

Stop Using The Faulty HDD
If you receive a system message about an error diagnosed, it doesn’t mean the disk is out of order already. However, in case of a S.M.A.R.T. error, you should realize the disk is on the way to its breakdown. It can fail completely anytime – both within several minutes or in a month or even in a year. Anyway, it does mean you cannot trust to keep your data there.
You should take some care about the safety of your data, make a backup copy or transfer files to another media. Along with these actions meant to save your data, you should also replace your hard disk. The disk where S.M.A.R.T. errors were found cannot be used – even if it doesn’t break down completely, it can still damage your data partially.
Of course, a hard disk can fail even without showing any S.M.A.R.T. messages, but this technology gives you a certain advantage of warning you about the coming breakdown problem.
Restore The Deleted Data From The Disk
If there is a SMART error, restoring data from the disk is not always necessary. In case of an error, it is recommended to create a backup copy of important information immediately, because now the disk can fail completely at any time. However, there are errors that make data copying impossible. In this case, you can use special hard disk data recovery software – Hetman Partition Recovery.
The tool recovers data from any devices, regardless of the cause of data loss.
To do it:
- Download the program, install and launch it.
- By default, you will be suggested to use File Recovery Wizard. After clicking Next the program will suggest you to choose a disk to recover files from.
- Double-click on the faulty disk and choose the type of analysis. Select Full analysis and wait for the scanning process to finish.
- After the scanning process is over you will be shown files for recovery. Select the necessary files and click Recover.
- Select one of the suggested ways to save files. Do not save the recovered files to the disk having an error «0xC4 Reallocation Event Count».
Scan The Disk For Bad Sectors
Start scanning all partitions of the disk and try correcting any mistakes that are found.
To do it, open This PC and right-click on the disk with a SMART error. Select Properties / Tools / Check in the tab Error checking.
Errors found on the disk as a result of scanning can be corrected.
Go to view

Reduce The Disk Temperature
Sometimes a SMART error can be caused by exceeding the maximum temperature of the disk. This problem can be eliminated by improving the case ventilation. First of all, make sure that your computer has sufficient ventilation and that all coolers are in proper working order.
If you found and eliminated the ventilation problem, which helped to bring the disk temperature back to normal, this SMART error can never appear again.
How to Check the Processor (CPU), Video Card (GPU) or Hard Disk (HDD) Temperature
Run Hard Disk Defragmentation
Open This PC and right-click on the disk having an error «0xC4 Reallocation Event Count». Select Properties / Tools / Optimize in the tab Optimize and defragment drive.
Select the disk you need to optimize and click Optimize.
Note. In Windows 10 disk defragmentation and optimization can be adjusted to take place automatically.
«Reallocation Event Count» In an SSD
Even if you have no problems with an SSD performance, its operability is reducing slowly because SSD memory cells have a limited number of overwrite cycles. The wear resistance function minimizes this effect but never takes it away completely.
SSD disks have their specific SMART attributes which send signals about the state of disk memory cells. For example, “209 Remaining Drive Life,” “231 SSD life left” etc. Such errors may occur when memory cell operability is reduced, and it means the information kept there can be damaged or lost.
In case of failure, SSD cells cannot be recovered or replaced.
SSD Diagnostics: Programs to Find and Fix SSD Errors
How Can You Reset «0xC4 Reallocation Event Count»?
Note: The place where you disable the function is given approximately, because its specific location depends on the version of BIOS or UEFI and can differ slightly.
Buy a New Hard Disk
It is important to realize that any of the ways to eliminate a SMART error is self-deception. It is impossible to completely remove the cause of the error, as it often involves physical wear of the hard disk mechanism.
To replace the hard disk components which operate incorrectly you can go to a service center or a special laboratory dealing with hard disks.
However, the cost of work will be higher than the price of a new device, so it is justified only when you need to restore data from a disk which is no longer operable.
How to choose a new HDD?
If you encounter a hard disk SMART error, then buying a new HDD is only a matter of time. The disk type you need depends on how you work on the computer and the purposes you use your computer for.
Here are some points to consider when buying a new hard disk:
- Size. There are two main form factors for hard disks, 3.5 inch and 2.5 inch. The size of disks is determined in accordance to the slot in a particular computer or laptop.
- IDE, ATAPI, ATA;External Disk (USB, FireWire etc).
- IDE, ATAPI, ATA;
- External Disk (USB, FireWire etc).
- Technical characteristics and performance:Read and write speed;Memory cache size;
- Read and write speed;
- Memory cache size;
- S.M.A.R.T. Availability of this technology in the disk will help determining possible mistakes in its work and prevent loss of data before it is too late.
- Package. This item can include interface or power cables as well as warranty and service options.
Article Suitable for
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (wstrząsoodporny)
- 25H (wstrząsoodporny)
- 25C (proste)
- 25A (wzorzec)
- 35T (pulpitowe)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- V3700 2.5
- Server
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
A-Data HDD
- DashDrive
- Durable)
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (przenośny)
- Save (pulpitowe)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- ProII
- Portable
- Panther
Crucial SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
WD HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
- Go (портативные)
- Save (настольные)
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX

Приветствую. Reallocation Event Count — содержит количество переназначенных секторов. В некотором смысле говорит о состоянии диска, чем выше — тем хуже. Записываются успешные и неуспешные попытки.
Частая причина переназначенных секторов — удар диска, падение, длительная вибрация.
Некоторые мои мысли на эту тему:
- Жесткий диск — пространство где хранятся файлы. Данное пространство состоит из ячеек, точнее — блоков с данными. Таких блоков — тьма. Каждый блок хранит часть информации, часть файла. Когда блок становится нечитаемым — данные из него уже не прочесть, соответственно может быть ошибка, но вроде Windows умеет восстанавливать.
- Такие сектора, которые уже умерли — помечаются как плохими, и заменяются новыми секторами из резервной области, которая кстати не резиновая. Количество таких событий и отражает параметр Reallocation Event Count.
- Когда в резервной области запасные сектора закончатся — замен не будет, и вы можете потерять свои файлы, некоторые программы могут перестать работать, будут появляться некоторые ошибки чтения.
Описание других параметров
Надеюсь информация помогла. Удачи.
Этот сайт использует Akismet для борьбы со спамом. Узнайте как обрабатываются ваши данные комментариев.
Статьи по настройке и администрированию Windows/Linux систем
- Карта сайта
- Мой сайт-визитка

Маленький рассказ об S.M.A.R.T. атрибутах, их важности и понимании. В статье пойдет речь об расшифровке всех smart атрибутов ATA дисков. В предыдущих статьях речь шла об мониторинге BBU и жестких SCSI дисков и их атрибутов под Megaraid контроллером. Теперь хочу немного описать атрибуты обычных АТА дисков на примере Seagate Barracuda ES.2 (ST31000340NS). Так же определим самые важные атрибуты, на которые нужно обращать внимание при мониторинге дисков используя smartctl. Для начала, можно убедиться, что наш диск поддерживает смарт
Две последние строки свидетельствуют о том, что диск поддерживает smart и можно посмотреть значение всех его атрибутов и их интерпретация будет корректной(интерпретация RAW_VALUE) . В данном случаи тип интерфейса (устройства) не указывался явно (не было указанно атрибут «-d»), по этому smartctl автоматически определил тип устройства и сказал, что «SMART support is: Enabled». Но если используются, к примеру массивы дисков (RAID контроллер), то smartctl может сказать, что смарт не поддерживается:
Но на самом деле, нужно просто знать (или подбирать) какие дисковые массивы используются, и тогда можно получить желаемый результат явно указав тип устройства:
Также может быть проблема в версии smartctl ибо не все жесткие диски добавляются в базу SMART сразу после выхода в мир нового HDD или RAID контроллера. Или же в BIOS отключено поддержку (нужно включить). Так же может быть проблема в прошивке (firmware) самого жесткого диска. Можете также стоит для начала попытаться включить SMART командой:
Следующая, интересующая нас часть вывода покажет суммарный результат проверки статуса здоровья диска (Если не Passed – нужно проводить замену диска). Так же выводится дополнительные характеристики диска и предполагаемое время выполнения коротких и длинных тестов.
В нашем случаи тип устройства определился автоматически и теперь можно вывести самое интересное — список атрибутов.
Используя SMART можно предугадать с довольно большой вероятностью проблемы связанные с:
- Магнитными головками диска
- Физическими повреждениями диска
- Логическими ошибками
- Механическими проблемами (проблемы привода, системы позиционирования)
- Подачей питания (платы)
- Температурой
Расшифруем полученный вывод.

