

Для данной задачи существует множество решений. Если вам нужно быстрое и не обязательно универсальное решение, чтобы сильно не разбираться, прокручивайте к разделу «Менее правильные, но пригодные решения».
При работе с Windows 10 у пользователей иногда возникают проблемы с правильным отображением символов. Вместо привычных букв и цифр в тексте мы можем лицезреть какие-то замудрённые иероглифы или «кракозябры», которые не несут в себе никакого логического смысла. Чаще всего к этому приводят неправильно установленные значения в опциях региональных параметров.
Нередко такое случается, когда пользователь работает с русской раскладкой клавиатуры в ОС с английской локализацией. Проблема заключается в том, что в такой системе для программ, работающих с кириллицей, не предусмотрена обработка нужных символов. Также это справедливо и для других языков, в которых отсутствуют латинские символы, например, японского, китайского или греческого.
Сегодня мы поговорим о том, как избавиться от кракозябр в Windows 10 и настроить корректное отображение русских символов.
Методы, которые работают плохо (но могут помочь вам)
Метод, который часто рекомендуют — использование конструкции setlocale(LC_ALL, “Russian”); У этого варианта (по крайней мере в Visual Studio 2012) гора проблем. Во-первых, проблема с вводом русского текста: введённый текст передаётся в программу неправильно! Нерусский текст (например, греческий) при этом вовсе не вводится с консоли. Ну и общие для всех неюникодных решений проблемы.
Ещё один метод, не использующий Unicode — использование функций CharToOem и OemToChar. Этот метод требует перекодировки каждой из строк при выводе, и (кажется) слабо поддаётся автоматизации. Он также страдает от общих для неюникодных решений недостатков. Кроме того, этот метод не будет работать (не только с константами, но и с runtime-строками!) на нерусской Windows, т. к. там OEM-кодировка не будет совпадать с CP866. В дополнение можно так же сказать что эти функции поставляются не со всеми версиями Visual Studio — например в некоторых версиях VS Express их просто нет.
Вот выдержка из документации к Питону 3.5.1:
Python » 3.5.1 Documentation » The Python Standard Library » 29. Python Runtime Services » sys
The character encoding is platform-dependent.
Under Windows, if the stream is interactive (that is, if
its isatty() method returns True), the console codepage is
used, otherwise the ANSI code page.
Under other platforms, the locale encoding is used (see
locale.getpreferredencoding()).
Under all platforms though, you can override this value
by setting the PYTHONIOENCODING environment variable
before starting Python.
Далее, текущая кодировка консоли в Windows (для России это cp866), ну и строка для ANSI получаются вот так:
import ctypes
def ansi_encoding():
return ‘cp’+str(ctypes.windll.kernel32. GetACP())
def console_output_encoding():
return ‘cp’+str(ctypes.windll.kernel32. GetConsoleOutputCP())
Сделать консоль Windows юникодной можно командой chcp 65001.
Теперь про Pycharm: он устанавливает environment переменную
ну и консоль у него юникодная. Шрифт для консоли рекомендую DejaVu Sans Mono – единственный правильно выводит формулы из sympy.
Про то, что текст программы должен быть в utf-8, уже писали. Строчка про encoding не обязательно, но чтобы и питон 2 и питон 3 правильно выводили текст хоть на консоль, хоть в pycharm, программа должна выглядеть так:
# -*- encoding: utf-8 -*-
from __future__ import print_function
import sys
print(sys.version)
print(u’Здравствуй жопа, новый год!’)
Ситуация обстоит следующим образом: в качестве кодировки по умолчанию в вашей системе установлена 437. Это стандартная кодировка, разработанная в IBM для самых первых персоналок IBM PC предназначенных для США; в целях совместимости дожившая до наших времён. Она содержит только символы английского алфавита и некоторые греческие буквы. Она не содержит символы европейских языков (с умляутами и штрихами), и тем более не содержит символов кириллицы.
Так что, похоже, у Вас американская либо международная версия Windows.
