest.
Thank you for the quick response, I think I got your point.
Tonight I’ll try to run Memtest86 again and this time I’ll make it 12 passes for each stick.
I’ll post the results when it’s over. Let’s hope I’ll get an error or two.
Update:
Last night I didn’t run Memtest86, but I installed an 8GB memory stick from my Dell T40 instead (it’s an SK Hynix), and truenas scale installation ran perfectly. I suspected that the memory sticks I bought had some compatibility issues with X11SSM-F since they’re not confirmed by Crucial website. So I planned to return them and buy another pair from crucial (link to product page) which has compatibility confirmation for X11SSM-F. It’ll take some time to arrive here, but I’ll make sure to post an update afterward. Thanks for pointing out that the problem lies with the memory.
25.08.2012, 03:11. Показов 625110. Ответов 2
В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S. M. A. R. T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S. M. A. R. T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. However, it is the value of Value that falls below the Threshold that can become a legitimate reason for replacing the disk under warranty (for the guaranteeers themselves, of course) – who can speak more clearly about the health of the disk than he himself, demonstrating the current value of the attribute is worse than the critical threshold? That is, if the value of Value is greater than Threshold, the disk itself considers that the attribute is healthy, and if it is less or equal, it is sick. Obviously, if Threshold=0, the attribute state will never be recognized as critical. Threshold is a constant parameter hardcoded by the manufacturer in the disk.
RAW (Data) is the most interesting, important and necessary indicator for evaluation. In most cases, it does not contain ye, but real values expressed in various units of measurement, directly talking about the current state of the disk. Based on this indicator, the Value value is formed (but by what algorithm it is formed is already a secret of the manufacturer, covered in darkness). It is the ability to read and analyze the RAW field that makes it possible to objectively assess the state of the hard drive.
Now let’s move on to the attributes themselves.
Raw Read Error Rate — The rate of errors when reading data from the disk, the origin of which is due to the disk hardware. For all Seagate, Samsung (F1 and newer families) and Fujitsu 2.5″ drives, this is the number of internal data corrections carried out before being output to the interface, therefore, you can safely react to frighteningly huge numbers.
Throughput Performance – Overall disk performance. If the value of the attribute decreases, then there is a high probability that there is a problem with the disk.
Spin-Up Time – The time it takes for a disk pack to spin up from rest to operating speed. It grows with the wear of the mechanics (increased friction in the bearing, etc.), and may also indicate poor-quality power (for example, a voltage drop when the disk starts).
Start/Stop Count – Total number of spindle start-stop cycles. Drives from some manufacturers (for example, Seagate) have a power saving mode activation counter. The raw value field stores the total number of disk starts/stops.
Reallocated Sectors Count — The number of reallocated sectors. When the drive detects a read/write error, it marks the sector as “remapped” and transfers the data to a dedicated spare area. This is why bad blocks cannot be seen on modern hard drives – they are all hidden in remapped sectors. This process is called remapping, and the remapped sector is called remap. The higher the value, the worse the surface condition of the discs. The raw value field contains the total number of reassigned sectors. An increase in the value of this attribute may indicate a deterioration in the state of the disk pancake surface.
Read Channel Margin – Read channel margin. The purpose of this attribute is not documented. It is not used in modern drives.
Seek Error Rate – The frequency of errors when positioning the block of magnetic heads. The more of them, the worse the condition of the mechanics and / or the surface of the hard drive. Also, the value of the parameter can be affected by overheating and external vibrations (for example, from neighboring disks in the basket).
Seek Time Performance — The average performance of the magnetic head positioning operation. If the attribute value decreases (positioning slowdown), then there is a high probability of problems with the mechanical part of the actuator.
Power-On Hours (POH) – The number of hours (minutes, seconds – depending on the manufacturer) spent in the on state. As a threshold value for it, the passport time between failures (MTBF – mean time between failure) is selected.
Spin-Up Retry Count – The number of retries to spin up disks to operating speed if the first attempt was unsuccessful. If the value of the attribute increases, then there is a high probability of problems with the mechanical part.
Recalibration Retries – The number of times to retry recalibration requests if the first attempt was unsuccessful. If the value of the attribute increases, then there is a high probability of problems with the mechanical part.
Device Power Cycle Count — The number of complete drive on/off cycles.
Soft Read Error Rate — The number of read errors caused by software that cannot be corrected. All errors have
nature and indicate only incorrect layout / interaction with the disk programs or the operating system.
Erase/Program Cycles (for SSD) The total number of erase/program cycles for the entire flash memory over its lifetime. The solid state drive has a limit on the number of writes to it. The exact values (resource) depend on the installed flash memory chips.
In Kingston drives – the amount of erased in gigabytes.
Translation Table Rebuild (for SSD) The number of times the internal block address tables were corrupted and subsequently rebuilt. The raw value of this attribute indicates the actual number of events.
Program Fail Count (for SSD) Number of retries when writing to flash memory failed. The raw value shows the actual number of failures. The writing process is technically called “flash programming” – hence the name of the attribute. When flash memory is worn out, it can no longer be written to and becomes read-only.
The value is usually identical to attribute 181.
Erase Fail Count (for SSD) The number of times an erase operation on the flash memory failed. The raw value shows the actual number of failures. A complete flash write cycle consists of two stages. The memory must first be removed, and then the data must be written (“programmed”) into the memory. When flash memory is worn out, it can no longer be written to and becomes read-only.
Identical to attribute 182.
Wear Leveller Worst Case Erase Count (for SSD) The maximum number of erase operations performed on a single block of flash memory.
Unexpected Power Loss (for SSD) The number of unexpected power outages where power was lost before the disk was commanded to turn off. On a hard drive, the lifespan of these shutdowns is much shorter than that of a normal shutdown. On an SSD, there is a risk of losing the internal state table when shutting down unexpectedly.
Program Fail Count (for SSD) Number of retries when writing to flash memory failed. The raw value shows the actual number of failures. The writing process is technically called “flash programming”, hence the name of the attribute. When flash memory is worn out, it can no longer be written to and becomes read-only.
SATA Downshifts (for SSD) Specifies how often the SATA data transfer rate (from 6 Gb/s to 3 or 1.5 Gb/s or from 3 Gb/s to 1.5 Gb/s) is required to successful data transfer. If the attribute value decreases, try replacing the SATA cable.
The bottom line is that a hard drive operating in SATA 3 Gb / s or 6 Gb / s modes (and what will happen next in the future), for some reason (for example, due to errors) may try to “negotiate” with the disk controller to a lower speed mode (for example, SATA 1.5 Gb / s or 3 Gb / s, respectively). If the controller “fails” to change the mode, the disk increases the value of the attribute (Western Digital und Samsung).
End-to-End error – The purpose depends on the manufacturer.
For HP (part of HP SMART IV technology), it increases when the data parity between the host and the hard disk does not match after data transfer through the cache memory.
For Kinston, this is the number of flash read errors.
Head Stability Head stability (Western Digital).
Reported UNC Errors — The number of errors that the drive reported to the host (computer interface) during any operations, usually these are data errors on the drive that are not corrected by ECC tools
Command Timeout – contains the number of operations that were canceled due to exceeding the maximum allowable response timeout. Such errors can occur due to poor quality of cables, contacts, used adapters, extension cords, etc., incompatibility of the drive with a specific SATA / PATA controller on the motherboard, etc. Due to errors of this kind, BSODs are possible in Windows.
A non-zero value of the attribute indicates a potential “disease” of the disk.
High Fly Writes – contains the number of recorded cases of writing at a height of “flight” of the head above the calculated one, most likely due to external influences, such as vibration.
In order to say why such cases occur, you need to be able to analyze the S. M. A. R. T. logs, which contain information specific to each manufacturer
Airflow Temperature (WDC) — The temperature of the air inside the hard drive case. For Seagate drives, it is calculated using the formula (100 – HDA temperature). For discs
– (125 – HDA).
G-sense error rate — The number of errors resulting from impact loads. The attribute stores the readings of the built-in accelerometer, which
fixes all shocks, shocks, falls and even inaccurate installation of the disk into the computer case.
Relevant for mobile hard drives. On Samsung drives, you can often ignore it, because. they can have a very sensitive sensor, which, figuratively speaking, reacts almost to the movement of air from the wings of a fly flying in the same room as the disk.
In general, the operation of the sensor is not a sign of an impact. It can grow even from the positioning of the BMG by the disk itself, especially if it is not fixed. The main purpose of the sensor is to stop the recording operation during vibrations in order to avoid errors.
In today’s article:
1. How can I find out the condition of my hard drive or SSD, how long it will live. How to find out the health status of a used hard drive or SSD. What is S. M. A. R. T and what do its indicators say: Value, Worst, Raw, Threshold?
2. What are bad blocks? How to install – how many bad sectors (bad blocks) are on my hard drive, can they be fixed, and most importantly, how to fix it?
3. What should I do if the operating system does not boot or freezes even after reinstallation, and the hard disk makes clicks and extraneous sounds during operation? Why does the chkdsk disk check utility run every time Windows boots?
How to use one of the legendary hard drive diagnostic programs called Victoria!

