

LIKE SQL — это оператор, который используется для поиска строк, содержащих определённый шаблон символов. Подробнее о нём читайте в нашей статье.
- Синтаксис LIKE SQL
- Примеры использования LIKE SQL
Использовать оператор LIKE в SQL очень просто: достаточно прописать стандартную команду выбора SELECT * FROM и задать условие через WHERE, где и будет использован оператор LIKE.
Шаблон LIKE SQL:
SELECT column1, column2, ...FROM table_nameWHERE columnN LIKE pattern; Существует два подстановочных знака, которые используются в сочетании с оператором LIKE SQL:
- % — знак процента представляет собой ноль, один или несколько символов;
- _ — подчёркивание представляет собой один символ.
Примеры использования LIKE SQL
Рассмотрим SQL LIKE примеры. Представим, что вы хотите найти все имена, начинающиеся с буквы J. Для этого достаточно использовать следующий запрос:
SELECT * FROM table_name WHERE name LIKE 'J%'; В данном случае символ % используется для указания любого количества символов после J. Таким образом, запрос найдёт все имена, которые начинаются с буквы J, независимо от того, какие символы следуют за ней.
Ещё один пример — поиск всех адресов электронной почты, содержащих слово gmail. Для этого можно использовать следующий запрос:
SELECT * FROM table_name WHERE email LIKE '%gmail%'; Здесь символы % используются для указания, что слово gmail может быть в любом месте в адресе электронной почты.
Также можно использовать символ _ для указания одного символа. Например, запрос ниже найдет все имена, состоящие из шести символов. Эти имена должны начинаться с буквы J и заканчиваться буквой n:
SELECT * FROM table_name WHERE name LIKE 'J____n'; Здесь каждый символ _ указывает на любой один символ.
Иногда символы % и _ сами могут быть частью искомой строки. В таких случаях их нужно экранировать. Например, запрос ниже найдет все имена, содержащие символ %:
SELECT * FROM table_name WHERE name LIKE '%\%%'; Это было короткое руководство по работе с SQL LIKE. Также вы можете почитать о других основных командах SQL.
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Вы читаете улучшенную версию некогда выпущенной нами статьи.
Основы регулярных выражений
Регулярками в Python называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)+Что такое регулярные выражения?
Давайте разберёмся, что же собой представляют регулярные выражения. Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы «d», можно написать
rm d*.Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp . Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. Так, выражению
Хаха, очевидно, будет соответствовать строка «Хаха» и только она. Регулярки являются регистрозависимыми, поэтому строка «хаха» (с маленькой буквы) уже не будет соответствовать выражению выше.Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто
Хаханам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется
\s, для цифр —\d, для символов латиницы, цифр и подчёркивания «_» —\w.Если необходимо описать вообще любой символ, для этого используется точка —
.. Если указанные классы написать с заглавной буквы (\S,\D,\W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.Также с помощью регулярных выражений есть возможность проверить положение строки относительно остального текста. Выражение
\bобозначает границу слова,\B— не границу слова,^— начало текста, а$— конец. Так, по паттерну\bJava\bв строке «Java and JavaScript» найдутся первые 4 символа, а по паттерну\bJava\B— символы c 10-го по 13-й (в составе слова «JavaScript»).

Комикс про регулярные выражения с xkcd.ru
Диапазоны
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
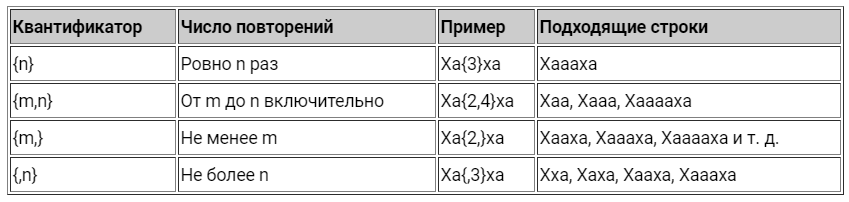
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Очевидное решение
<.*>
здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строкаp><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</pРевнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части RegExp. Это называется ревнивой
квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа+
. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттернуab*+a
в строке «ababa» будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ «a», который стоит на третьей позиции, уже был использован для первого результата.Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java
.Скобочные группы
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение
<(.*?)>
.<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Результат поиска по всему регексу: «<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».
На результат поиска по группе можно ссылаться с помощью выражения
\n
, где n — цифра от 1 до 9. Например выражению(\w)(\w)\1\2
соответствуют строки «aaaa», «abab», но не соответствует «aabb».
Перечисление
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr
, Regexpal
или Regex101
. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper
— он умеет строить понятные диаграмы по регуляркам.RegExp Builder
— визуальный конструктор функций JavaScript для работы с регулярными выражениями.Больше инструментов можно найти в нашей подборке
.Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» — некорректное время.
Java[^script]
Ответы: нет, да.
- В строке Java он ничего не найдёт, так как исключающие квадратные скобки в Java[^…] означают «один символ, кроме указанных». А после «Java» – конец строки, символов больше нет.
- Да, найдёт. Поскольку регэксп регистрозависим, то под [^script] вполне подходит символ «S».
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
#[0-9a-fA-F]{6}Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: «+», «-», «*» и «/».
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного:
-?\d+(\.\d+)?
.(-?\d+(?:\.\d+)?)\s*([-+*\/])\s*(-?\d+(?:\.\d+)?)Кроссворды из регулярных выражений
Такие кроссворды
вы можете найти у нас.Удачи и помните — не всегда задачу стоит решать именно с помощью регекспов («У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы»). Иногда лучше
, например, написать развёрнутый автомат конечных состояний.Задачи и их разборы с javascript.ru
; в статье использованы комиксы xkcd
.Одним из принципов Unix-систем является широкое использование текстовых данных: конфигурационные файлы, входные и выходные данные программ в *nix часто организованы в виде обычного текста. Регулярные выражения — это мощный инструмент для манипуляции текстовой информацией. В этом гайде разберем тонкости работы с
регулярными выражениями Bash , которые помогут вам реализовать весь потенциал командной строки и скриптов в Linux.
Что такое регулярные выражения?