Каждый атрибут имеет группу значений:
- ID# — идентификационный номер атрибуты (детали здесь). Каждый атрибуты имеет свой уникальный ID, который должен быть одинаковым для всех фирм производителей дисков.
- ATTRIBUTE_NAME – название атрибута. Так как разные фирмы производители дисков могут называть атрибуты по своему (сокращать, синонимы), лучше всего ориентироваться по ID атрибута.
- FLAG (Status flag) – каждый атрибут имеет определенный флаг, назначенный фирмой разработчиком диска. В ОС с графическим интерфейсом значения этого флага предоставляется в виде набора буквенных обозначений – w,p,r,c,o,s (расшифровка ниже). И эти наборы предоставляются в виде шестнадцатеричного числа которые вы видели выше.
- Warranty: Указывает на жизненно важный атрибут диска и покрывается гарантией. Если этот флаг установлен и значение атрибута с этим флагом достигнет порогового (threshold) значения, в то время, когда диск еще на гарантии, то фирма должна будет заменить диск бесплатно.
- Performance: Указывает на атрибут, который представляет показатель производительности диска – не критический.
- Error Rate: Атрибут с частотой ошибок.
- Count of occurrences: Атрибут-счетчик происшествий.
- Online test: Атрибут, который обновляет значения только через on-line тесты. Если не указан, то обновляется через off-line тесты.
- Self preserving: Указывает на атрибут который может собирать и сохранять данные о диска, даже если S.M.A.R.T. отключен.
- Value – Текущее значение атрибута(оценка атрибута диска на основе Raw_value). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Это значение атрибута нужно сравнивать с пороговым (threshold) значением. Если это критический атрибут и значение ниже порогового — нужно проводить замену диска.
- Worst – Самое низкое значение атрибута за жизненный цикл диска. Значение может изменяться на протяжении жизни диска, и не должно быть ниже или равным пороговому значению (threshold).
- Thresh (Threshold) – Пороговое значения атрибута назначенное создателем диска. Значение не меняется за жизненный цикл диска. Если значение Value атрибута станет равным или меньше порогового – появиться уведомление в колонке WHEN_FAILED. И диск нужно заменить.
- Type – тип атрибута. Может быть критическим (pre-fail), который указывает на предстоящий отказ диска из-за ошибок или не критический, указывающий на достижение конца жизненного цикла диска.
- Raw_value – Объективное значения атрибута, которое показывается в десятичном формате (вычисляется firmware диска) и известных только производителю единицах (имеет связь с Value, Threshold и Worst значениями).
- WHEN_FAILED – Указывает на проблемы с атрибутом.
Атрибут диска примет значение failed, в случаи:
Жесткий диск является одним из важнейших компонентов любого ПК. Он хранит в себе всю информацию, которой вы пользуетесь на вашем ПК. Именно поэтому нужно следить за состоянием этого компонента, как и впрочем любого другого, но в случае возникновения проблем с вашим жестким диском, вы можете потерять всю информацию на нём.
Всегда делайте копии важных фалов и документов, ведь каким бы надежным и дорогим не был ваш накопитель, от сбоев в его работе никто не застрахован.
Общее состояние вашего жесткого диска
Итак, как же узнать, в каком состоянии находится ваш жесткий диск? Вскрывать его и смотреть его внутреннее состояние нельзя. да и незачем. Для оценки его текущего состояния придумали специальную технологию — “S.M.A.R.T.”. Эта технология встроена в каждый жесткий диск любого производителя и формата, и позволяет судить о его состоянии, оценивая множество параметров его работы. Просмотреть эту информацию можно разными способами: запустить специальную программу в Windows или использовать специальный загрузчик, который работает напрямую с диска или флешки, и позволяет отобразить эту информацию с жесткого диска. Вторым методом можно воспользоваться, если не работает операционная система, и есть подозрения в неисправности жесткого диска. Мы же воспользуемся первым способом, как наиболее простым и легким.