Greetings friends on our website remontcompa.ru! Today’s article is about the Victoria program. I can say with confidence that this program is the best among utilities for diagnosing and treating hard drives. This creation was developed by the sorcerer of the first category Sergey Kazansky.
I have been preparing for this article for a very long time and feeling grateful for this program. Sometimes Victoria saved seemingly already lost data on the hard drives of my clients, friends and acquaintances (often the master does NOT have the task of returning a faulty hard drive to normal operation, but only to save the data on it), and sometimes brought the hard drive itself back to life!
Friends, it is impossible to put everything that I want to tell and show about the Victoria program in one article. As a result of my efforts, it turned out:
First, there are two main versions of the Victoria program:
version will allow us to diagnose and repair hard drives directly in running Windows, but I want to say that it is possible to diagnose a hard drive using this version, but fixing bad sectors (remap) often ends in failure, and the likelihood of errors when working with Victoria directly “from Windows” is present, so many experienced users and professionals prefer the second version of the program.
the version of the Victoria program will be on a boot disk or flash drive, from this disk (flash drive) we will boot our desktop computer or laptop and also carry out diagnostics and, if necessary, treat the hard drive.
The second version will be very useful to many, since most users have one hard drive in a computer, or even more so in a laptop, in this case, you can boot from Victoria’s disk (flash drive) and work with one single hard drive.
1. Victoria on the boot disk is very useful if you cannot start the operating system due to bad blocks.
2. If you have one hard drive and an operating system is installed on it and you run Victoria in the same operating system, then it will most likely refuse to fix bad sectors (bad blocks).
Many users will notice that often even Victoria will not fix a good bad, to which you can answer as follows – not all bads are of a physical nature (a broken sector on the hard disk), many bads are of a logical nature and can be easily fixed by this program.
all the details about the existing bad blocks of hard drives, what they are, logical or physical, read our article – How to check the status of a hard drive.
Briefly, I will only say that physical bads (a physically destroyed sector) cannot be restored, but logical ones (software, sector logic errors) can be restored.
Friends, you can talk a lot, but there is a good proverb in life: “It is better to see once than hear a hundred times”, so I will give you a few examples of the work of the Victoria program.
Victoria to work from a boot disk
We go to the official website of the program and select the Victoria 3.5 Russian ISO image of the bootable CD-ROM.
We also need Victoria on the boot disk, but we will consider working with this version in the second place. If you do not have a floppy drive, then we will make a bootable USB flash drive with the Victoria program.

Victoria to work directly in the operating system Windows XP, 7, 8, 10
We also download the version for Windows on my cloud.
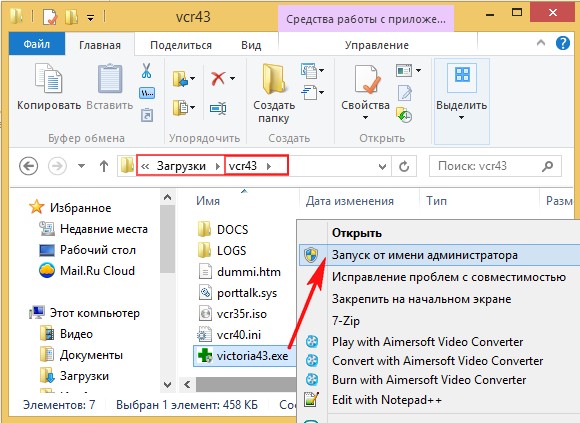
Right-click on the downloaded program archive and select Extract files.
The files are extracted to the created vcr43 folder. We go into this folder and be sure to run the executable file of the program victoria43.exe as an administrator.
Main program window
In the main window of the program, let’s go through all the tabs superficially, and then in detail.
Select the initial tab. If you have several hard drives, then in the right part of the window, select the hard drive you need with the left mouse and the passport data of our hard drive will immediately be displayed in the left part of the window: where you were born and married, model, firmware, serial number, cache size, and so on. At the bottom is a log of our actions.

What is S.M.A.R.T.
Then select the hard disk we need in the right part of the window, if you have several of them, and select it with the left mouse. Let’s choose, for example, a WDC WD5000AAKS-00A7B2 hard drive (500 GB).