Регулярные выражения — это специальным образом записанные строки, используемые для поиска символьных шаблонов в тексте. Чем-то они похожи на групповые символы в оболочке, но их возможности куда шире. Многие утилиты для работы с текстом в Linux и языки программирования включают в себя механизм регулярных выражений. Здесь возникают проблемы: разные программы и языки оперируют различными диалектами регулярных выражений. В этой статье рассмотрим стандарт POSIX, которому соответствуют большинство утилит в Linux.
Программа
grep
— это основной инструмент для работы с регулярными выражениями. Grep анализирует данные со стандартного ввода, ищет совпадения с указанным шаблоном и выводит все подходящие строки.
Обычно grep предустановлен в большинстве дистрибутивов. Если хотите потренироваться в использовании регулярных выражений, можете повторять описанные команды в виртуальной машине, либо на
Grep имеет следующий синтаксис:
Самый простой случай использования grep — поиск строк, содержащих фиксированную подстроку. В следующем примере grep вывел все строки, содержащие последовательность nologin:
grep nologin /etc/passwdУ grep имеются множество параметров. Подробно с ними ознакомиться можно в документации. Приведем ключи, полезные при работе с регулярными выражениями:
Ключ
-v
— инвертировать критерий. В этом случае grep выводит строки, не содержащие совпадений:Ключ
-i
— игнорировать регистр символов.Ключ
-o
— выводить не строки, а только совпадения с шаблоном:Ключ
-w
— искать только строки, содержащие все слово, которое составляет шаблон.Для сравнения та же команда без опции. В вывод также попали строки, содержащие шаблон в качестве подслова в слове.
Basic Regular Expressions
Ранее упоминалось, что существует множество диалектов регулярных выражений. В стандарте POSIX рассматриваются два вида реализаций. Первый — Basic Regular Expressions (BRE). Ему соответствуют практически все POSIX-совместимые программы. Второй — Extended Regular Expression (ERE). Этот вид позволяет создавать более сложные регулярные выражения, но поддерживается не всеми утилитами. Для начала рассмотрим особенности BRE.
Метасимволы и литералы
В тексте выше мы уже столкнулись с простыми регулярными выражениями. К примеру, выражение «zip» обозначает строку, соответствующую следующим критериям: в строке не меньше трех символов; в строке присутствуют символы «z», «i», «p», причем именно в таком порядке; между ними нет других символов. Символы, соответствующие сами себе (как «z», «i», «p») называются литералами. Кроме того, существуют другая категория символов, называемая метасимволами. Они применяются для составления различных критериев поиска. К метасимволам в BRE относятся:
Чтобы использовать метасимвол в качестве литерала, его нужно экранировать с помощью обратного слэша (
\
). Обратите внимание, что некоторые метасимволы имеют специальное значение в оболочке. Поэтому при передаче регулярного выражения в аргумент команды его следует заключать в кавычки.Метасимвол «точка» (
.
) соответствует любому символу в данной позиции. Например:Здесь имеется один важный момент. Программа zip не вошла в вывод, так как метасимвол «точка» увеличил длину обязательного совпадения до четырех символов.
Символ «карет» (
^
) и «доллар» ($
) в регулярных выражениях играют роль якорей. Это означает, что в их присутствии совпадение с шаблоном возможно, только если оно будет найдено в начале строки (^
) или в ее конце ($
).Регулярное выражение
^$
будет соответствовать пустым строкам.Кроме описания совпадения с любым символом в заданной позиции (
.
) в регулярных выражениях имеется возможность описать символ из определенного множества. Делается это с помощью квадратных скобок. В следующем примере ищутся соответствия со строками bzip и gzip:Все метасимволы, кроме двух, теряют свое специальное значение внутри скобок.
Если сразу после открывающей квадратной скобки стоит символ карет (
^
), остальные символы множества интерпретируются как недопустимые в данной позиции. Например:Включив отрицание, мы получили список имен файлов, содержащих последовательность zip, которой предшествуют любой символ, кроме b или g. Обратите внимание, что имя zip не было найдено. Символ отрицания не отменяет необходимости присутствия символа в заданной позиции. Кроме того символ карет является отрицанием, только если стоит сразу же после открывающей скобки; в противном случае он теряет свое специальное значение.
С помощью дефиса (
-
) можно определять диапазоны символов. Так можно выразить любой диапазон символов и даже нескольких таких диапазонов. К примеру нам нужно найти все имена файлов, начинающиеся с буквы или цифры. Делается это так:Классы символов POSIX
Extended Regular Expressions
Особенности, рассматривавшиеся выше, поддерживаются практически всем POSIX-совместимыми приложениями и приложениями, реализующими BRE (например grep и потоковый редактор sed). Стандарт POSIX ERE позволяет создавать более выразительные регулярные выражения, однако не все программы умеют с ним работать. Диалект ERE поддерживался программой egrep, но GNU-версия grep также поддерживает расширенные регулярные выражения при вызове с ключом
-E
.В ERE множество метасимволов расширяются следующими:
Чередование позволяет выбирать совпадение с одним из нескольких выражений. Так же как выражения в квадратных скобках позволяют одному символу соответствовать множеству указанных символов, чередование позволяет находить совпадение с множеством строки или других регулярных выражений. Чередование обозначается метасимволом вертикальной черты:
Элементы регулярных выражений можно объединять и ссылаться на них как на один элемент. Делается это с помощью круглых скобок.
Следующее выражение будет соответствовать именам файлов, начинающихся с bz, gz или zip. Если отбросить круглые скобки, смысл регулярного выражения изменится, и ему будут соответствовать имена, начинающиеся с bz или содержащие gz, или zip.
Квантификаторы позволяют определить число совпадений с элементом. B RE поддерживают несколько способов.
Квантификатор
?
означает совпадение с элементом ноль или один раз. Иными словами совпадение с предыдущим элементом необязательно:В последнем случае совпадения не найдены, так как буква «s» встретилась дважды.
Подобно метасимволу
?
, звездочка (*
) обозначает необязательный элемент; однако, в отличие от знака вопроса, этот элемент может встречаться любое число раз, а не только единожды. Рассмотрим предыдущий пример, используя вместо знака вопроса звездочку:На этот раз все три строки совпали с шаблоном.
