

Change codepage in cmd permanently?
Command prompt code page always change back to the default 437 if you just use chcp 850 in cmd to change the active language code (850 = Multilingual (Latin I)).
My system default language is set to English (437) although I’m Brazilian (language code 850).
Once I need to show some special characters such as ã, õ, ç, I found that at Windows 10, under All Settings > Time & Language > Region & Language there is (at the top right corner) a link for Related settings – Additional date, time & regional settings. From there you’ll be redirected to Control PanelClock, Language, and Region. Click again on Region > Change Location and at the window Region, at the tab Administrative, change the Language for non-Unicode programs by clicking the button Change system locale and choosing some other that uses the code you need (In my case, Portuguese (Brazil) = code 850). Restart Windows and check if your command prompt is now set to the new language code (type chcp in cmd). For me, it solved the problem.
There is also a Latin (Word) option on the list that I suppose is also code 850.
Cmd: изменение кодировок консоли |
Многие скажут — в PowerShell нет таких проблем как в CMD, юникод поддерживается из коробки!
И будут правы:)
Но мне быстрее и проще что-то простое сделать с помощью batch файла.
Мы используем русский язык в Windows.
Windows же использует несколько кодировок для русского языка:
CP1251 — Windows кодировка
CP866 — используется в консольных приложениях
UTF-8 — Юникод
В консоли CMD по умолчанию используется кодировка CP866.
Поэтому для вывода русского текста в cmd, batch файлах необходимо русский текст перекодировать в CP866 кодировку.
Узнать какая кодировка установлена в консоли позволяет команда chcp:
chcp Текущая кодовая страница: 866
Попробуем вывести текст в кодировке CP1251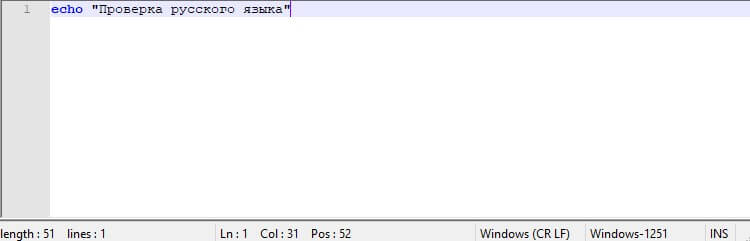
>test.bat C:Usersvino7>echo "╧ЁютхЁър Ёєёёъюую ч√ър" "╧ЁютхЁър Ёєёёъюую ч√ър"
Изменим кодировку терминала командой:
@echo off chcp 1251 echo "Проверка русского языка"
Выполним скрипт:
test.bat Текущая кодовая страница: 1251 "Проверка русского языка"
Теперь русский выводится правильно.
Варианты установок:
- chcp 1251 — Установить кодировку в CP1251
- chcp 866 — Установить кодировку в CP866
- chcp 65001 — UTF-8
Converting text file to utf-8 on windows command prompt
POWERSHELL: # Assumes Windows PowerShell, use -Encoding utf8BOM with PowerShell Core. For multiple files:
FIRST SOLUTION:
$files = Get-ChildItem c:Folder1 -Filter *.txt
foreach ($file in $files) { Get-Content $file.FullName | Set-Content "E:TempDestination$($file.Name)" -Encoding utf8BOM
}OR, SECOND SOLUTION (for multiple files):
get-item C:Folder1*.* | foreach-object {get-content -Encoding utf8BOM $_ | out-file ("C:Folder1" $_.Name) -encoding default}OR, THE THIRD SOLUTION: (only for 2 files)
$a = "C:/Folder1/TEST_ro.txt" $b = "C:/Folder1/TEST_ro-2.txt" (Get-Content -path $a) | Set-Content -Encoding UTF8BOM -Path $bWhat encoding/code page is cmd.exe using?
Yes, it’s frustrating—sometimes type and other programs
print gibberish, and sometimes they do not.
First of all, Unicode characters will only display if the
current console font contains the characters. So use
a TrueType font like Lucida Console instead of the default Raster Font.
But if the console font doesn’t contain the character you’re trying to display,
you’ll see question marks instead of gibberish. When you get gibberish,
there’s more going on than just font settings.
When programs use standard C-library I/O functions like printf, the
program’s output encoding must match the console’s output encoding, or
you will get gibberish. chcp shows and sets the current codepage. All
output using standard C-library I/O functions is treated as if it is in the
codepage displayed by chcp.