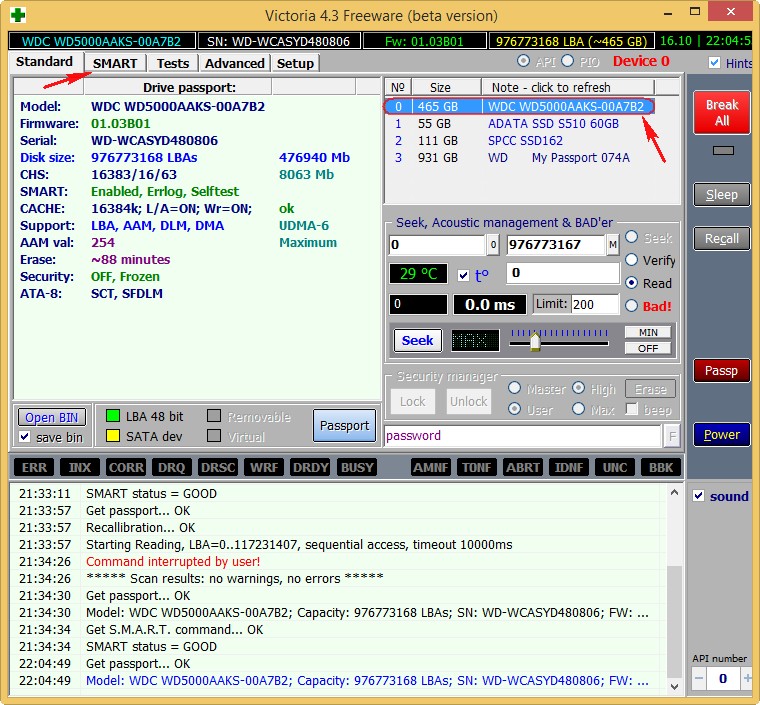
Go to the SMART tab, press the Get SMART button, the message GOOD will light up to the right of the button and the S. M. A. R. T. of the hard drive we have selected will open.
S. M. A. R. T. (from the English self-monitoring, analysis and reporting technology) – an advanced technology for self-monitoring, analysis and reporting of the hard drive developed in 1995 by the largest hard drive manufacturers.
In other words, friends, if you look at this window, you can find out what state your hard drive is in.
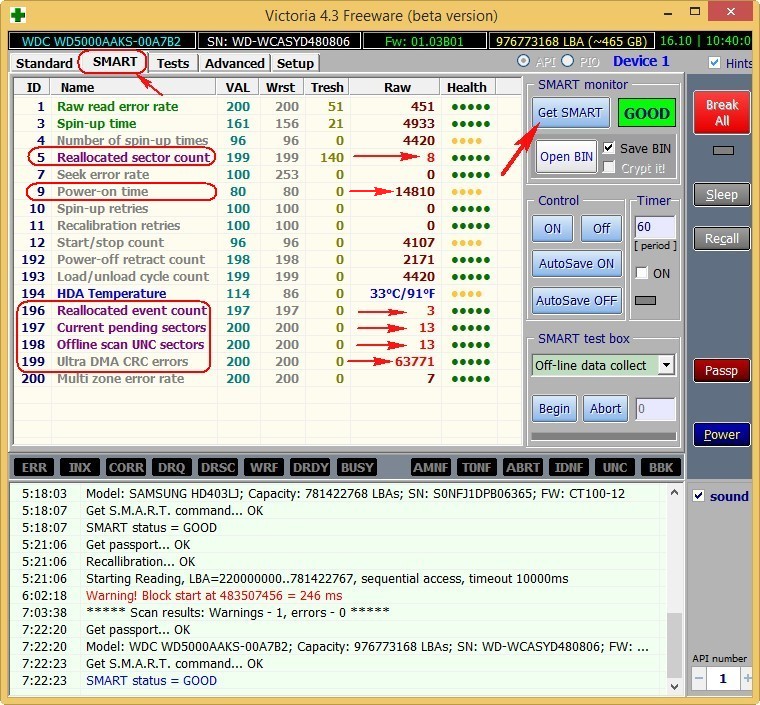
Pay attention to the Victoria program highlighted in red (alarm!) the number on the value of , the most important attribute for the health of the hard disk
5 Reallocated Sector Count — (remap) indicating the number of reallocated sectors.
attribute value is very important, read why
In simple words, if the firmware built into the hard drive detects a bad sector (bad block), then it will remap this sector as a sector from the backup track (the process is called remapping). But there are not an infinite number of spare sectors on the hard disk, and the program warns us that soon there will be nothing to reassign bad blocks, and this is fraught with data loss and we need to get ready to change the hard disk to a new one. Looking ahead, I will say that in the next article we will try to heal this hard drive.
– the total number of hours worked by the hard drive is not highlighted in red, but I want to say that approaching the figure of 20,000 hours of operation in most cases is associated with diseases and unstable operation of the hard drive.
Also attributes:
Reallocation Event Count — . The number of operations for reassigning bad blocks to sectors from backup tracks (remapping), both successful and unsuccessful operations are taken into account.
Current Pending Sector – An indicator of the number of unstable sectors of real contenders for bad blocks. The firmware of the hard disk plans to replace these sectors in the future with sectors from the reserve area (remap), but there is still hope that in the future some of these sectors will be read well and will be excluded from the list of applicants.
Offline scan UNC sectors — . The number of non-reassigned bads actually existing on the hard disk (possibly fixable having a logical structure – details later in the article).
UltraDMA CRC Errors – Errors that occur when transmitting information via an external interface, the reason is a possibly twisted and poor-quality SATA cable and it needs to be replaced or a loose SATA connector on the motherboard or on the hard drive itself. Or maybe the SATA 6 Gb / s interface hard drive itself is connected to the connector on the SATA 3 Gb / s motherboard, you need to reconnect it.
S. M. A. R. T attributes and their meanings. It’s very important to know!
— the current value of the attribute, it should be high (up to 255), if the Val value is equal to the critical Tresh or even less than it, then this corresponds to an unsatisfactory assessment of the parameter. For example, in our case, on a WDC WD5000AAKS-00A7B2 (500 GB, 7200 RPM, SATA-II) hard drive, the Reallocated Sector Count attribute has the value Val—, and the Tresh attribute (threshold) has the value , this is bad, but the value is not yet equal to value (threshold) and we have time to copy the data from this disk and send it to retirement.
— the lowest attribute value for the entire time the hard drive has been in operation.
—attribute threshold value, this value must be much lower than the value (current value).
“raw value”, which will be recalculated into the Value value, the smaller this value, the Important indicator for evaluation , represents the real number, based on which the Value value is formed, but exactly how the value formation process takes place is a proprietary secret of each hard drive manufacturer
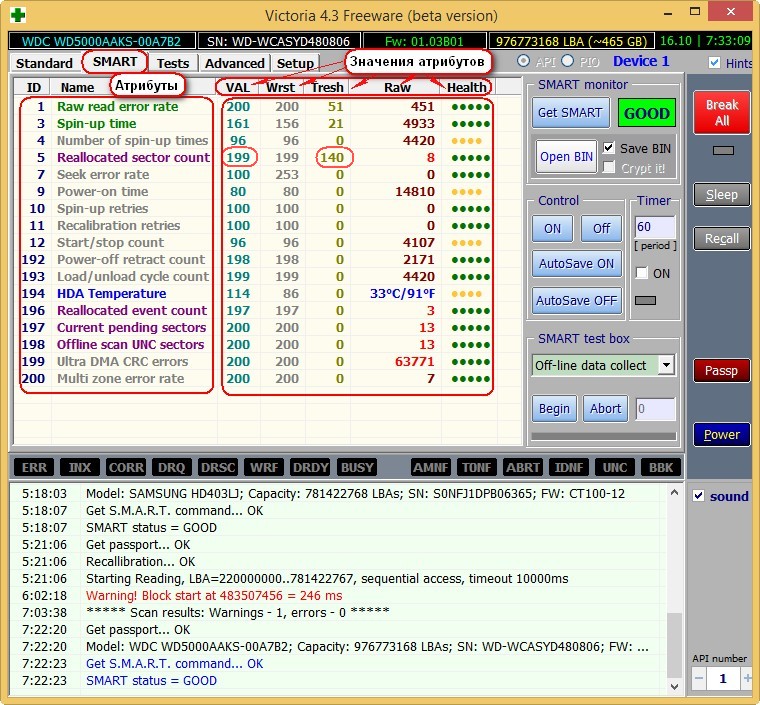
Let’s look at all the attributes of S. M. A. R. T, but I want to say that most often on “bad” hard drives, this Reallocated Sector Count attribute will be unsatisfactory. This is already a reason to be wary and test the surface of a hard drive or SSD (we will learn how to do this later in the article).
Select Shizuku Edition (exe).
In this window, you can select the language of the program in Russian.
As you can see, CrystalDiskInfo directly indicates to us (confirming Victoria’s fears) that the WDC WD5000AAKS-00A7B2 hard disk (capacity 500 GB) has bad values of the attributes responsible for Reassigned sectors, Unstable sectors, Unrecoverable sector errors, highlighting them in yellow and points to those hard drive status in one word “Alarm”
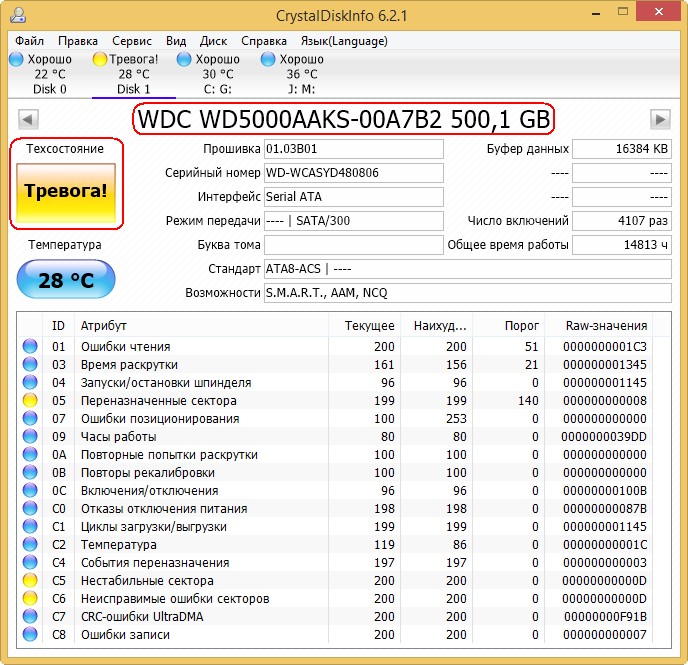
What the S. M. A. R. T of a failed hard drive looks like
And here is the S.M.A.R.T of the faulty WDC WD500BPVT hard drive of the laptop that was brought to me for repair.