Метасимвол
+
действует почти так же, как*
, но требует совпадения с предыдущим элементом не менее одного раза:Теперь с шаблоном не совпала первая строка, так как метасимвол
+
требует хотя бы одного совпадения с предыдущим элементом.С шаблоном совпали только те строки, где буква s встречается один, два или три раза.
Регулярные выражения на практике
В качестве заключения рассмотрим пару примеров, как регулярные выражения могут использоваться на практике.
Проверка номеров телефонов
Допустим, у нас имеется список номеров телефонов. Корректный формат номера: (nnn) nnn-nnnn. В списке 10 номеров, три номера имеют некорректный формат.
cat phonenumbers.txt
Output:
(185) 136-1035
213-1874
207-2639
(285) 227-1602
(275) 298-1043
204-2197
(799) 240-1839
(218) 750-7390
776-2276
(7012) 219-3089Задача — найти неправильные номера. Для этого можно использовать следующую команду:
Здесь мы использовали параметр
-v
, чтобы обратить сопоставление и вывести только строки, не соответствующие указанному выражению. Поскольку круглые скобки считаются метасимволами в ERE, мы экранировали их обратными слешами, чтобы они интерпретировались как литералы.Поиск некорректных имен файлов
Команда find поддерживает проверку, основанную на регулярном выражении. Тут важно помнить одну деталь: если grep выводит строку, содержащую совпадение с регулярным выражением, то
find
требует точного совпадения пути. Допустим нам нужно найти в директории имена файлов и каталогов, содержащие пробелы и другие, потенциально вредные символы:Последовательность
.*
в начале и конце означает любое количество любых символов. Такой прием необходим, так какfind
требует совпадения всего пути. В квадратных скобках находится отрицание множества допустимых символов в именах файлов. Таким образом любое имя файла или каталога, содержащее хотя бы один символ, не являющиеся дефисом, подчеркиванием, цифрой или латинской буквой, попадет в вывод.В этой статье мы рассмотрели лишь несколько примеров практического применения регулярных выражений. В начале вам будет сложно придумывать длинные регулярки. Но со временем вы получите опыт, используя регулярные выражения для поиска в разных приложениях, поддерживающих такую возможность.
Кстати, в официальном канале Timeweb Cloud
собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Джон Бамбенек и Агнешка Клус
2009
Вступление
Скорее всего, если вы какое-то время работали в системе Linux в качестве системного администратора или разработчика, вы использовали команду grep
. Инструмент устанавливается по умолчанию почти на каждую установку Linux, BSD и Unix, независимо от дистрибутива, и даже доступен для Windows (с wingrep или через Cygwin).GNU и Free Software Foundation распространяют grep
как часть своего набора инструментов с открытым исходным кодом. Другие версии grep
распространяются для других операционных систем, но в этой книге основное внимание уделяется версии GNU, поскольку на данный момент она является наиболее распространенной.Команда grep
позволяет пользователю быстро и легко находить текст в заданном файле или выводить его. Предоставляя строку для поиска, grep
распечатает только строки, содержащие эту строку, и может распечатать соответствующие номера строк для этого текста. « Простое» использование команды хорошо известно, но существует множество более сложных применений, которые делают grep
мощным инструментом поиска.Цель этой книги - собрать всю информацию, которая может понадобиться администратору или разработчику, в небольшое руководство, которое можно носить с собой. Хотя «простое» использование grep
не требует особого образования, продвинутые приложения и использование регулярных выражений могут стать довольно сложными. Название инструмента фактически является аббревиатурой от «Global RegularExpression Print», что указывает на его назначение.GNU grep
на самом деле представляет собой комбинацию четырех различных инструментов, каждый со своим уникальным стилем поиска текста: основные регулярные выражения, расширенные регулярные выражения, фиксированные строки и регулярные выражения в стиле Perl. Существуют и другие реализации программ, подобных grep
, например, agrep, zipgrep и grep-подобные функции в . NET, PHP и SQL. В этом руководстве будут описаны особенности и сильные стороны каждого стиля.Официальный сайт grep
: http://www.gnu.org/software/grep/
. Он содержит информацию о проекте и некоторую краткую документацию. Исходный код grep
составляет всего 712 КБ, а текущая версия на момент написания - 2.5.3. Этот карманный справочник актуален для этой версии, но информация в целом будет действительна для более ранних и более поздних версий.Важно отметить, что текущая версия grep
, поставляемая с Mac OS X 10.5.5 - 2.5.1; тем не менее, большинство параметров в этой книге по-прежнему будут работать в этой версии. Помимо программы GNU, существуют и другие программы «grep», которые обычно устанавливаются по умолчанию в HP-UX, AIX и более старых версиях Solaris. По большей части синтаксис регулярных выражений в этих версиях очень похож, но параметры различаются. Эта книга имеет дело исключительно с версией GNU, потому что она более надежна и мощна, чем другие версии.Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
Обозначает команды, новые термины, URL-адреса, адреса электронной почты, имена файлов, расширения файлов, пути, каталоги и служебные программы Unix.
Указывает параметры, переключатели, переменные, атрибуты, ключи, функции, типы, классы, пространства имен, методы, модули, свойства, параметры, значения, объекты, события, обработчики событий, теги XML, теги HTML, макросы, содержимое файлов или вывод команд.
Моноширинный курсивный шрифт
Показывает текст, который следует заменить значениями, введенными пользователем.
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. Как правило, вы можете использовать код из этой книги в своих программах и документации. Вам не нужно связываться с нами для получения разрешения, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, не требуется разрешения. Для продажи или распространения компакт-дисков с примерами из книг О'Рейли требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и цитируя пример кода, не требуется разрешения. Для включения значительного количества примеров кода из этой книги в документацию по вашему продукту требуется разрешение.