Matching the program’s output encoding with the console’s output encoding
can be accomplished in two different ways:
However, programs that use Win32 APIs can write UTF-16LE strings directly
to the console with
WriteConsoleW.
This is the only way to get correct output without setting codepages. And
even when using that function, if a string is not in the UTF-16LE encoding
to begin with, a Win32 program must pass the correct codepage to
MultiByteToWideChar.
Also, WriteConsoleW will not work if the program’s output is redirected;
more fiddling is needed in that case.
type works some of the time because it checks the start of each file for
a UTF-16LE Byte Order Mark
(BOM), i.e. the bytes 0xFF 0xFE.
If it finds such a
mark, it displays the Unicode characters in the file using WriteConsoleW
regardless of the current codepage. But when typeing any file without a
UTF-16LE BOM, or for using non-ASCII characters with any command
that doesn’t call WriteConsoleW—you will need to set the
console codepage and program output encoding to match each other.
How can we find this out?
Here’s a test file containing Unicode characters:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好Here’s a Java program to print out the test file in a bunch of different
Unicode encodings. It could be in any programming language; it only prints
ASCII characters or encoded bytes to stdout.
import java.io.*;
public class Foo { private static final String BOM = "ufeff"; private static final String TEST_STRING = "ASCII abcde xyzn" "German äöü ÄÖÜ ßn" "Polish ąęźżńłn" "Russian абвгдеж эюяn" "CJK 你好n"; public static void main(String[] args) throws Exception { String[] encodings = new String[] { "UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" }; for (String encoding: encodings) { System.out.println("== " encoding); for (boolean writeBom: new Boolean[] {false, true}) { System.out.println(writeBom ? "= bom" : "= no bom"); String output = (writeBom ? BOM : "") TEST_STRING; byte[] bytes = output.getBytes(encoding); System.out.write(bytes); FileOutputStream out = new FileOutputStream("uc-test-" encoding (writeBom ? "-bom.txt" : "-nobom.txt")); out.write(bytes); out.close(); } } }
}The output in the default codepage? Total garbage!
Z:andrewprojectssx1259084>chcp
Active code page: 850
Z:andrewprojectssx1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y = bom
■A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y == UTF-16BE
= no bom A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
= bom
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y = bom
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y == UTF-32BE
= no bom A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
= bom ■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}However, what if we type the files that got saved? They contain the exact
same bytes that were printed to the console.
Z:andrewprojectssx1259084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
uc-test-UTF-16BE-nobom.txt A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y
uc-test-UTF-32BE-bom.txt ■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
uc-test-UTF-32BE-nobom.txt A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
uc-test-UTF-32LE-bom.txt A S C I I a b c d e x y z G e r m a n ä ö ü Ä Ö Ü ß P o l i s h ą ę ź ż ń ł R u s s i a n а б в г д е ж э ю я C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢The only thing that works is UTF-16LE file, with a BOM, printed to the
console via type.
If we use anything other than type to print the file, we get garbage:
Z:andrewprojectssx1259084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y 1 file(s) copied.From the fact that copy CON does not display Unicode correctly, we can
conclude that the type command has logic to detect a UTF-16LE BOM at the
start of the file, and use special Windows APIs to print it.
We can see this by opening cmd.exe in a debugger when it goes to type
out a file:

After type opens a file, it checks for a BOM of 0xFEFF—i.e., the bytes
0xFF 0xFE in little-endian—and if there is such a BOM, type sets an
internal fOutputUnicode flag. This flag is checked later to decide
whether to call WriteConsoleW.
But that’s the only way to get type to output Unicode, and only for files
that have BOMs and are in UTF-16LE. For all other files, and for programs
that don’t have special code to handle console output, your files will be
interpreted according to the current codepage, and will likely show up as
gibberish.
You can emulate how type outputs Unicode to the console in your own programs like so:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest = "ASCII abcde xyzn" "German äöü ÄÖÜ ßn" "Polish ąęźżńłn" "Russian абвгдеж эюяn" "CJK 你好n";
int main() { int n; wchar_t buf[1024]; HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE); n = MultiByteToWideChar(CP_UTF8, 0, lpcsTest, strlen(lpcsTest), buf, sizeof(buf)); WriteConsole(hConsole, buf, n, &n, NULL); return 0;
}This program works for printing Unicode on the Windows console using the
default codepage.