Victoria from Windows. Pay attention to the attribute:
Reallocated Sector Count (reassigned sectors), it has the value -, and the attribute (threshold) has the value , this is unsatisfactory, since the value – should not be less than the limit value (threshold), that is, the number of bad sectors will increase, and there is nothing to reassign them, the spare sectors on the backup tracks have already ended.
Current Pending Sector – the indicator of the number of unstable sectors of real contenders for bad blocks has gone off scale.
And most importantly, self-esteem (unsuitable).
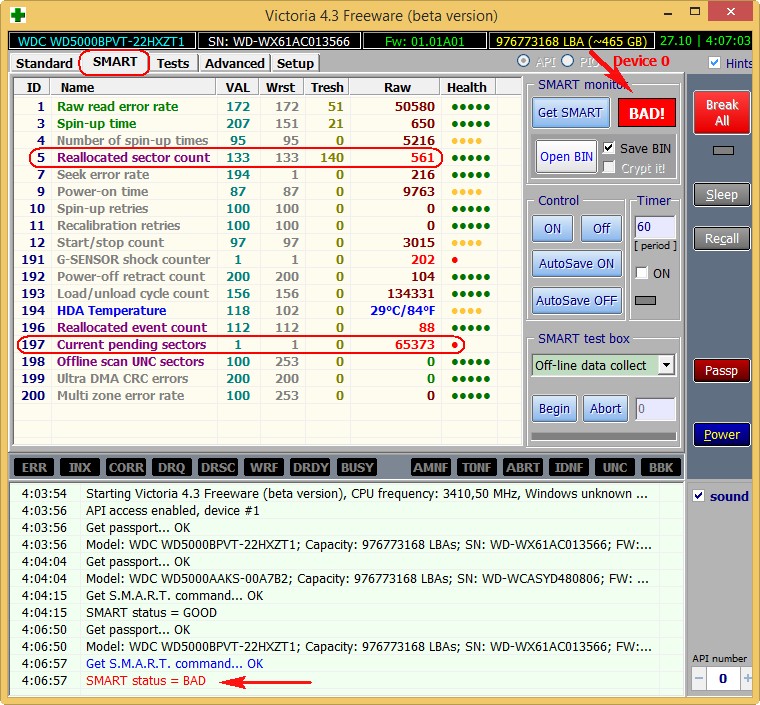
CrystalDiskInfo program (download link just above). We see the same thing, the Reallocated Sector Count attribute has a value of Val (current) – 133, and the Tresh attribute (threshold) has a value of 140, the program evaluated the assessment of those hard disk states as .
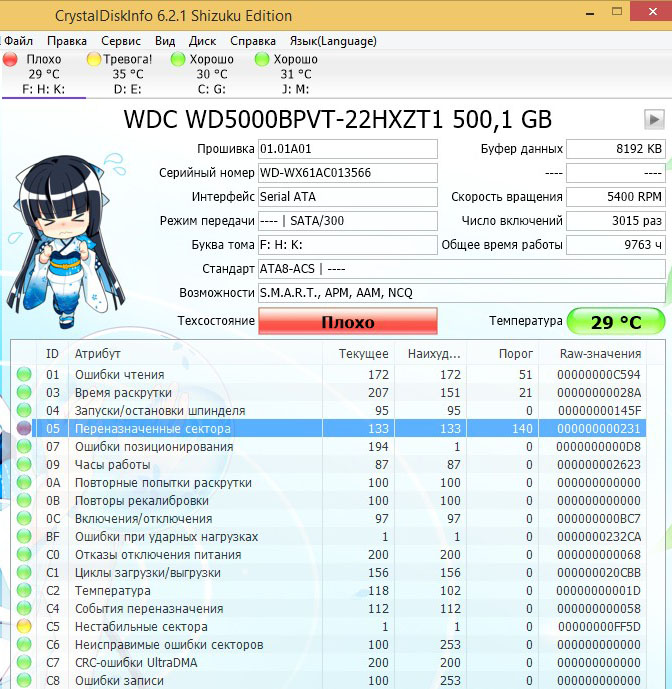
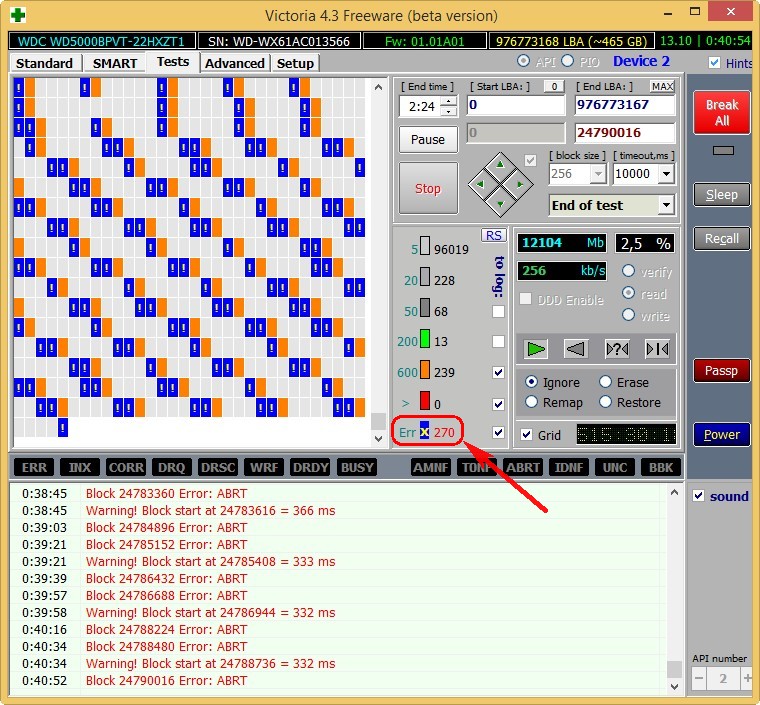
this laptop is terribly slow, data cannot be copied from it, Windows cannot be reinstalled, the hard drive periodically disappears from the BIOS, that is, such a hard drive must be replaced without hesitation, even our Victoria will not be able to completely cure such a screw, since healthy sectors on the backup tracks are over and there is nothing to reassign bad sectors, and copying data from it will be a real adventure for a week (I will definitely write an article about this).
Looking ahead, I will say that the test of this screw in the Victoria program showed the presence of 500 uncorrectable bad sectors (bad blocks).
DOS is a version of the Victoria program.

To make life easier for you, some hard drive diagnostic programs map each attribute, good or bad, to an icon color.
—Hard disk attribute is normal.
– indicates a slight discrepancy with the standard and it is better not to store important data on this screw, if you have Windows on such a hard drive, transfer it to an SSD.
– indicates a significant discrepancy with the standard and the hard drive had to be changed yesterday.
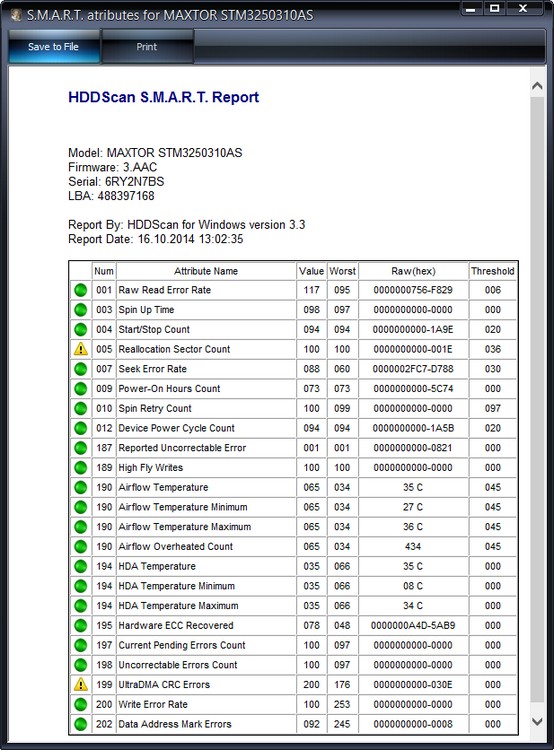
S. M. A. R. T of the same WDC WD500BPVT hard drive in HDDScan
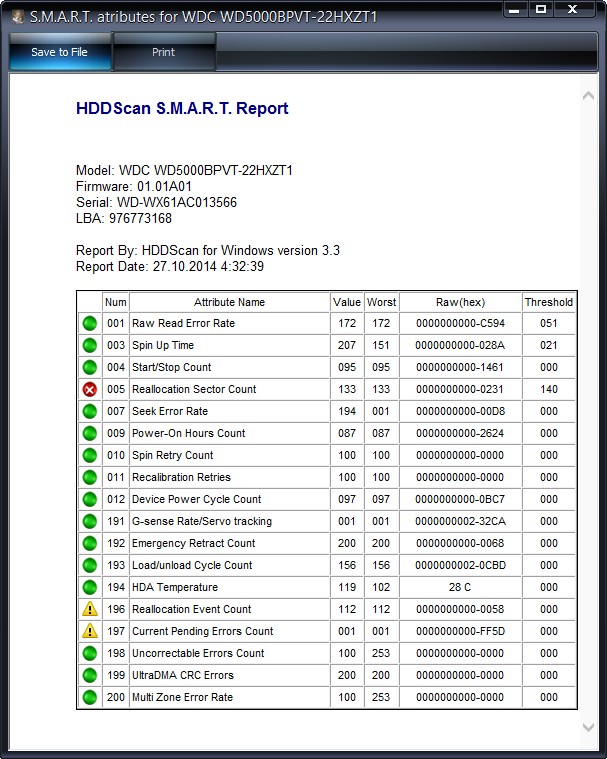
001 Raw Read Error Rate—error rate when reading information from a disk
002 Spinup Time—disc spinup time to working state
003 Start/Stop Count—The total number of starts/stops of the spindle.
005 Reallocated Sector Count – (remap) indicates the number of remapped sectors. If the firmware built into the hard drive detects a bad sector (bad block), then it will reassign this sector as a sector from the backup track (the process is called remapping). But there are not an infinite number of spare sectors on the hard disk, and the program warns us that soon there will be nothing to reassign bad blocks, and this is fraught with data loss and we need to get ready to change the hard disk to a new one
007 Seek Error Rate—the error rate when positioning the head unit, a constantly growing value, indicates the overheating of the hard drive and an unstable position in the basket, for example, it is poorly fixed.
009 Power-on Hours Count—The number of hours spent in the power-on state.
010 Spin Retry Count—The number of times the disk spins up to operating speed when the first one fails.
012 Device Power Cycle Count—Number of complete drive on/off cycles
187 Reported Uncorrectable Error—Errors that the hard drive firmware could not recover using its hardware error recovery methods, the effects of overheating and vibration.
189 High Fly Writes—The write head was above the surface higher than necessary, which means that the magnetic field was insufficient to reliably write the media. The reason is vibration (shock).
For laptops, this figure is slightly higher.
190 Important parameters regarding temperature. It is important that the temperature does not rise above 45 degrees.
194 HDA Temperature—temperature of the mechanical part of the hard drive
195 Hardware ECC Recovered—number of errors that were fixed by the hard drive itself.
Reallocation Event Count — The number of operations for reassigning bad blocks to sectors from backup tracks (remapping), both successful and unsuccessful operations are taken into account.
197 Current Pending Errors Count – uncorrectable sector errors, also an important parameter, the number of sectors, the reading of which is difficult and is very different from reading a normal sector. That is, the hard disk controller could not read these sectors the first time, usually soft bads belong to these sectors, they are also called software or logical bad blocks (sector logic error) – when writing user information to the sector, service information is also recorded , namely the ECC sector checksum (Error Correction Code), it allows you to recover data if they were read with an error, but sometimes this code is not written, which means that the sum of user data in the sector does not match the ECC checksum. For example, this happens when the computer is suddenly turned off due to power failures, because of this, information was written to the hard disk sector, but there is no checksum.
198 Offline scan UNC sectors – The number of unreassigned bads actually existing on the hard disk (possibly fixable having a logical structure – details later in the article).
198 Uncorrectable Errors Count—number of uncorrectable errors when accessing a sector, indicates surface defects.
Reported Uncorrectable Errors – shows the number of uncorrected bad sectors.
199 UltraDMA CRC Errors—the number of errors that occur when transmitting information via the external interface, the reason is a twisted and poor-quality SATA cable, it may need to be changed.
200 Write Error Rate—the frequency of errors that occur when writing to a hard drive, this indicator is usually used to judge the quality of the surface of the drive and its mechanical part.
202 Data Address Mark Errors—I have not seen any decryption anywhere, literally an address marker data error, it may mean that only the manufacturer of this hard drive knows.
How to quickly check the hard drive or SSD for workability?
Friends, you often ask me: “How to quickly check a hard drive or SSD for suitability for work?”
Answer: “Use the programs: Victoria, CrystalDiskInfo, HDDScan, they will immediately show you the S. M. A. R. T of any hard disk.
What the S.M.A.R.T of a brand new hard drive looks like
First, see what the S.M.A.R.T of a brand new hard drive looks like