Одним из преимуществ данной программы является перевод всех показателей жесткого диска.
Выбираем в верхней панели один из жестких дисков:

Первое, на что нужно обратить внимание, так это общий статус диска (левый верхний угол, под надписью “Техсостояние”). Если там написано “Хорошо” или “Отлично”, то с вашим диском все в порядке.
В случае, если написано “Тревога”, то нужно задуматься о смене диска, и скопировать всю важную информацию на другой диск. Ниже представлен пример скриншота программы для диска на WD 500GB 2008 г. производства. Т.е. на момент написания статьи ему уже 9 лет. Такой диск точно требует замены.

Н еобходимо обращать внимание на температуру диска, она должна быть не выше 45-50 градусов. Если температура превышает данные значения, нужно задуматься об охлаждении вашего диска.
Косвенно о состоянии вашего жесткого диска можно судить по времени его работы. На сайте изготовителе вашего жесткого диска можно найти время наработки на отказ, однако даже если этот порог будет превышен, то это не значит, что жесткий диск не пригоден для использования. Это лишь сигнал к тому, что нужно иногда проверять его состояние.
Дополнительная полезная информация
Перед тем, как ознакомиться с данным пунктом, настоятельно рекомендуется узнать о базовых принципах работы жесткого диска из Википедии или других источников.
Пункт техсостояние показывает общую усредненную оценку состояния жесткого диска; если мы хотим узнать более подробные сведения о работе диска, то нужно разобраться в основных показателях работы нашего диска. Для этого разберем все строки из таблицы программы. У каждого диска есть предельное значение и фактическое значение. Чтобы было более наглядно, выполните действия как на картинке ниже, установив другое отображение для RAW данных.

Теперь рассмотрим основные колонки данной таблицы.

- Левые голубые и желтые кружочки обозначают оценку программы жесткого диска,
- Атрибут — в ней указывается название параметра,
- Текущее — состояние параметра на данный момент
- Наихудшее — наихудшее значение параметра Текущее за все время.
- Порог — пороговое значение параметра, установленное заводом изготовителем данного диска.
- Raw-значения — самый главный показатель, который нужно сравнивать с полем “Порог”
Н иже вы увидите список, где указан каждый параметр и как он считается; жирным шрифтом в нём отмечены самые важные параметры, которые показывают состояние жесткого диска. Чтобы оценить состояние, нужно каждый параметр из графы “Raw-значения” сравнивать с числом в графе “Порог”. Если число из колонки “Raw-значения” больше числа в графе “Порог”, то смотрите описание в списке ниже, чтобы оценить состояние диска.
Основные параметры S.

На диске странные значения по Raw-данным, но их появление связано с возрастом диска. На момент написания статьи ему 14 лет.
Диск 2. WesternDigital 500 Гб. 2008 г. выпуска

На диске много переназначенных и нестабильных, значительно превышающих порог — это значит, что размер диска уже уменьшился и идет его деградация.
Диск 3. WesternDigital 250 Гб. 2007 г. выпуска

Диск в полном порядке, однако присутствует странное время раскрутки шпинделя. Диск полностью исправен.
Диск 4. WesternDigital 640 Гб. 2008 г. выпуска

Огромное количество ошибок чтения-записи и нестабильные сектора. Диск на замену.
I’ve just looked at the health status of my old 2,5 inch 500 Gb Fujitsu drive with a popular “HD Tune” utility. It shows a warning for the “Reallocated Event Count” property.