For the sample Java program, we can get a little bit of correct output by
setting the codepage manually, though the output gets messed up in weird ways:
Z:andrewprojectssx1259084>chcp 65001
Active code page: 65001
Z:andrewprojectssx1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好 你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好 你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…However, a C program that sets a Unicode UTF-8 codepage:
#include <stdio.h>
#include <windows.h>
int main() { int c, n; UINT oldCodePage; char buf[1024]; oldCodePage = GetConsoleOutputCP(); if (!SetConsoleOutputCP(65001)) { printf("errorn"); } freopen("uc-test-UTF-8-nobom.txt", "rb", stdin); n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin); fwrite(buf, sizeof(buf[0]), n, stdout); SetConsoleOutputCP(oldCodePage); return 0;
}does have correct output:
Z:andrewprojectssx1259084>.test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好The moral of the story?
typecan print UTF-16LE files with a BOM regardless of your current codepage- Win32 programs can be programmed to output Unicode to the console, using
WriteConsoleW. - Other programs which set the codepage and adjust their output encoding accordingly can print Unicode on the console regardless of what the codepage was when the program started
- For everything else you will have to mess around with
chcp, and will probably still get weird output.
Исправляем проблему с кодировкой с помощью смены кодировки
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe.
Узнать текущую кодировку можно введя в командной строке команду chcp, после ввода данной команды необходимо нажать Enter.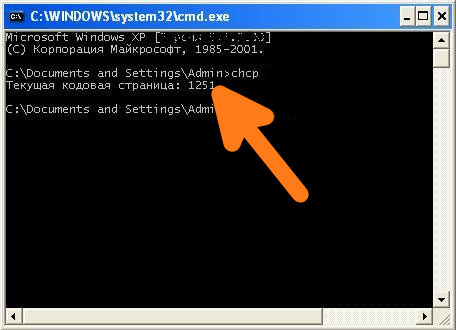
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp <код_новой_кодировки>, где <код_новой_кодировки> – это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 – Windows-кодировка (Кириллица);
- 866 – DOS-кодировка;
- 65001 – Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
chcp 866Для смены кодировки на UTF-8, команда примет следующий вид:
chcp 65001Для смены кодировки на Windows-1251, команда примет следующий вид:
chcp 1251Исправляем проблему с кодировкой с помощью смены шрифта
Первым делом нужно зайти в свойства окна: Правой кнопкой щелкнуть по верхней части окна -> Свойства -> в открывшемся окне в поле Шрифт выбрать Lucida Console и нажать кнопку ОК.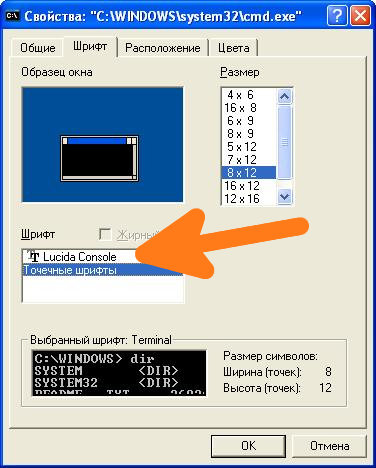
После этого не читаемые символы должны исчезнуть, а текст должен выводиться на русском языке.
Решения проблемы с кодировкой в cmd. 2 способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача: Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD.txt» и вместо справки получится вот что:
Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
После выполнения «Батника» результат будет такой:
Вот так на много лучше, правда?
Пожалуй, на этом я закончу пост. Добавить больше нечего. Если у Вас имеются какие-то соображения по данной теме, буду рад Вашему комментарию к посту.
Дополнительно из комментариев то Garric
Автор очень хорошо описал принцип. ! Но это неудобно.Нужно бы добавить. Если автор добавит это в статью то это будет Good.Создаём файл .reg следующего содержания:——Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT.batShellNew]«FileName»=»BATНастроенная кодировка.bat»——Выполняем.——Топаем в %SystemRoot%SHELLNEWСоздаём там файл «BATНастроенная кодировка.bat»Открываем в Notepad Вводим любой текст. (нужно!) Сохраняемся.Удаляем текст. Меняем кодировку как сказано в статье. Сохраняемся.———-Щёлкаем правой кнопкой мыши по Рабочему столу. Нажимаем «Создать» — «Пакетный файл Windows».Переименовываем. Открываем в Notepad . Пишем батник.В дальнейшем при работе с файлом не нажимаем ничего кроме как просто «Сохранить». Никаких «Сохранить как».