As you can see, all indicators of the drive are in excellent condition and it worked for zero hours (Power-On Time parameter)
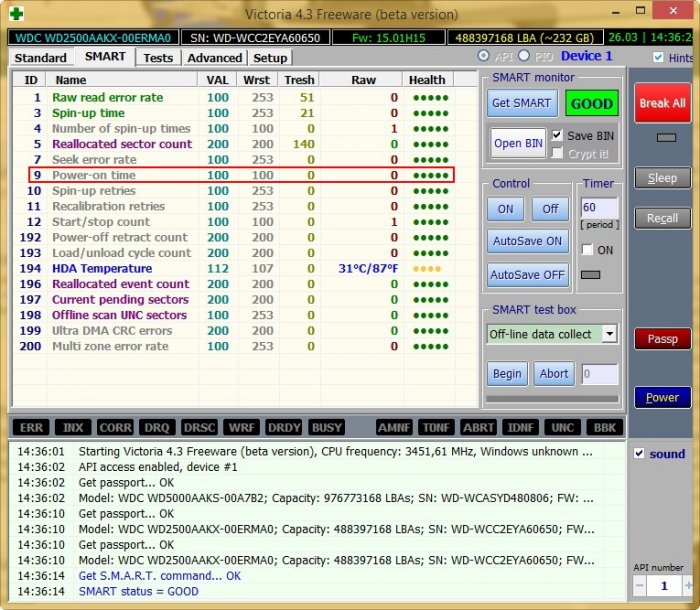
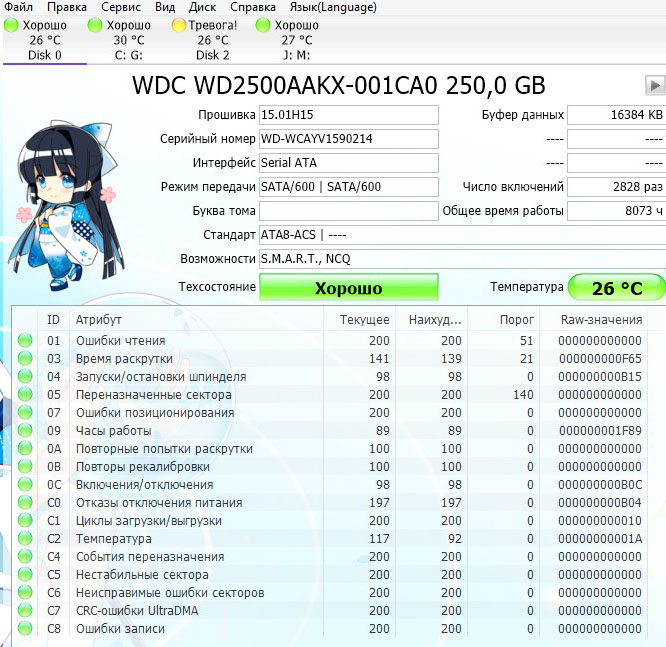
Now we take an almost new hard drive WDC WD2500AAKX-001CA0 and look at S. M. A. R. T, as we can see, the hard drive is almost in perfect condition, although it has already worked for 8000 hours (parameter

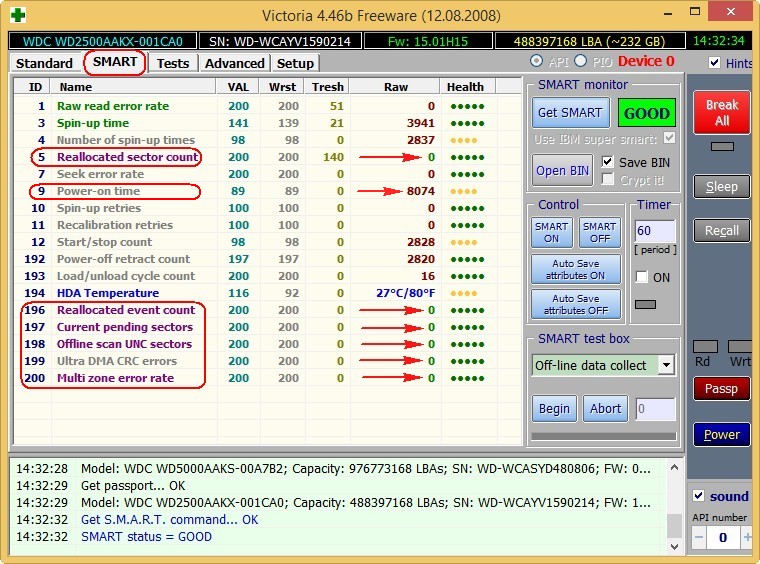
Hard Disk Surface Test!
On the right side of the program window, check the item and item and click . This will run a simple hard drive surface test without error correction. This test will not bring any negative and positive effects on the hard drive, but after the test is over, you will know what condition your hard drive is in.
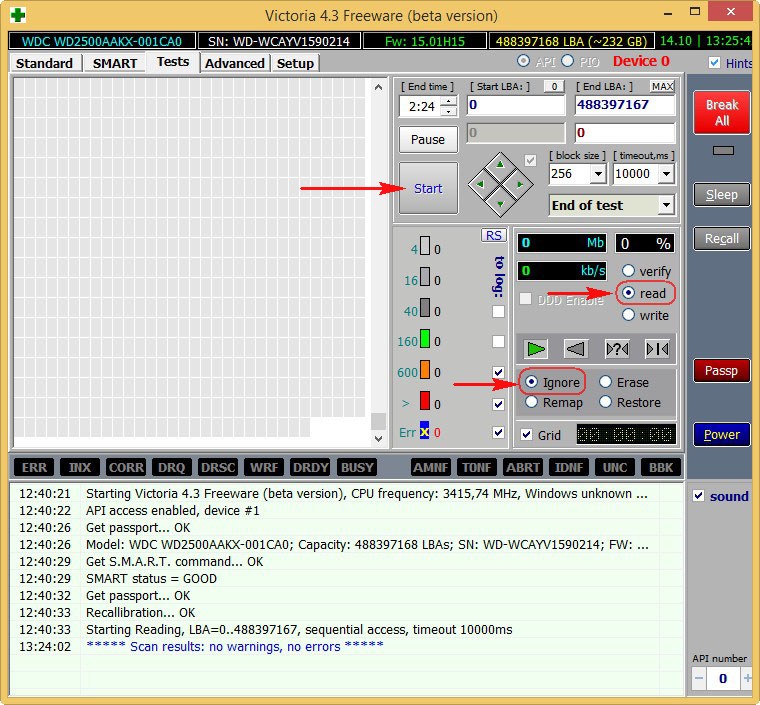
The test results are excellent. Not a single block with a delay of more than 30 ms!


