

Chcp 1251 что это: кодировка виндовс
На днях пришлось решать небольшую проблему с плохой восприимчивостью комплекта Denwer к кодировки UTF-8. Проблема, честно говоря, оказалась пустяковая, и была решена минут за 15, 10 из которых заняло использование Гугла. В этом время, исследуя различные форумы, я заметил, что для многие не могут разобраться с этой проблемой достаточно долго. Кроме того, понял, что многих интересует зачем вообще использовать UTF-8, если есть прекрасная такая “русская” кодировка Windows-1251. Вот и решил написать пару постов на эту тему. Начну я с общего описания данных кодировок, а продолжу, непосредственно, описанием решения проблемы использования UTF-8 на пакете Denwer.
Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них:
- большинство современных веб-платформ по-умолчанию работают именно на ней;
- её очень удобно использовать для создания мультиязычных проектов;
- набор используемых в кодировки символов около 100000;
- кодировка универсальная, т.е. русские символы и в Никарагуа остаются русскими.
Далее постараюсь написать несколько слов об основных отличиях кодировок Windows-1251 и UTF-8, а так же, в качестве бонуса, примеры объявления кодировки в HTML, PHP и для работы с базами данных MySQL.
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251.
Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
- UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
- использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
- Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8…
А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); “С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
Faq: проблема с кодировкой шрифта в командной строке windows
Иногда в интерпретаторе командной строки cmd.exe вместо русских букв выводятся непонятные символы (“кракозябры” или “сломался шрифт”). Как восстановить (поменять) кодировку текста? Последний раз автор столкнулся с этой проблемой после добавления нужных шрифтов в папку C:WindowsFonts. Ниже – о простом и быстром, без коррекции системного реестра, способе избавиться от “кракозябликов” в командной строке (скриншоты от лица Windows 7).
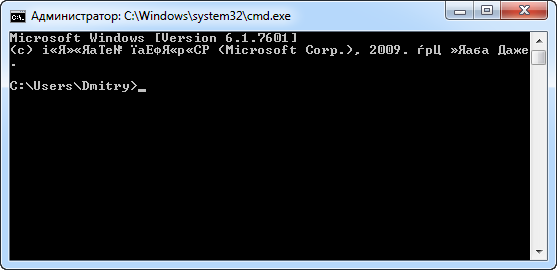
Чтобы расшифровать кириллицу, запустим cmd (в Windows 10 через меню “Пуск” и “Все приложения“) → правой кнопкой мыши кликнем по верхней части окна → в выпавшем меню найдем “Свойства” → в одноименном окне на вкладке “Шрифт” сменим “Точечные шрифты” на любой другой → “ОК“.
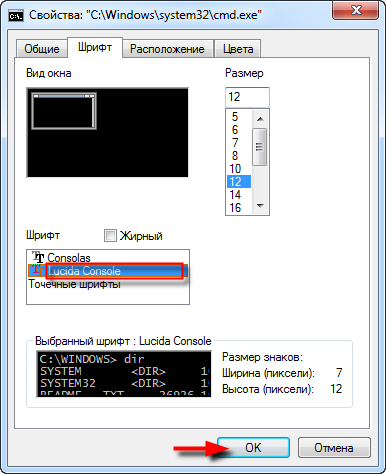
При желании, для комфортного восприятия можно поэкспериментировать со шрифтами, их размером, жирностью (чекбокс “Жирный”, см. скриншот), а также размером курсора (вкладка “Общие“), расположением и размером окна (вкладка “Расположение“), цветом текста и фона как экрана, так и всплывающего окна консоли Windows (вкладка “Цвета“).
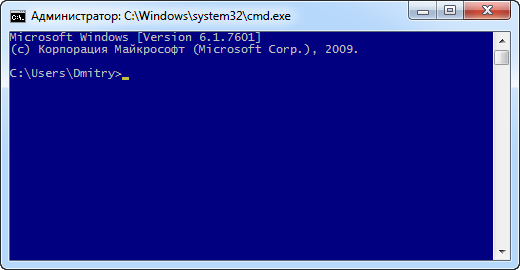
На последнем скриншоте – cmd.exe с темно-синим фоном. Кстати, всегда можно узнать текущую кодировку шрифта, набрав в консоли chcp→ “Enter” (по умолчанию это cp866 или DOS-кодировка).
Дмитрий Евдокимов
www.TestSoft.su