Комментарии и вопросы
O'Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (в США или Канаде)
707-829-0515 (международный или местный)
707-829-0104 (факс)
У нас есть веб-страница для этой книги, где мы перечисляем исправления, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу:
Благодарности
От Джона Бамбенека
Я хотел бы поблагодарить Изабель Канкл и остальную команду О'Рейли, стоящую за редактированием и выпуском этой книги. Моя жена и сын заслуживают благодарности за поддержку и любовь, когда я завершил этот проект. Мой соавтор, Агнешка, сыграла неоценимую роль в облегчении выполнения обременительной задачи по написанию книги; она внесла большой вклад в этот проект. Брайан Кребс из The Washington Post
заслуживает похвалы за идею написания этой книги. Время, проведенное в Internet Storm Center, позволило мне поработать с некоторыми из лучших специалистов в области информационной безопасности, и их отзывы оказались чрезвычайно полезными в процессе технической проверки. Особая благодарность адресована Чарльзу Хэмби, Марку Хофману и Дональду Смиту. И, наконец, закусочная Merry Anne's Diner в центре Шампейна, штат Иллинойс, заслуживает благодарности за то, что позволила мне часами появляться среди ночи, чтобы занять один из их столиков, пока я это писал.От Агнешки Клус
Во-первых, я хочу поблагодарить своего соавтора Джона Бамбенека за возможность поработать над этой книгой. Для меня это определенно было литературным приключением. Это открыло окна возможностей и дало мне возможность заглянуть в мир, который иначе я бы попасть не смогла. Я также хотел бы поблагодарить мою семью и друзей за их поддержку и терпение.
Концептуальный обзор
Команда grep
предоставляет множество способов поиска строк текста в файле или потоке вывода. Например, можно найти все экземпляры указанного слова или строки в файле. Это может быть полезно, например, для извлечения определенных записей журнала из объемных системных журналов. В файлах можно искать определенные шаблоны, например типичный образец номера кредитной карты. Такая гибкость делает grep
мощным инструментом для обнаружения наличия (или отсутствия) информации в файлах. Есть два способа ввода данных в grep
, каждый из которых имеет свои особенности.Во-первых, grep
можно использовать для поиска заданного файла или файлов в системе. Например, файлы на диске можно искать на предмет наличия (или отсутствия) определенного содержимого. grep
также можно использовать для отправки вывода другой команды, которая затем будет искать желаемый контент. Например, grep
можно использовать для извлечения важной информации из команды, которая в противном случае выдает чрезмерный объем вывода.При поиске в текстовых файлах grep
можно использовать для поиска определенной строки во всех файлах во всей файловой системе. Например, номера социального страхования следуют известному шаблону, поэтому можно выполнить поиск в каждом текстовом файле в системе, чтобы найти вхождения этих номеров в его файлы (например, для академической среды, чтобы соответствовать федеральным законам о конфиденциальности). По умолчанию возвращается имя файла и строка текста, содержащая эту строку, но также можно включить номера строк.Кроме того, grep
может проверять вывод команды, чтобы найти вхождения строки. Например, системный администратор может запустить сценарий для обновления программного обеспечения в системе, которая имеет большой объем «отладочной» информации и может заботиться только о том, чтобы видеть сообщения об ошибках. В этом случае команда grep
может искать строку (например, «ERROR»), которая указывает на ошибки, отфильтровывая информацию, которую администратор не хочет видеть.Как правило, команда grep
предназначена для поиска только текстового вывода или текстовых файлов. Команда позволит вам искать двоичные (или другие нетекстовые) файлы, но в этом отношении утилита ограничена. Уловки для поиска информации в двоичных файлах с помощью grep
(т.е., с помощью команды strings) описаны в последнем разделе («Дополнительные советы и приемы с grep
»).Хотя обычно можно интегрировать grep
в управление текстом или выполнение операций «поиск и замена», это не самый эффективный способ выполнить работу. Программы sed
и awk
более удобны для выполнения таких функций.Есть два основных способа поиска с помощью grep
: поиск фиксированных строк и поиск шаблонов текста. Поиск фиксированных строк довольно прост. Однако поиск шаблона может очень быстро усложниться, в зависимости от того, насколько изменчив этот желаемый шаблон. Для поиска текста с переменным содержанием используйте регулярные выражения.По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
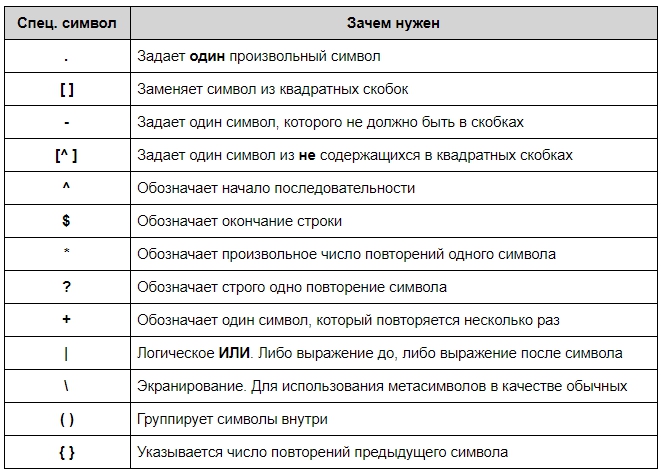
- \d
— соответствует любой одной цифре и заменяет собой выражение [0-9]
; - \D
— исключает все цифры и заменяет [^0-9]
; - \w
— заменяет любую цифру, букву, а также знак нижнего подчёркивания; - \W
— любой символ кроме латиницы, цифр или нижнего подчёркивания; - \s
— соответствует любому пробельному символу; - \S
— описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
В Python для работы с регулярками есть модуль re
. Его нужно просто импортировать:
import re А вот наиболее популярные методы, которые предоставляет модуль:
-
re.match() -
re.search() -
re.findall() -
re.split() -
re.sub() -
re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match()
на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
<_sre.SRE_Match object at 0x0000000009BE4370> Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group()
(мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AV Теперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None
:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV')
print result
Результат:
None Также есть методы start()
и end()
для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.start()
print result.end()
Результат:
0
2 Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match()
, но ищет не только в начале строки. В отличие от предыдущего, search()
вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
Analytics Метод search()
ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall()
нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall()
, так как он может работать и как re.search()
, и как re.match()
.
result = re.findall(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
['AV', 'AV'] re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics')
print result
Результат:
['Anal', 'tics'] В примере мы разделили слово «Analytics» по букве «y». Метод split()
принимает также аргумент maxsplit
со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
result = re.split(r'i', 'Analytics Vidhya')
print result
Результат:
['Analyt', 'cs V', 'dhya'] # все возможные участки. result = re.split(r'i', 'Analytics Vidhya',maxsplit=1)
print result
Результат:
['Analyt', 'cs Vidhya'] Мы установили параметр maxsplit
равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India')
print result
Результат:
'AV is largest Analytics community of the World' re.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV'] До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
Больше информации по специальным символам можно найти в документации
для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .
)
result = re.findall(r'.', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a'] Для того, чтобы в конечный результат не попал пробел, используем вместо .
\w
.
result = re.findall(r'\w', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a'] Теперь попробуем достать каждое слово (используя *
или +
)
result = re.findall(r'\w*', 'AV is largest Analytics community of India')
print result
Результат:
['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', ''] И снова в результат попали пробелы, так как *
означает «ноль или более символов». Для того, чтобы их убрать, используем +
:
result = re.findall(r'\w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India'] Теперь вытащим первое слово, используя ^
:
result = re.findall(r'^\w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV'] Если мы используем $
вместо ^
, то мы получим последнее слово, а не первое:
result = re.findall(r'\w+Что такое регулярные выражения?
Давайте разберёмся, что же собой представляют регулярные выражения. Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы «d», можно написать
rm d*.Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. Так, выражению
Хаха, очевидно, будет соответствовать строка «Хаха» и только она. Регулярки являются регистрозависимыми, поэтому строка «хаха» (с маленькой буквы) уже не будет соответствовать выражению выше.Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто
Хаханам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется
\s, для цифр —\d, для символов латиницы, цифр и подчёркивания «_» —\w.Если необходимо описать вообще любой символ, для этого используется точка —
.. Если указанные классы написать с заглавной буквы (\S,\D,\W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.Также с помощью регулярных выражений есть возможность проверить положение строки относительно остального текста. Выражение
\bобозначает границу слова,\B— не границу слова,^— начало текста, а$— конец. Так, по паттерну\bJava\bв строке «Java and JavaScript» найдутся первые 4 символа, а по паттерну\bJava\B— символы c 10-го по 13-й (в составе слова «JavaScript»).
Комикс про регулярные выражения с xkcd.ru
Диапазоны
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:
Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Очевидное решение
<*>здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строкаp><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</pРевнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части RegExp. Это называется ревнивой квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа
+. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттернуab*+aв строке «ababa» будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ «a», который стоит на третьей позиции, уже был использован для первого результата.Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение
<(.*?)>.<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Результат поиска по всему регексу: «<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».На результат поиска по группе можно ссылаться с помощью выражения
\n, где n — цифра от 1 до 9. Например выражению(\w)(\w)\1\2соответствуют строки «aaaa», «abab», но не соответствует «aabb».
Перечисление
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» — некорректное время.
Java[^script]
Ответы: нет, да.
- В строке Java он ничего не найдёт, так как исключающие квадратные скобки в Java[^…] означают «один символ, кроме указанных». А после «Java» – конец строки, символов больше нет.
- Да, найдёт. Поскольку регэксп регистрозависим, то под [^script] вполне подходит символ «S».
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
#[0-9a-fA-F]{6}Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: «+», «-», «*» и «/».
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного:
-?\d+(\.\d+)?.(-?\d+(?:\.\d+)?)\s*([-+*\/])\s*(-?\d+(?:\.\d+)?)Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
Удачи и помните — не всегда задачу стоит решать именно с помощью регекспов («У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы»). Иногда лучше, например, написать развёрнутый автомат конечных состояний.
Задачи и их разборы с javascript.ru; в статье использованы комиксы xkcd.
Одним из принципов Unix-систем является широкое использование текстовых данных: конфигурационные файлы, входные и выходные данные программ в *nix часто организованы в виде обычного текста. Регулярные выражения — это мощный инструмент для манипуляции текстовой информацией. В этом гайде разберем тонкости работы с регулярными выражениями Bash, которые помогут вам реализовать весь потенциал командной строки и скриптов в Linux.
Что такое регулярные выражения?
Регулярные выражения — это специальным образом записанные строки, используемые для поиска символьных шаблонов в тексте. Чем-то они похожи на групповые символы в оболочке, но их возможности куда шире. Многие утилиты для работы с текстом в Linux и языки программирования включают в себя механизм регулярных выражений. Здесь возникают проблемы: разные программы и языки оперируют различными диалектами регулярных выражений. В этой статье рассмотрим стандарт POSIX, которому соответствуют большинство утилит в Linux.
Программа
grep— это основной инструмент для работы с регулярными выражениями. Grep анализирует данные со стандартного ввода, ищет совпадения с указанным шаблоном и выводит все подходящие строки. Обычно grep предустановлен в большинстве дистрибутивов. Если хотите потренироваться в использовании регулярных выражений, можете повторять описанные команды в виртуальной машине, либо наGrep имеет следующий синтаксис:
Самый простой случай использования grep — поиск строк, содержащих фиксированную подстроку. В следующем примере grep вывел все строки, содержащие последовательность nologin:
grep nologin /etc/passwdУ grep имеются множество параметров. Подробно с ними ознакомиться можно в документации. Приведем ключи, полезные при работе с регулярными выражениями:
Ключ
-v— инвертировать критерий. В этом случае grep выводит строки, не содержащие совпадений:Ключ
-i— игнорировать регистр символов.Ключ
-o— выводить не строки, а только совпадения с шаблоном:Ключ
-w— искать только строки, содержащие все слово, которое составляет шаблон.Для сравнения та же команда без опции. В вывод также попали строки, содержащие шаблон в качестве подслова в слове.
Basic Regular Expressions
Ранее упоминалось, что существует множество диалектов регулярных выражений. В стандарте POSIX рассматриваются два вида реализаций. Первый — Basic Regular Expressions (BRE). Ему соответствуют практически все POSIX-совместимые программы. Второй — Extended Regular Expression (ERE). Этот вид позволяет создавать более сложные регулярные выражения, но поддерживается не всеми утилитами. Для начала рассмотрим особенности BRE.