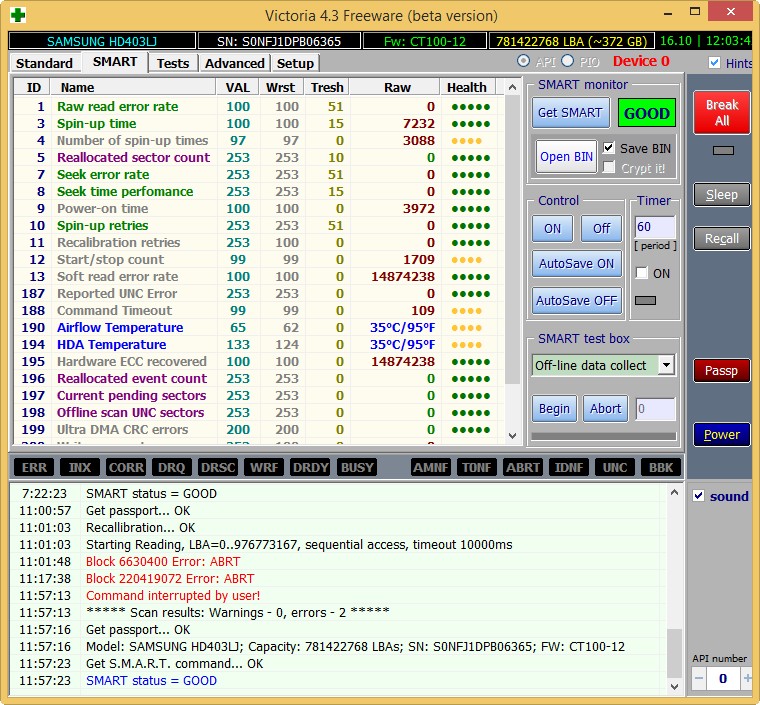
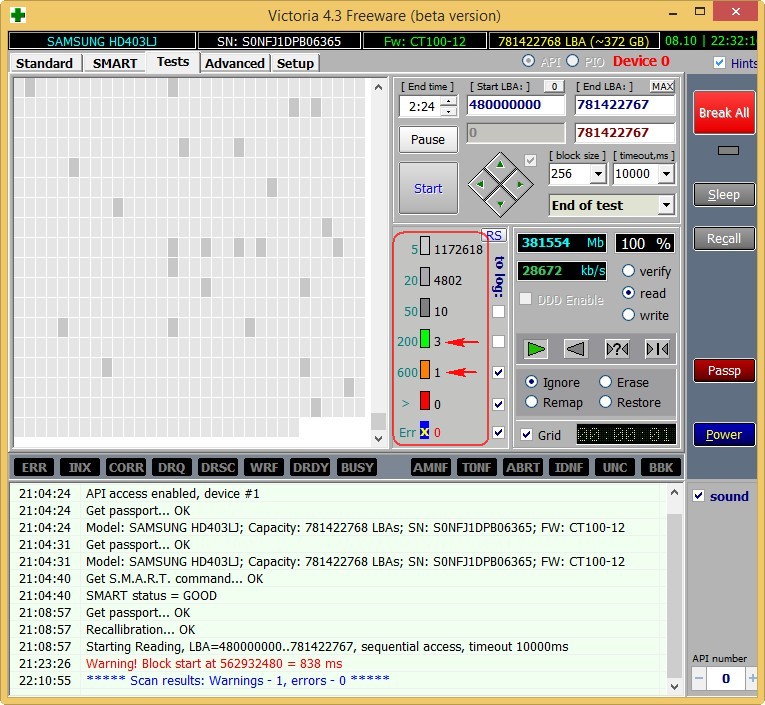
Hard drive SAMSUNG HD403LJ (372 GB) from a recent article How to transfer Windows 7, 8, 8.1 to SSD using Acronis True Image.
It had bad blocks and I had to transfer Windows 8 from it to an SSD, after a successful transfer, the owner (my classmate) gave me this screw and Victoria soon brought it back to life after “recording all over the meadow” (algorithm write). The former owner refused to take the cured hard drive.

The test results are slightly worse. 3 blocks with a delay of more than 200 ms and 1 block with a delay of 600 ms (possibly a bad candidate).
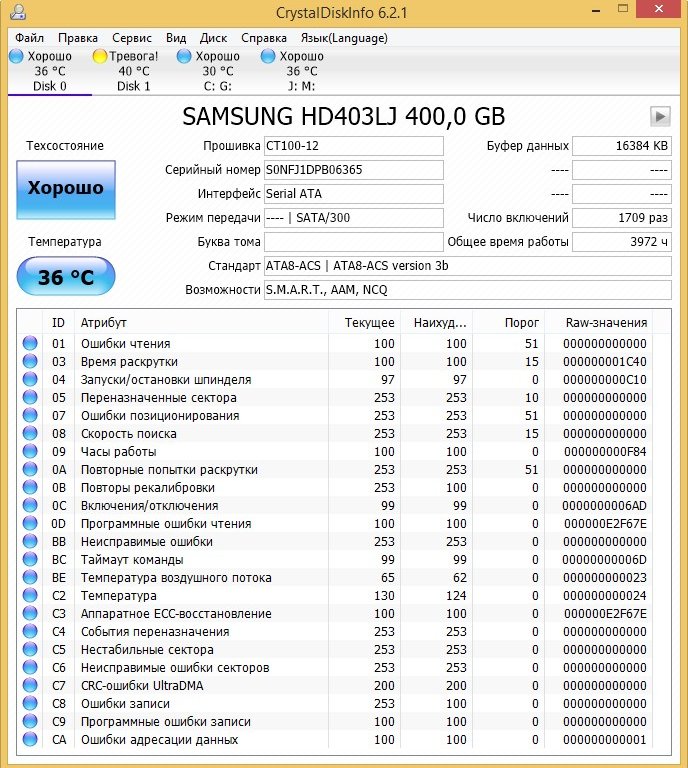

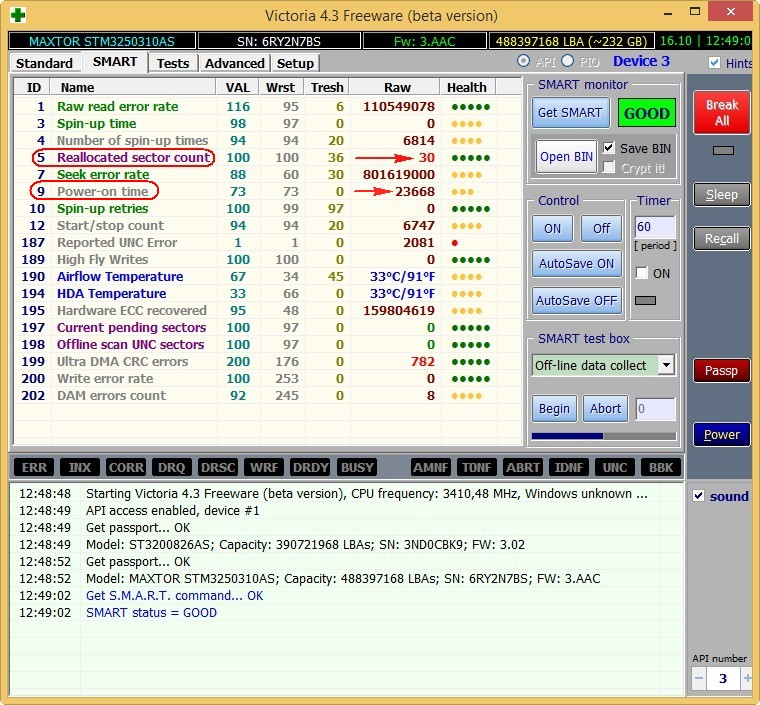
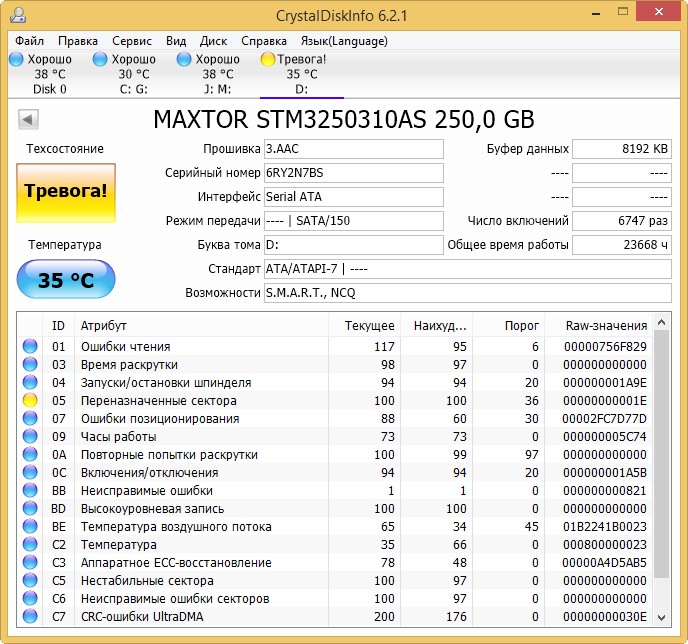
Not quite serviceable hard drive MAXTOR STM3250310AS (250 GB, 7200 RPM, SATA-II) it is 8 years old (veteran) and it still works, though I save it, I store only files of unimportant data on it.