How serious is that?
The thing is that the drive is practically new. I pulled it out of a new laptop over a year ago and never used it since. Right now it only has 53 “Power On” hours which sounds about right since I only had it running a few evenings overnight before switching it for something more performant.
Does this warning indicate that the drive is likely to fail some time in the future? I’m somewhat perplexed since the drive is effectively unused.
What is more, I have arranged with somebody to buy off this drive since I don’t really need. It is 12,5 mm thick (with 3 plates) meaning it doesn’t fit into an external enclosure which makes it quite useless to me.
Can I give away the drive without having it on my conscience or better cancel the deal? In other words, can the drive be used safely for years to come or better throw it away?
UPDATE: The sector scan shows no bad sectors.

asked Apr 14, 2010 at 8:30
Google wrote an excellent white paper about hard drive failures:
The gist of it is, once a hard drive starts handling media failures (such as remapping sectors), it is headed downhill and will fail soon. This is true whether the drive is brand new or 3 years old.
If you are truly concerned about data integrity and uptime, RMA the hard drive.
P.S. It is unlikely a modern SMART drive will show bad sectors, at least not until its ability to remap bad sectors has been exhausted.
answered Apr 14, 2010 at 12:38
15 silver badges22 bronze badges
Modern drives reserve a bunch of sectors for relocating other to if they seem to be in dubious condition (hopefully before they go bad). It is not unusual for a drive to have to do this occasionally in its life, but doing it too much indicates a serious or growing problem so I would recommend the drive not be used. It may give further years of trouble free service, or it may start suffering unrecoverable read or write errors tomorrow.
SMART parameters are not always identically supported across all drives, so it might be worth seeing if the drive manufacturer has their own utility to double-check that the drive and HD Tune are on the same wavelength.
answered Apr 14, 2010 at 8:52