Метасимволы и литералы
В тексте выше мы уже столкнулись с простыми регулярными выражениями. К примеру, выражение «zip» обозначает строку, соответствующую следующим критериям: в строке не меньше трех символов; в строке присутствуют символы «z», «i», «p», причем именно в таком порядке; между ними нет других символов. Символы, соответствующие сами себе (как «z», «i», «p») называются литералами. Кроме того, существуют другая категория символов, называемая метасимволами. Они применяются для составления различных критериев поиска. К метасимволам в BRE относятся:
Чтобы использовать метасимвол в качестве литерала, его нужно экранировать с помощью обратного слэша (
\). Обратите внимание, что некоторые метасимволы имеют специальное значение в оболочке. Поэтому при передаче регулярного выражения в аргумент команды его следует заключать в кавычки.Метасимвол «точка» (
.) соответствует любому символу в данной позиции. Например:Здесь имеется один важный момент. Программа zip не вошла в вывод, так как метасимвол «точка» увеличил длину обязательного совпадения до четырех символов.
Символ «карет» (
^) и «доллар» ($) в регулярных выражениях играют роль якорей. Это означает, что в их присутствии совпадение с шаблоном возможно, только если оно будет найдено в начале строки (^) или в ее конце ($).Регулярное выражение
^$будет соответствовать пустым строкам.Кроме описания совпадения с любым символом в заданной позиции (
.) в регулярных выражениях имеется возможность описать символ из определенного множества. Делается это с помощью квадратных скобок. В следующем примере ищутся соответствия со строками bzip и gzip:Все метасимволы, кроме двух, теряют свое специальное значение внутри скобок.
Если сразу после открывающей квадратной скобки стоит символ карет (
^), остальные символы множества интерпретируются как недопустимые в данной позиции. Например:Включив отрицание, мы получили список имен файлов, содержащих последовательность zip, которой предшествуют любой символ, кроме b или g. Обратите внимание, что имя zip не было найдено. Символ отрицания не отменяет необходимости присутствия символа в заданной позиции. Кроме того символ карет является отрицанием, только если стоит сразу же после открывающей скобки; в противном случае он теряет свое специальное значение.
С помощью дефиса (
-) можно определять диапазоны символов. Так можно выразить любой диапазон символов и даже нескольких таких диапазонов. К примеру нам нужно найти все имена файлов, начинающиеся с буквы или цифры. Делается это так:Классы символов POSIX
Extended Regular Expressions
Особенности, рассматривавшиеся выше, поддерживаются практически всем POSIX-совместимыми приложениями и приложениями, реализующими BRE (например grep и потоковый редактор sed). Стандарт POSIX ERE позволяет создавать более выразительные регулярные выражения, однако не все программы умеют с ним работать. Диалект ERE поддерживался программой egrep, но GNU-версия grep также поддерживает расширенные регулярные выражения при вызове с ключом
-E.В ERE множество метасимволов расширяются следующими:
Чередование позволяет выбирать совпадение с одним из нескольких выражений. Так же как выражения в квадратных скобках позволяют одному символу соответствовать множеству указанных символов, чередование позволяет находить совпадение с множеством строки или других регулярных выражений. Чередование обозначается метасимволом вертикальной черты:
Элементы регулярных выражений можно объединять и ссылаться на них как на один элемент. Делается это с помощью круглых скобок.
Следующее выражение будет соответствовать именам файлов, начинающихся с bz, gz или zip. Если отбросить круглые скобки, смысл регулярного выражения изменится, и ему будут соответствовать имена, начинающиеся с bz или содержащие gz, или zip.
Квантификаторы позволяют определить число совпадений с элементом. B RE поддерживают несколько способов.
Квантификатор
?означает совпадение с элементом ноль или один раз. Иными словами совпадение с предыдущим элементом необязательно:В последнем случае совпадения не найдены, так как буква «s» встретилась дважды.
Подобно метасимволу
?, звездочка (*) обозначает необязательный элемент; однако, в отличие от знака вопроса, этот элемент может встречаться любое число раз, а не только единожды. Рассмотрим предыдущий пример, используя вместо знака вопроса звездочку:На этот раз все три строки совпали с шаблоном.
Метасимвол
+действует почти так же, как*, но требует совпадения с предыдущим элементом не менее одного раза:Теперь с шаблоном не совпала первая строка, так как метасимвол
+требует хотя бы одного совпадения с предыдущим элементом.С шаблоном совпали только те строки, где буква s встречается один, два или три раза.
Регулярные выражения на практике
В качестве заключения рассмотрим пару примеров, как регулярные выражения могут использоваться на практике.
Проверка номеров телефонов
Допустим, у нас имеется список номеров телефонов. Корректный формат номера: (nnn) nnn-nnnn. В списке 10 номеров, три номера имеют некорректный формат.
cat phonenumbers.txt
Output:
(185) 136-1035
(95) 213-1874
(37) 207-2639
(285) 227-1602
(275) 298-1043
(107) 204-2197
(799) 240-1839
(218) 750-7390
(114) 776-2276
(7012) 219-3089Задача — найти неправильные номера. Для этого можно использовать следующую команду:
Здесь мы использовали параметр
-v, чтобы обратить сопоставление и вывести только строки, не соответствующие указанному выражению. Поскольку круглые скобки считаются метасимволами в ERE, мы экранировали их обратными слешами, чтобы они интерпретировались как литералы.Поиск некорректных имен файлов
Команда find поддерживает проверку, основанную на регулярном выражении. Тут важно помнить одну деталь: если grep выводит строку, содержащую совпадение с регулярным выражением, то
findтребует точного совпадения пути. Допустим нам нужно найти в директории имена файлов и каталогов, содержащие пробелы и другие, потенциально вредные символы:Последовательность
.*в начале и конце означает любое количество любых символов. Такой прием необходим, так какfindтребует совпадения всего пути. В квадратных скобках находится отрицание множества допустимых символов в именах файлов. Таким образом любое имя файла или каталога, содержащее хотя бы один символ, не являющиеся дефисом, подчеркиванием, цифрой или латинской буквой, попадет в вывод.В этой статье мы рассмотрели лишь несколько примеров практического применения регулярных выражений. В начале вам будет сложно придумывать длинные регулярки. Но со временем вы получите опыт, используя регулярные выражения для поиска в разных приложениях, поддерживающих такую возможность.
Кстати, в официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Джон Бамбенек и Агнешка Клус
2009Вступление
Скорее всего, если вы какое-то время работали в системе Linux в качестве системного администратора или разработчика, вы использовали команду grep. Инструмент устанавливается по умолчанию почти на каждую установку Linux, BSD и Unix, независимо от дистрибутива, и даже доступен для Windows (с wingrep или через Cygwin).