Although there are no obvious bads on it, we see that the Reallocated Sector Count — (remap) attribute, which indicates the number of remapped sectors, is critical and soon there will be nothing to reassign bads.
– the total number of hours worked by the hard drive, this is a lot, usually problems with hard drives begin after 20,000 hours of work.
Also, the unimportant UltraDMA CRC Errors attribute is errors that occur when transmitting information via an external interface, the reason is a poor-quality SATA cable and it needs to be replaced (this is not always the case).
The test results are even worse. 71 blocks with a delay of more than 200 ms and 1 block with a delay of 600 ms (possibly a candidate for bad).
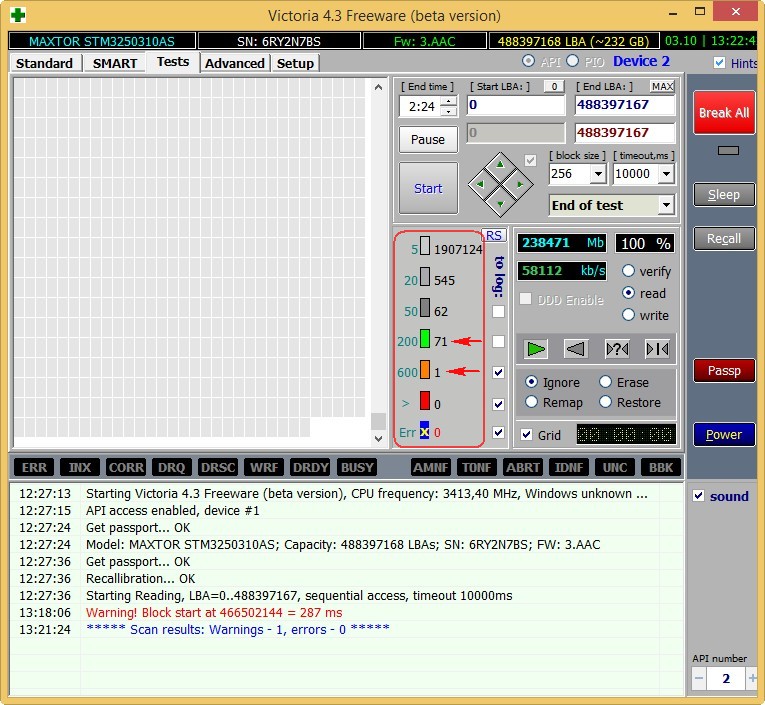
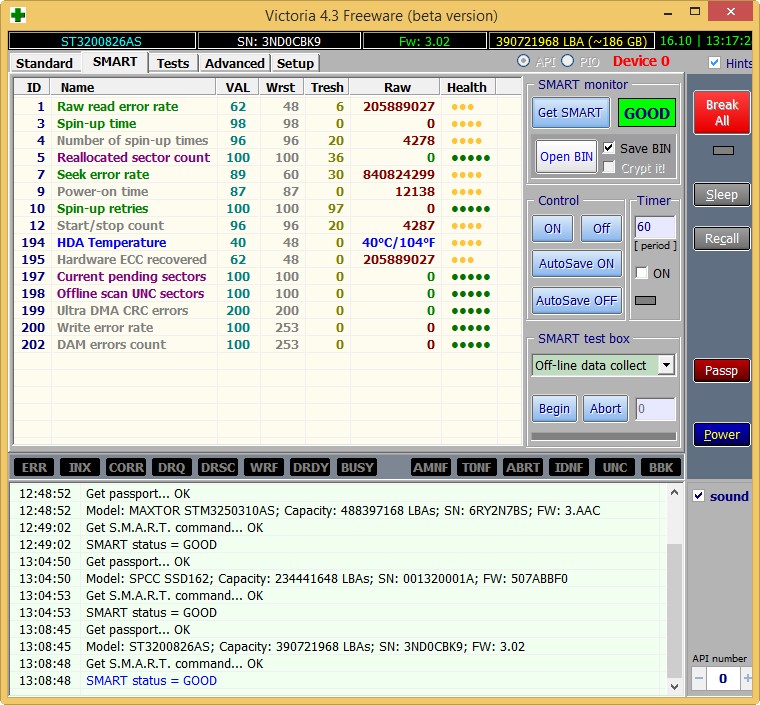
Hard drive ST3200826AS (200 GB, 7200 RPM, SATA). The screw is about three years old and the flight is still normal.

Test results. 6 blocks with a delay of more than 200 ms.
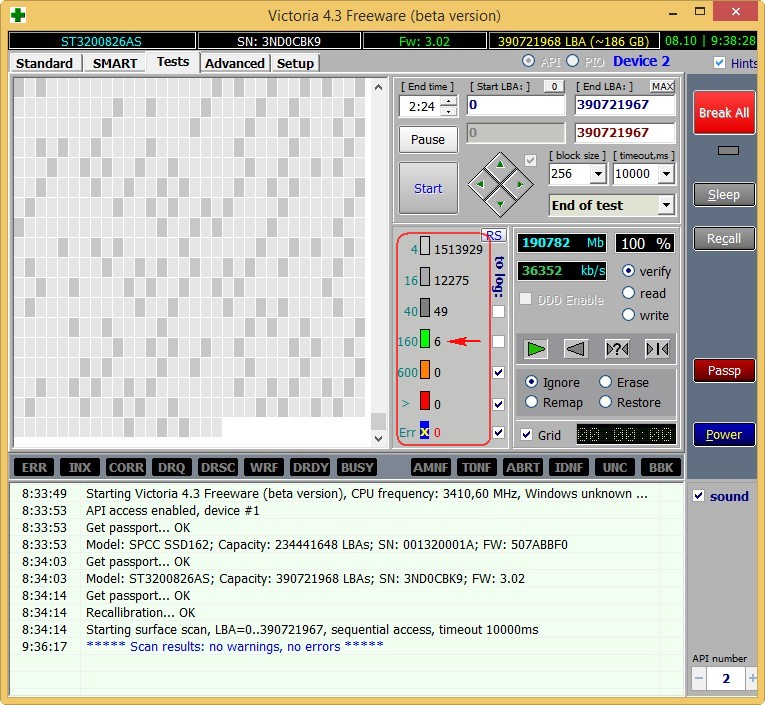
New SSD SPCC SSD162

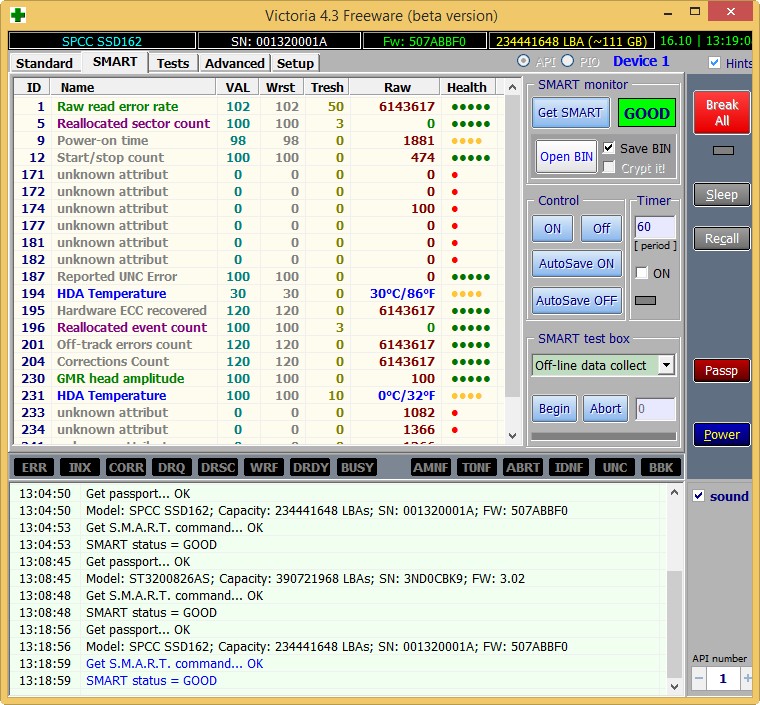
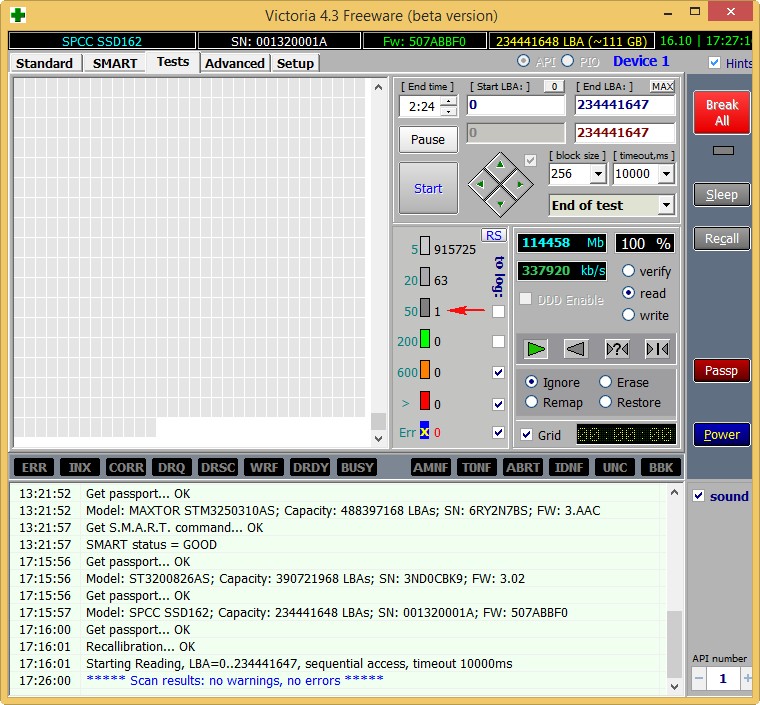
At the end of the article, check out my oldest SSD – ADATA S510 60GB (60 GB, SATA-III)
It is already the third year, but it works perfectly, it’s a pity that the volume is only 60 GB, but when I bought it there was no more, and it cost about two hundred bucks.