REC is ‘the number of attempts to transfer data from reallocated sectors to a spare area’ – i.e. how often SMART wants to move data because of suspect sectors – I think you have a partially dead disk.
answered Apr 14, 2010 at 8:53
9 gold badges107 silver badges239 bronze badges
Bad sectors on the HDD.
Buy a new drive now.
Reallocated Event Count in SMART test is quite important as an indicator of what is happening with the drive. It basically shows the counts of remap operations (transferring data from a bad sector to a special reserved disk area – spare area).
Basically when a bad sector is found on your hard drive it is swapped with a ‘reserve pool’ of sectors and after this swap, the HDD should be free of bad sectors to the OS. This technology designed to make failing sectors on the HDD cause no trouble for the operating system because it’ll just swap a new one whenever it finds that a particular sector is becoming weak (because it takes more time to read that sector than normal). However, the number of sectors available for replacement is limited and once it’s reached no more sectors can be “fixed”. A small number of reallocated sectors in not a serious, but the situation should be monitored and if they start increase you should replace the HDD.
Also, if you don’t have any backups of your data I’d strongly suggest to consider one. For instance, I use the so called 3-2-1 backup strategy, which stands for 3 copies, 2 different storage mediums and 1 offsite, but you can develop one on your own as long as the information is kept on several devices and not on one place only.
Hope this helps and feel free to ask any questions you may have.
See less
See more
Since you’re the Western Digital rep, I’ll take this opportunity to ask you a question which has been bothering me for a while concerning remapped sectors: how many spare sectors are on a drive? How is it determined? Percentage of capacity? Percentage of the number of sectors (with 4K drives naturally having a lower number of sectors for a given capacity)? The target market, with the rationale being that a better quality drive is less likely to fail, i.e. a 15K SAS drive would have less spare sectors than a 7200RPM consumer drive?
Some other determinant?
Back data off and buy a new one. Drive is failing. Or you can RMA it.
Originally Posted by parityboy
Originally Posted by MightyMiroWD
thanks MightyMiro for the detailed response..I was not expecting a WD rep to be here
Just gotta say this HD has been a beast, will probably get another WD as well as an SSD (surprised you guys aren’t in that market yet?)
As a comparison I decided to run HDTune on my old Asus Z71 laptop.
I know this isn’t a fair comparison because this is a laptop hard drive and a different vendor but its been used almost every day since 2005 and is still running fine. Notice the reallocated event count warning still shows up.
Now in both cases I don’t know when the warning first occurs since I havent been using HDTune until now, so I may have had this warning for a few days or a few years now.
Does Western Digital have their own test software that may be more accurate than HDTune?
Thank you for the support, mate – we highly appreciate it!
There is no way to say how fast the Reallocated sectors will appear since it depends on a lot of factors, such as how intensive the usage of the hard disk was.
As for a specific diagnostic tool, you can download and use Data Lifeguard Diagnostics from our website and run an additional test as well (you can try both the Quick and the Extended if you want), but do have in mind that it won’t display the RAW values of the HDD. Here’s a link you can use:
http://products.wdc.com/support/kb.ashx?id=0jNTXu
Once the test is complete upload some screenshots so I can take a look.
I ran the extended test last night and got this result.
Test Option: EXTENDED TEST
Model Number: WDC WD10EACS-00D6B0
Firmware Number: 01.01A01
Capacity: 1000.20 GB
SMART Status: PASS
Test Result: PASS
Test Time: 12:09:32, October 16, 2016
Also ran a quick test and it passed as well. I guess the drive is fine then ?
Something doesn’t add up. You have a Reallocated Event count of 2, yet the number of Reallocated Sectors is 0? How?
Since the tool did not detected anything wrong it will be OK to use it.
Also, for security reasons I’d suggest to black out the S/N of the drive, just in case.
Not sure to be honest, but if thats the case then both my z71 and the WD have the same problem.
Good to know, I’m hoping this drive never dies its on a good streak
I silently fixed the S/N issue.. shh don’t tell anyone
FoolzRailer
Not sure if this is in the right place or not, but here goes.
I have a harddrive thats been giving me a couple of BSOD (every week too every other week). I’m running Windows 8 on an Asus laptop. Just did a HD Tune scan and getting warning on Reallocated Event Count and Current Pending Sector.
Is the Harddrive going to crash anytime soon or is this within the “normal” range.
Thanks in advance
anyway i guess your drive might be starting to fail, do you happen to move the laptop around while in use or it usually stays flat on a table? i find it unusual that the other values arent showing warning signs, how about running a full error scan on it?
Thanks for the quick reply.
Also, sometimes the harddrive runs at 100% when copying files and have had to do a forced shut down on several occasions.
Frick
Also look at Load Cycle Count: It’s already at 130 000, it’s rated for 600 000. It’ll wear out fast. It probably has the same problem WD Greens has.
Anyway I would replace it as soon as possible, when it starts to have bad sectors it can fail pretty quick (it can also work for years, but the risk of failure increases). I don’t know if you have to RMA the entire computer or just the drive.
I have to RMA the entire laptop, so that sucks. Already created an RMA for it with the HD Tune report included. So heres top hoping I get a new drive at some point
400 pending sectors? I’d qualify that as a problem
Back up your data and get that replaced asap!
«Тестировать нельзя диагностировать» – куда бы вы поставили запятую в данном предложении? Надеемся, что после прочтения данного материала вы без проблем можете чётко дать ответ на этот вопрос. Многие пользователи когда-либо сталкивались с потерей данных по той или иной причине, будь то программная или аппаратная проблема самого накопителя или же нестандартное физическое воздействие на него, если вы понимаете, о чём мы. Но именно о физических повреждениях сегодня речь и не пойдёт. Поговорим мы как раз о том, что от наших рук не зависит. Стоит ли тестировать SSD каждый день/неделю/месяц или это пустая трата его ресурса? А чем их вообще тестировать? Получая определённые результаты, вы правильно их понимаете? И как можно просто и быстро убедиться, что диск в порядке или ваши данные под угрозой?