Для того, чтобы показывать русский текст (кириллицу) необходимо переключиться на кодировку 866 (DOS), 1251 (Windows) или 65001 (UTF-8). Последняя кодировка универсальнее, поскольку позволяет показывать также и символы других алфавитов, не только русского и английского.
Вы можете переключить язык даже в английской версии Windows с помощью команды chcp.
Однако, это не всегда помогает, поскольку для отображения Unicode-символов необходим шрифт, содержащий глифы для этих символов. То есть помимо кодовой страницы для консоли необходимо установить также шрифт, например Lucida Console, вместо Terminal.
В любом случае, установка шрифтов и кодовой страницы — прерогатива всё-таки пользователя компьютера, а не разработчика программы. Разработчик (то есть Вы) со своей стороны можете сделать следующее:
После этого в английской, международной и прочих не-русских версиях программа будет показывать сообщения на английском. В русской версии Windows, где выбрана культура ru-ru и установлена кодировка CP1251 или CP65001 — программа будет выводить сообщения на русском.
Пользователи-французы, итальянцы, японцы — смогут подготовить ресурсы на своём языке, переведя их с английского. Эти ресурсы могут быть скомпилированы в DLL. Если скопировать эту DLL в каталог программы, она будет показывать сообщения например на итальянском в итальянской версии Windows. Замечу, что для этого не нужно иметь исходного кода Вашей программы, и вообще, от Вас не потребуется ничего — пользователю потребуется EXE или DLL с текстами по-умолчанию, чтобы сделать свой перевод этих текстов.
Выбор английского в качестве языка по умолчанию хорош тем, что этот язык по историческим причинам поддерживается всеми версиями Windows (и не только Windows).
Кодировки и веб-страницы
Время на прочтение
Возвращаясь к избитой проблеме с кодировками русских букв, хотелось бы иметь под рукой некий единый справочник или руководство, в котором можно найти решения различных сходных ситуаций. В своё время сам перелопатил множество статей и публикаций, чтобы находить причины ошибок. Задача этой публикации — сэкономить время и нервы читателя и собрать воедино различные причины ошибок с кодировками в разработке на Java и JSP и способы их устранения.
Варианты решения могут быть не единственными, охотно добавлю предложенные читателем, если они будут рабочими.
Итак, поехали.
1. Проблема: при получении разработанной мной страницы браузером весь русский текст идёт краказябрами, даже тот, который забит статически.
Причина: браузер неверно определяет кодировку текста, потому что нет явного указания.
Решение: явно указать кодировку:
a) HTML: добавляем тэг META в хидер страницы:
б) XML: указываем кодировку в заголовке:
в) JSP — задаём тип контента в заголовке:
г) JSP — задаём кодировку возвращаемой страницы
д) Java — устанавливаем хидер ответа:
2. Проблема: написанный в JSP-странице статический русский текст почему-то идёт краказабрами, хотя кодировка страницы задана.
Причина: статический текст был написан в кодировке, отличной от заданного странице.
Решение: изменить кодировку в редакторе (например, для AkelPad нажимаем «Сохранить как» и выбираем нужную кодировку).
3. Проблема: получаемый из запроса текст идёт кракозябрами.
Причина: кодировка запроса отличается от используемой для его обработки кодировки.
Решение: установить кодировку запроса или перекодировать в нужную.
а) Java, со стороны отправителя не задана нужная кодировка — перекодируем в нужную:
Примечание: кодировка ISO-8859-1 устанавливается по умолчанию, если не была задана другая.
б) Java, со стороны отправителя задана нужная кодировка — устанавливаем кодировку запроса:
4. Проблема: отправленный GET-параметром русский текст при редиректе приходит кракозябрами.
Причина: упаковка русского текста в URI по умолчанию идёт в ISO-8859-1.
Решение: упаковать текст в нужной кодировке вручную.
а) JSP, URLEncoder:
5. Проблема: текст из базы данных читается кракозябрами.
Причина: кодировка текста, прочитанного из базы данных, отличается от кодировки страницы.
Решение: установить соответствующую кодировку страницы, либо перекодировать полученные из базы данных значения.