GNU и Free Software Foundation распространяют grep как часть своего набора инструментов с открытым исходным кодом. Другие версии grep распространяются для других операционных систем, но в этой книге основное внимание уделяется версии GNU, поскольку на данный момент она является наиболее распространенной.
Команда grep позволяет пользователю быстро и легко находить текст в заданном файле или выводить его. Предоставляя строку для поиска, grep распечатает только строки, содержащие эту строку, и может распечатать соответствующие номера строк для этого текста. « Простое» использование команды хорошо известно, но существует множество более сложных применений, которые делают grep мощным инструментом поиска.
Цель этой книги - собрать всю информацию, которая может понадобиться администратору или разработчику, в небольшое руководство, которое можно носить с собой. Хотя «простое» использование grep не требует особого образования, продвинутые приложения и использование регулярных выражений могут стать довольно сложными. Название инструмента фактически является аббревиатурой от «Global RegularExpression Print», что указывает на его назначение.
GNU grep на самом деле представляет собой комбинацию четырех различных инструментов, каждый со своим уникальным стилем поиска текста: основные регулярные выражения, расширенные регулярные выражения, фиксированные строки и регулярные выражения в стиле Perl. Существуют и другие реализации программ, подобных grep, например, agrep, zipgrep и grep-подобные функции в . NET, PHP и SQL. В этом руководстве будут описаны особенности и сильные стороны каждого стиля.
Официальный сайт grep: http://www.gnu.org/software/grep/. Он содержит информацию о проекте и некоторую краткую документацию. Исходный код grep составляет всего 712 КБ, а текущая версия на момент написания - 2.5.3. Этот карманный справочник актуален для этой версии, но информация в целом будет действительна для более ранних и более поздних версий.
Важно отметить, что текущая версия grep, поставляемая с Mac OS X 10.5.5 - 2.5.1; тем не менее, большинство параметров в этой книге по-прежнему будут работать в этой версии. Помимо программы GNU, существуют и другие программы «grep», которые обычно устанавливаются по умолчанию в HP-UX, AIX и более старых версиях Solaris. По большей части синтаксис регулярных выражений в этих версиях очень похож, но параметры различаются. Эта книга имеет дело исключительно с версией GNU, потому что она более надежна и мощна, чем другие версии.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
Обозначает команды, новые термины, URL-адреса, адреса электронной почты, имена файлов, расширения файлов, пути, каталоги и служебные программы Unix.
Указывает параметры, переключатели, переменные, атрибуты, ключи, функции, типы, классы, пространства имен, методы, модули, свойства, параметры, значения, объекты, события, обработчики событий, теги XML, теги HTML, макросы, содержимое файлов или вывод команд.
Моноширинный курсивный шрифт
Показывает текст, который следует заменить значениями, введенными пользователем.
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. Как правило, вы можете использовать код из этой книги в своих программах и документации. Вам не нужно связываться с нами для получения разрешения, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, не требуется разрешения. Для продажи или распространения компакт-дисков с примерами из книг О'Рейли требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и цитируя пример кода, не требуется разрешения. Для включения значительного количества примеров кода из этой книги в документацию по вашему продукту требуется разрешение.
Комментарии и вопросы
O'Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (в США или Канаде)
707-829-0515 (международный или местный)
707-829-0104 (факс)У нас есть веб-страница для этой книги, где мы перечисляем исправления, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу:
Благодарности
От Джона Бамбенека
Я хотел бы поблагодарить Изабель Канкл и остальную команду О'Рейли, стоящую за редактированием и выпуском этой книги. Моя жена и сын заслуживают благодарности за поддержку и любовь, когда я завершил этот проект. Мой соавтор, Агнешка, сыграла неоценимую роль в облегчении выполнения обременительной задачи по написанию книги; она внесла большой вклад в этот проект. Брайан Кребс из The Washington Post заслуживает похвалы за идею написания этой книги. Время, проведенное в Internet Storm Center, позволило мне поработать с некоторыми из лучших специалистов в области информационной безопасности, и их отзывы оказались чрезвычайно полезными в процессе технической проверки. Особая благодарность адресована Чарльзу Хэмби, Марку Хофману и Дональду Смиту. И, наконец, закусочная Merry Anne's Diner в центре Шампейна, штат Иллинойс, заслуживает благодарности за то, что позволила мне часами появляться среди ночи, чтобы занять один из их столиков, пока я это писал.
От Агнешки Клус
Во-первых, я хочу поблагодарить своего соавтора Джона Бамбенека за возможность поработать над этой книгой. Для меня это определенно было литературным приключением. Это открыло окна возможностей и дало мне возможность заглянуть в мир, который иначе я бы попасть не смогла. Я также хотел бы поблагодарить мою семью и друзей за их поддержку и терпение.
Концептуальный обзор
Команда grep предоставляет множество способов поиска строк текста в файле или потоке вывода. Например, можно найти все экземпляры указанного слова или строки в файле. Это может быть полезно, например, для извлечения определенных записей журнала из объемных системных журналов. В файлах можно искать определенные шаблоны, например типичный образец номера кредитной карты. Такая гибкость делает grep мощным инструментом для обнаружения наличия (или отсутствия) информации в файлах. Есть два способа ввода данных в grep, каждый из которых имеет свои особенности.
Во-первых, grep можно использовать для поиска заданного файла или файлов в системе. Например, файлы на диске можно искать на предмет наличия (или отсутствия) определенного содержимого. grep также можно использовать для отправки вывода другой команды, которая затем будет искать желаемый контент. Например, grep можно использовать для извлечения важной информации из команды, которая в противном случае выдает чрезмерный объем вывода.
При поиске в текстовых файлах grep можно использовать для поиска определенной строки во всех файлах во всей файловой системе. Например, номера социального страхования следуют известному шаблону, поэтому можно выполнить поиск в каждом текстовом файле в системе, чтобы найти вхождения этих номеров в его файлы (например, для академической среды, чтобы соответствовать федеральным законам о конфиденциальности). По умолчанию возвращается имя файла и строка текста, содержащая эту строку, но также можно включить номера строк.