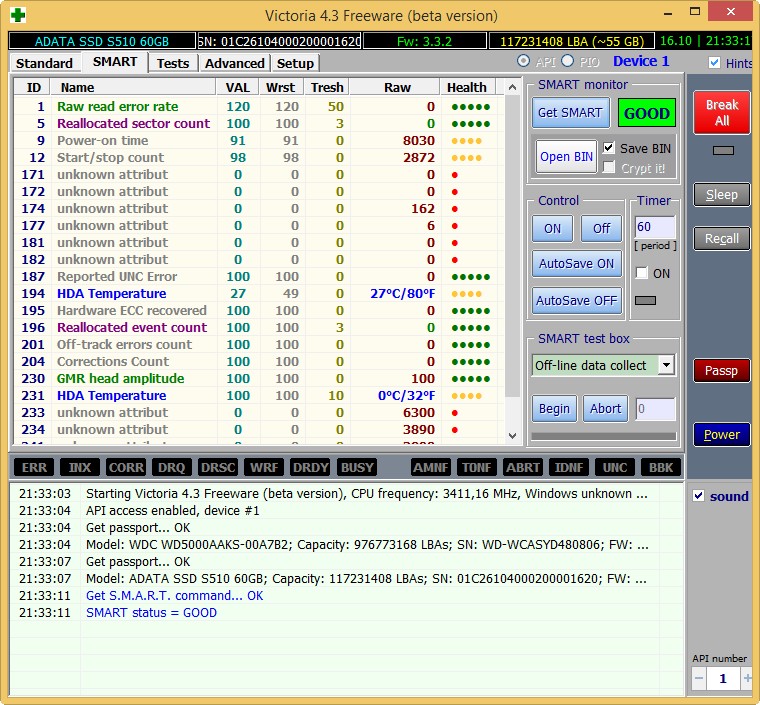
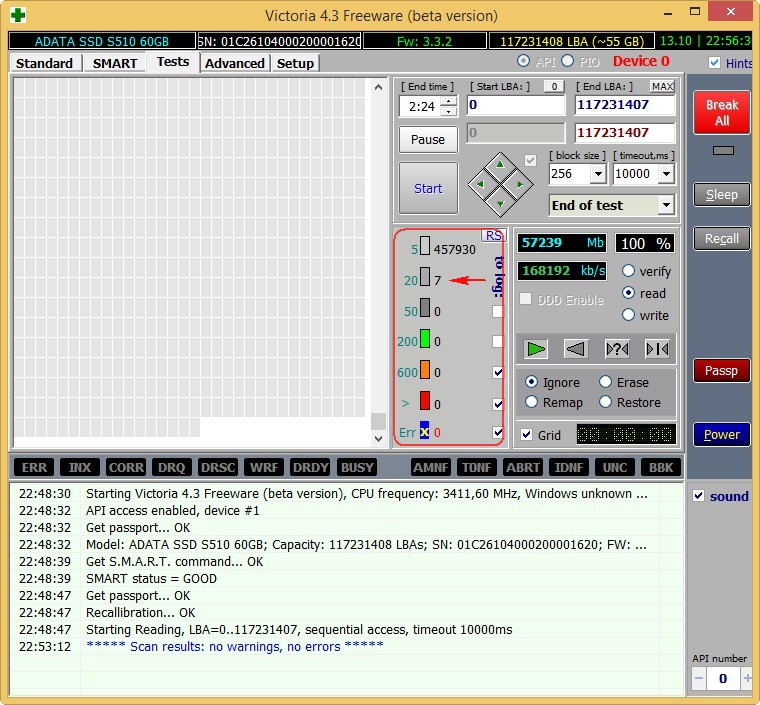
Restore the hard drive using special programs. They allow you to test the hard drive, as well as fix minor malfunctions. Often, this is quite enough to continue fruitful work. From the article you will learn about one of them called Victoria.
Checking your hard drive with Victoria is completely free. Also, the program has many functions and is designed not only for professionals, but also for inexperienced users. So, now you will learn how to check the hard drive with Victoria.
Technology S.
All modern hard disk drives support the technology of self-testing, status analysis, and the accumulation of statistical data on the deterioration of their own characteristics S. M. A. R. T. (Self-Monitoring Analysis and Reporting Technology). The foundations of S.M.A.R.T. were developed in 1995 by a collaborative effort between leading hard drive manufacturers.
In the process of improving the equipment of drives, the capabilities of the technology were also refined, and after the SMART standard, SMART II appeared, then SMART III, which, obviously, will not be the last either.
A hard disk in the course of its operation constantly monitors certain parameters of its state and reflects them in special characteristics – attributes (Attribute), which, as a rule, are stored in a specially allocated part of the disk surface, accessible only to the internal firmware of the drive – the service area. Attribute data can be read by special software.
Attributes are identified by their digital number, most of which are interpreted in the same way by drives of different models. Some attributes may be specific to the hardware manufacturer and may only be supported by certain drive models.
Attributes consist of several fields, each of which has a specific meaning. Usually, S. M. A. R. T. reader programs give a transcript of attributes in the form:
To analyze the state of the drive, perhaps the most important attribute value is Value — a conditional number (usually from 0 to 100 or up to 253) set by the manufacturer. The Value value is initially set to the maximum when the drive is manufactured and decreases as the drive degrades. For each attribute, there is a threshold value, until which the manufacturer guarantees its performance – the Threshold field. If the Value value approaches or becomes less than the Threshold value, it’s time to change the drive. The list of attributes and their values are not strictly standardized and are determined by the drive manufacturer, but the most important of them are interpreted in the same way. For example, an attribute with identifier 5 (Reallocated sector count) will characterize the number of disk sectors rejected and reassigned from the spare area, both for Seagate devices and for Western Digital, Samsung, Maxtor.
The hard drive does not have the ability, on its own initiative, to transmit SMART data to the consumer. Their reading is performed by special software.
In the settings of most modern motherboard BIOS there is an item that allows you to disable or enable the reading and analysis of SMART attributes during hardware tests before the system boots. Enabling this option allows the BIOS hardware test subroutine to read the values of critical attributes and, if the threshold is exceeded, warn the user about it. As a rule, without much detail:
Primary Master Hard Disk: S. M. A. R. T status BAD!, Backup and Replace.
The execution of the BIOS routine is paused to attract attention:
Press F1 to Resume
Thus, without installing or running additional software, it is possible to timely determine the critical state of the drive (when this option is enabled) using the Basic Input/Output System (BIOS).
Похожее:
 Alt-коды для Windows
Alt-коды для Windows  «Мне требуется помощь в решении проблемы с моим ноутбуком ASUS, который отображает сообщение о критическом состоянии резервной копии смарт-статуса, сопровождаемое предложением заменить его. Кроме того, он предлагает мне нажать F1 для возобновления работы. Пожалуйста, посоветуйте потенциальное решение для преодоления этой проблемы»
«Мне требуется помощь в решении проблемы с моим ноутбуком ASUS, который отображает сообщение о критическом состоянии резервной копии смарт-статуса, сопровождаемое предложением заменить его. Кроме того, он предлагает мне нажать F1 для возобновления работы. Пожалуйста, посоветуйте потенциальное решение для преодоления этой проблемы»  Как пользоваться программой по диагностике жёстких дисков под названием Victoria?
Как пользоваться программой по диагностике жёстких дисков под названием Victoria?  Сдать общий анализ крови в Москве. Клинический анализ крови. Общий анализ крови цена.
Сдать общий анализ крови в Москве. Клинический анализ крови. Общий анализ крови цена.