а) Java, перекодирование считанной в db_string базы данных строки:
6. Проблема: текст записывается в базу данных кракозябрами, хотя на странице отображается правильно.
Причина: кодировка записываемой строки отличается от кодировки сессии работы с базой данных, либо от кодировки базы данных (стоит помнить, что они не всегда совпадают).
Решение: установить необходимую кодировку сессии или перекодировать строку.
а) Java, перекодирование записываемой строки db_string в кодировку сессии или базы данных:
б) Java, MySQL, настройка параметров подключения в строке dburl, передаваемой функции коннекта:
г) MySQL, прямая установка кодировки сессии вызовом SET NAMES (connect — объект подключения Connection):
Дополнение, или что нужно знать:
1. Кодировки базы данных и сессии подключения могут различаться, в зависимости от конкретной СУБД и драйвера. К примеру, при подключении к MySQL стандартным драйвером com.mysql.jdbc. Driver без явного указания кодировка сессии устанавливалась в UTF-8, несмотря на другую кодировку схемы БД.
2. Кодировка упаковки строки запроса в URI по умолчанию устанавливается в ISO-8859-1. С подобным можно столкнуться, например, при передаче явно заданного текста в редиректе с одной страницы на другую.
3. Взаимоотношения кодировок страницы, базы данных, сессии, параметров запроса и ответа не зависят от языка разработки и описанные для Java функции имеют аналоги для PHP, Asp и других.
Примечание: восстановить ссылки на источники нет возможности, все примеры взяты из собственного кода, хотя когда-то так же выискивал их по многочисленным форумам.
Надеюсь, этот небольшой обзор поможет начинающим веб-программистам сократить время отладки и сберечь нервы.
Правим реестр для исправления непонятных букв
Для начала нам нужно создать обычный файл в текстовом редакторе. Сохранить его нужно будет с расширением .reg. Таким образом, мы сможем прописать нужные параметры в файле и применить изменения непосредственно к реестру. Вот что нам следует прописать в нашем файлике:
Windows Registry Editor Version 5.00
«Comic Sans MS,0″=»Comic Sans MS,204»
«MS Sans Serif,0″=»MS Sans Serif,204»
«Times New Roman,0″=»Times New Roman,204»
Просто скопируйте это в свой текстовый документ и сохраните его. Теперь нужно запустить созданный и сохранённый файл, кликнув по нему дважды ЛКМ. Соглашаемся с системным уведомлением о внесении изменений в ОС. Далее перезагружаем ПК. Как правило, перед любыми изменениями в реестре нужно создавать резервную копию реестра, чтобы в любой момент можно было откатить его к первоначальной конфигурации.
Используем системные настройки для решения проблемы
Прежде всего, попробуем исправить ошибку через панель управления. Чтобы зайти в неё нажимаем ПКМ по кнопке-меню «Пуск» и в выпавшем списке выбираем соответствующий пункт.
В открывшемся новом окне находим раздел «Часы, язык, регион».
В новом разделе выбираем категорию региональных стандартов.
Здесь мы сможем настроить вариант даты и времени, а также числовой разделитель, количество дробных значений, формат отрицательных чисел, систему единиц измерения и пр.
Также здесь нам предлагается изменить формат денежных единиц и обозначение таковых. Здесь же мы можем настроить локальные параметры для разных регионов, включая отображаемые в системе текстовые символы. Именно эти опции нас и интересуют. Для их выбора переходим ко вкладке «Дополнительно» в верхней части окна.
Переходим в раздел выбора языка, не поддерживающего Юникод, и далее выбираем опцию изменение языка системы.