Тестирование или диагностика? Программ много, но суть одна
Так уж получилось, что именно подсистема хранения данных в настольных системах является одним из самых уязвимых мест, так как срок службы накопителей чаще всего меньше, чем у остальных компонентов ПК, моноблока или ноутбука. Если ранее это было связано с механической составляющей (в жёстких дисках вращаются пластины, двигаются головки) и некоторые проблемы можно было определить, не запуская каких-либо программ, то сейчас всё стало немного сложнее – никакого хруста внутри SSD нет и быть не может. Что же делать владельцам твердотельных накопителей?
Программ для тестирования SSD развелось великое множество. Какие-то стали популярными и постоянно обновляются, часть из них давно забыта, а некоторые настолько хороши, что разработчики не обновляют их годами – смысла просто нет. В особо тяжёлых случаях можно прогонять полное тестирование по международной методике Solid State Storage (SSS) Performance Test Specification (PTS), но в крайности мы бросаться не будем. Сразу же ещё отметим, что некоторые производители заявляют одни скорости работы, а по факту скорости могут быть заметно ниже: если накопитель новый и исправный, то перед нами решение с SLC-кешированием, где максимальная скорость работы доступна только первые несколько гигабайт (или десятков гигабайт, если объём диска более 900 ГБ), а затем скорость падает. Это совершенно нормальная ситуация. Как понять объём кеша и убедиться, что проблема на самом деле не проблема? Взять файл, к примеру, объёмом 50 ГБ и скопировать его на подопытный накопитель с заведомо более быстрого носителя. Скорость будет высокая, потом снизится и останется равномерной до самого конца в рамках 50-150 МБ/с, в зависимости от модели SSD. Если же тестовый файл копируется неравномерно (к примеру, возникают паузы с падением скорости до 0 МБ/с), тогда стоит задуматься о дополнительном тестировании и изучении состояния SSD при помощи фирменного программного обеспечения от производителя.
Яркий пример корректной работы SSD с технологией SLC-кеширования представлен на скриншоте:
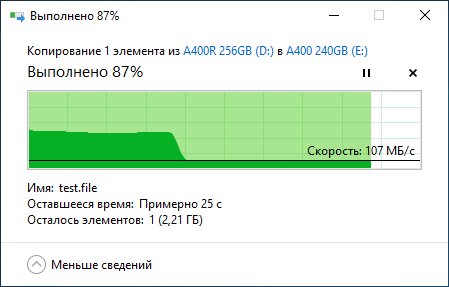
Те пользователи, которые используют Windows 10, могут узнать о возникших проблемах без лишних действий – как только операционная система видит негативные изменения в S.M.A.R.T., она предупреждает об этом с рекомендацией сделать резервные копии данных. Но вернёмся немного назад, а именно к так называемым бенчмаркам. AS SSD Benchmark, CrystalDiskMark, Anvils Storage Utilities, ATTO Disk Benchmark, TxBench и, в конце концов, Iometer – знакомые названия, не правда ли? Нельзя отрицать, что каждый из вас с какой-либо периодичностью запускает эти самые бенчмарки, чтобы проверить скорость работы установленного SSD. Если накопитель жив и здоров, то мы видим, так сказать, красивые результаты, которые радуют глаз и обеспечивают спокойствие души за денежные средства в кошельке. А что за цифры мы видим? Чаще всего замеряют четыре показателя – последовательные чтение и запись, операции 4K (КБ) блоками, многопоточные операции 4K блоками и время отклика накопителя. Важны все вышеперечисленные показатели. Да, каждый из них может быть совершенно разным для разных накопителей. К примеру, для накопителей №1 и №2 заявлены одинаковые скорости последовательного чтения и записи, но скорости работы с блоками 4K у них могут отличаться на порядок – всё зависит от памяти, контроллера и прошивки. Поэтому сравнивать результаты разных моделей попросту нельзя. Для корректного сравнения допускается использовать только полностью идентичные накопители. Ещё есть такой показатель, как IOPS, но он зависит от иных вышеперечисленных показателей, поэтому отдельно говорить об этом не стоит. Иногда в бенчмарках встречаются показатели случайных чтения/записи, но считать их основными, на наш взгляд, смысла нет.
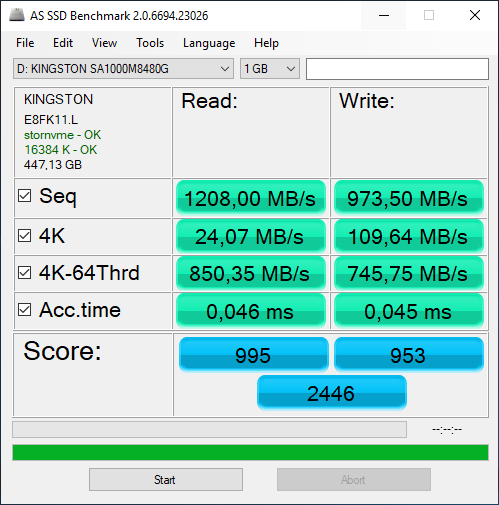
И, как легко догадаться, результаты каждая программа может демонстрировать разные данные – всё зависит от тех параметров тестирования, которые устанавливает разработчик. В некоторых случаях их можно менять, получая разные результаты. Но если тестировать «в лоб», то цифры могут сильно отличаться. Вот ещё один пример теста, где при настройках «по умолчанию» мы видим заметно отличимые результаты последовательных чтения и записи. Но внимание также стоит обратить на скорости работы с 4K блоками – вот тут уже все программы показывают примерно одинаковый результат. Собственно, именно этот тест и является одним из ключевых.