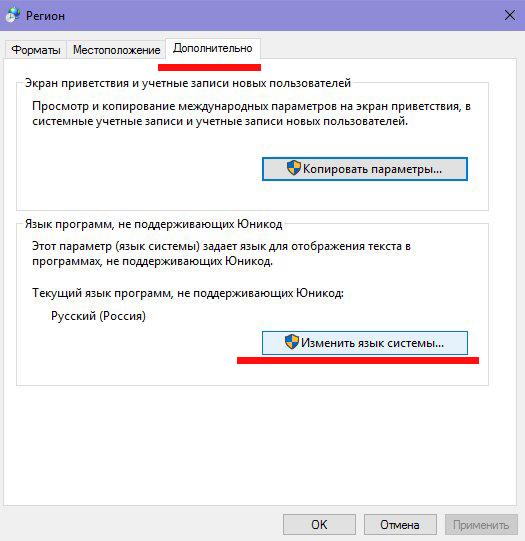
В списке выбираем нужный вариант (в нашем случае «Русский (Россия)» и нажимаем «ОК»)
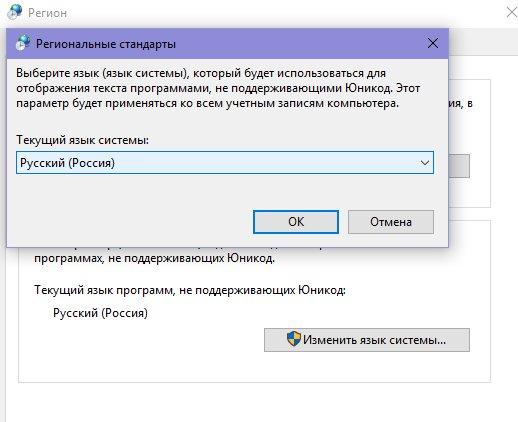
В появившемся окне уведомлений выбираем «Перезагрузить сейчас».
ПК уйдёт в перезагрузку, после чего проблема с кракозябрами должна исчезнуть. Однако не всегда этот способ срабатывает. Если он не помог решить проблему, рассмотрим ещё один вариант, в котором нам придётся поработать с реестром.
Суть проблемы
Как правило, мы можем наблюдать непонятные символы не в каждой программе. Например, символы, изображённые кириллицей в названии программ, отображены корректно. Но если запустить программу установки дистрибутивов, поддерживающих русский язык, мы получаем неведомую нам «китайскую грамоту».
И, пожалуй, основная проблема кроется в том, что в имеющейся ОС по дефолту отсутствует поддержка кириллических символов. На практике это может значить, что вы инсталлировали английский дистрибутив с установленным поверх него расширенным пакетом русификации. Однако последний не смог решить проблему корректно.
Первое, что пытаются делать пользователи в такой ситуации – переустановка операционки с чистого листа. Однако не все согласятся на такое, ведь кто-то, возможно, намеренно хочет работать с англоязычной средой. И в этой среде кириллические символы по идее могут и должны отображаться корректно.
Редактируем страницу кода вручную
Страницы кода отвечают за сопоставление символов с байтами. Таких таблиц бывает много, и каждая из них работает с различными языками. Зачастую кракозябры появляются при неправильном выборе страницы и её сопоставлении. Чтобы исправить это, нам предстоит поработать с реестром. Для этого:
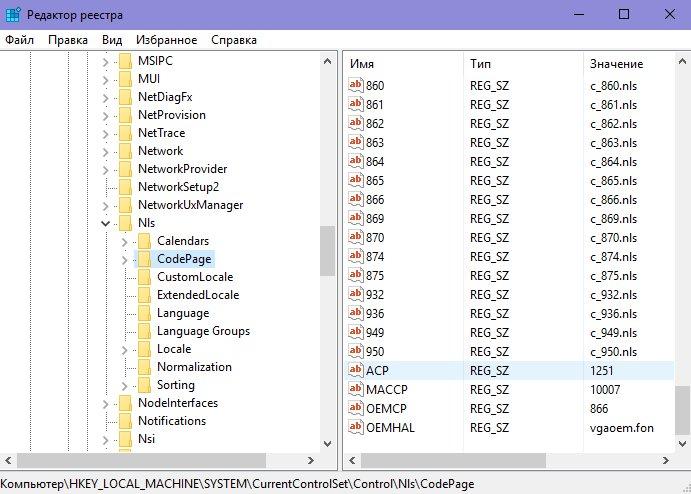
Находясь в том же разделе CodePage, в правой части окна ищем пункт 1252. Жмём по нему дважды ЛКМ и в появившемся окне меняем текущее значение 1252 на 1251.
После произведённых манипуляций отправляем компьютер в перезагрузку, чтобы применённые изменения вступили в силу.
Менее правильные, но пригодные решения
В любом случае, поставьте юникодный шрифт в консоли. ( Это первый абзац «сложного» решения.)
Убедитесь, что ваши исходники в кодировке CP 1251 (это не само собой разумеется, особенно если у вас не русская локаль Windows). Если при добавлении русских букв и сохранении Visual Studio ругается на то, что не может сохранить символы в нужной кодировке, выбирайте CP 1251.
Если компьютер ваш, вы можете поменять кодовую страницу консольных программ на вашей системе. Для этого сделайте вот что:
Преимущества способа: примеры из книг начнут работать «из коробки». Недостатки: смена реестра может повлечь за собой проблемы, кодировка консоли меняется глобально и перманентно — это может повлиять сломать другие программы. Плюс эффект будет только на вашем компьютере (и на других, у которых та же кодировка консоли). Плюс общие проблемы неюникодных способов.
Вы можете поменять кодировку только вашей программы. Для этого нужно сменить кодировку консоли программным путём. Из вежливости к другим программам не забудьте потом вернуть кодировку на место!
Это делается либо при помощи вызова функций
в начале программы, либо про помощи вызова внешней утилиты
(То есть, у вас должно получиться что-то вроде
и дальше обыкновенный код программы.)
Можно обернуть эти вызовы в класс, чтобы воспользоваться плюшками автоматического управления временем жизни объектов C++.
(если выполняете задание из Страуструпа можно вставить в конец заголовочного файла std_lib_facilities.h)
Если вам нужен не русский, а какой нибудь другой язык, просто замените 1251 на идентификатор нужной кодировки (список указан ниже в файле), но, разумеется, работоспособность не гарантируется.
Остались методы, которые тоже часто встречаются, приведём их для полноты.
Правильное, но сложное решение
Lucida Console и Consolas справляются со всем, кроме иероглифов. Если ваши консольные шрифты позволят, вы сможете вывести и 猫, если нет, то лишь те символы, которые поддерживаются.
Дальнейшее рассмотрение касается лишь Microsoft Visual Studio. Если у вас другой компилятор, пользуйтесь предложенными на свой страх и риск, никакой гарантии нету.
Настроив среду, перейдём к решению собственно задачи.
Правильным решением является уйти от однобайтных кодировок, и использовать Unicode в программе. При этом вы получите правильный вывод не только кириллицы, но и поддержку всех языков (изображение отсутствующих в шрифтах символов будет отсутствовать, но вы сможете с ними работать). Для Windows это означает переход с узких строк (char*, std::string) на широкие (wchar_t*, std::wstring), и использование кодировки UTF-16 для строк.
(Ещё одна проблема, которую решает использование широких строк: узкие строки при компиляции кодируются в однобайтную кодировку используя текущую системную кодовую страницу, то есть, ANSI-кодировку. Если вы компилируете вашу программу на английской Windows, это приведёт к очевидным проблемам.)
Такой способ должен работать правильно с вводом и выводом, с именами файлов и перенаправлением потоков.
Важное замечание: потоки ввода-вывода находятся либо в «широком», либо в «узком» состоянии — то есть, в них выводится либо только char*, либо только wchar_t*. После первого вывода переключение не всегда возможно. Поэтому такой код:
cout << 5; // или printf(“%d”, 5);
wcout << L”привет”; // или wprintf(L”%s”, L”привет”);
вполне может не сработать. Используйте только wprintf/wcout.
Если очень не хочется переходить на Unicode, и использовать однобайтную кодировку, будут возникать проблемы. Для начала, символы, не входящие в выбранную кодировку (например, для случая CP1251 — базовый английский и кириллица), работать не будут, вместо них будет вводиться и выводиться абракадабра. Кроме того, узкие строковые константы имеют ANSI-кодировку, а это значит, что кириллические строковые литералы на нерусской системе не сработают (в них будет зависимая от системной локали абракадабра). Держа в голове эти проблемы, переходим к изложению следующей серии решений.