Но, как мы заметили, только одним из ключевых. Да и ещё кое-что надо держать в уме – состояние накопителя. Если вы принесли диск из магазина и протестировали его в одном из перечисленных выше бенчмарков, практически всегда вы получите заявленные характеристики. Но если повторить тестирование через некоторое время, когда диск будет частично или почти полностью заполнен или же был заполнен, но вы самым обычным способом удалили некоторое количество данных, то результаты могут разительно отличаться. Это связано как раз с принципом работы твердотельных накопителей с данными, когда они не удаляются сразу, а только помечаются на удаление. В таком случае перед записью новых данных (тех же тестовых файлов из бенчмарков), сначала производится удаление старых данных. Более подробно мы рассказывали об этом в предыдущем материале.
На самом деле в зависимости от сценариев работы, параметры нужно подбирать самим. Одно дело – домашние или офисные системы, где используется Windows/Linux/MacOS, а совсем другое – серверные, предназначенные для выполнения определённых задач. К примеру, в серверах, работающих с базами данных, могут быть установлены NVMe-накопители, прекрасно переваривающие глубину очереди хоть 256 и для которых таковая 32 или 64 – детский лепет. Конечно, применение классических бенчмарков, перечисленных выше, в данном случае – пустая трата времени. В крупных компаниях используют самописные сценарии тестирования, например, на основе утилиты fio. Те, кому не требуется воспроизведение определённых задач, могут воспользоваться международной методикой SNIA, в которой описаны все проводимые тесты и предложены псевдоскрипты. Да, над ними потребуется немного поработать, но можно получить полностью автоматизированное тестирование, по результатам которого можно понять поведение накопителя – выявить его сильные и слабые места, посмотреть, как он ведёт себя при длительных нагрузках и получить представление о производительности при работе с разными блоками данных.
В любом случае надо сказать, что у каждого производителя тестовый софт свой. Чаще всего название, версия и параметры выбранного им бенчмарка дописываются в спецификации мелким шрифтом где-нибудь внизу. Конечно, результаты примерно сопоставимы, но различия в результатах, безусловно, могут быть. Из этого следует, как бы грустно это ни звучало, что пользователю надо быть внимательным при тестировании: если результат не совпадает с заявленным, то, возможно, просто установлены другие параметры тестирования, от которых зависит очень многое.
Похожее:
 «Мне требуется помощь в решении проблемы с моим ноутбуком ASUS, который отображает сообщение о критическом состоянии резервной копии смарт-статуса, сопровождаемое предложением заменить его. Кроме того, он предлагает мне нажать F1 для возобновления работы. Пожалуйста, посоветуйте потенциальное решение для преодоления этой проблемы»
«Мне требуется помощь в решении проблемы с моим ноутбуком ASUS, который отображает сообщение о критическом состоянии резервной копии смарт-статуса, сопровождаемое предложением заменить его. Кроме того, он предлагает мне нажать F1 для возобновления работы. Пожалуйста, посоветуйте потенциальное решение для преодоления этой проблемы»  Сдать общий анализ крови в Москве. Клинический анализ крови. Общий анализ крови цена. Личный кабинет CMD-ONLINE.RU
Сдать общий анализ крови в Москве. Клинический анализ крови. Общий анализ крови цена. Личный кабинет CMD-ONLINE.RU -120x120.jpg "ВПЧ, вирус папилломы человека - причины появления, симптомы заболевания, диагностика и способы лечения") ВПЧ, вирус папилломы человека – причины появления, симптомы заболевания, диагностика и способы лечения
ВПЧ, вирус папилломы человека – причины появления, симптомы заболевания, диагностика и способы лечения