Кроме того, grep может проверять вывод команды, чтобы найти вхождения строки. Например, системный администратор может запустить сценарий для обновления программного обеспечения в системе, которая имеет большой объем «отладочной» информации и может заботиться только о том, чтобы видеть сообщения об ошибках. В этом случае команда grep может искать строку (например, «ERROR»), которая указывает на ошибки, отфильтровывая информацию, которую администратор не хочет видеть.
Как правило, команда grep предназначена для поиска только текстового вывода или текстовых файлов. Команда позволит вам искать двоичные (или другие нетекстовые) файлы, но в этом отношении утилита ограничена. Уловки для поиска информации в двоичных файлах с помощью grep (т.е., с помощью команды strings) описаны в последнем разделе («Дополнительные советы и приемы с grep»).
Хотя обычно можно интегрировать grep в управление текстом или выполнение операций «поиск и замена», это не самый эффективный способ выполнить работу. Программы sed и awk более удобны для выполнения таких функций.
Есть два основных способа поиска с помощью grep: поиск фиксированных строк и поиск шаблонов текста. Поиск фиксированных строк довольно прост. Однако поиск шаблона может очень быстро усложниться, в зависимости от того, насколько изменчив этот желаемый шаблон. Для поиска текста с переменным содержанием используйте регулярные выражения.
, 'AV is largest Analytics community of India')
print resultРезультат:
[‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя
\w, вытащить два последовательных символа, кроме пробельных, из каждого слова:result = re.findall(r'\w\w', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (
\b
):result = re.findall(r'\b\w.', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
result = re.findall(r'@\w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz') print result Результат: ['@gmail', '@test', '@analyticsvidhya', '@rest']Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@\w+.\w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz') print result Результат: ['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку —
( )
:result = re.findall(r'@\w+.(\w+)', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz') print result Результат: ['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем
\dдля извлечения цифр.result = re.findall(r'\d{2}-\d{2}-\d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009') print result Результат: ['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.findall(r'\d{2}-\d{2}-(\d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009') print result Результат: ['2007', '2011', '2009']Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']result = re.findall(r'[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем
\bдля обозначения границы слова:result = re.findall(r'\b[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать
^внутри квадратных скобок для инвертирования группы:result = re.findall(r'\b[^aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: [' is', ' largest', ' Analytics', ' community', ' of', ' India']В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
result = re.findall(r'\b[^aeiouAEIOU ]\w+', 'AV is largest Analytics community of India') print result Результат: ['largest', 'community']Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999'] for val in li: if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10: print 'yes' else: print 'no' Результат: yes no noРазбить строку по нескольким разделителям
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," "). result = re.split(r'[;,\s]', line) print result Результат: ['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод
re.sub()
для замены всех разделителей пробелами:line = 'asdf fjdk;afed,fjek,asdf,foo' result = re.sub(r'[;,\s]',' ', line) print result Результат: asdf fjdk afed fjek asdf fooИзвлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между
<td>
и</td>
, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную
test_str
):result = re.findall(r'\d([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str) print result Результат: [('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»
Что такое регулярные выражения?
Давайте разберёмся, что же собой представляют регулярные выражения. Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы «d», можно написать rm d*.
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. Так, выражению Хаха, очевидно, будет соответствовать строка «Хаха» и только она. Регулярки являются регистрозависимыми, поэтому строка «хаха» (с маленькой буквы) уже не будет соответствовать выражению выше.
Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто Хаха нам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.
Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется \s, для цифр — \d, для символов латиницы, цифр и подчёркивания «_» — \w.
Если необходимо описать вообще любой символ, для этого используется точка — .. Если указанные классы написать с заглавной буквы (\S, \D, \W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.
Также с помощью регулярных выражений есть возможность проверить положение строки относительно остального текста. Выражение \b обозначает границу слова, \B — не границу слова, ^ — начало текста, а $ — конец. Так, по паттерну \bJava\b в строке «Java and JavaScript» найдутся первые 4 символа, а по паттерну \bJava\B — символы c 10-го по 13-й (в составе слова «JavaScript»).
Комикс про регулярные выражения с xkcd.ru
Диапазоны
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:
Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Очевидное решение <.*> здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</pРевнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части RegExp. Это называется ревнивой квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа +. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттерну ab*+a в строке «ababa» будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ «a», который стоит на третьей позиции, уже был использован для первого результата.
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение <(.*?)>.
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Результат поиска по всему регексу: «<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».
На результат поиска по группе можно ссылаться с помощью выражения \n, где n — цифра от 1 до 9. Например выражению (\w)(\w)\1\2 соответствуют строки «aaaa», «abab», но не соответствует «aabb».

Перечисление
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» — некорректное время.
Java[^script]
Ответы: нет, да.
- В строке Java он ничего не найдёт, так как исключающие квадратные скобки в Java[^…] означают «один символ, кроме указанных». А после «Java» – конец строки, символов больше нет.
- Да, найдёт. Поскольку регэксп регистрозависим, то под [^script] вполне подходит символ «S».
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
#[0-9a-fA-F]{6}Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: «+», «-», «*» и «/».
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного: -?\d+(\.\d+)?.
(-?\d+(?:\.\d+)?)\s*([-+*\/])\s*(-?\d+(?:\.\d+)?)Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
Удачи и помните — не всегда задачу стоит решать именно с помощью регекспов («У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы»). Иногда лучше, например, написать развёрнутый автомат конечных состояний.
Задачи и их разборы с javascript.ru; в статье использованы комиксы xkcd.
Одним из принципов Unix-систем является широкое использование текстовых данных: конфигурационные файлы, входные и выходные данные программ в *nix часто организованы в виде обычного текста. Регулярные выражения — это мощный инструмент для манипуляции текстовой информацией. В этом гайде разберем тонкости работы с регулярными выражениями Bash, которые помогут вам реализовать весь потенциал командной строки и скриптов в Linux.
Что такое регулярные выражения?
Регулярные выражения — это специальным образом записанные строки, используемые для поиска символьных шаблонов в тексте. Чем-то они похожи на групповые символы в оболочке, но их возможности куда шире. Многие утилиты для работы с текстом в Linux и языки программирования включают в себя механизм регулярных выражений. Здесь возникают проблемы: разные программы и языки оперируют различными диалектами регулярных выражений. В этой статье рассмотрим стандарт POSIX, которому соответствуют большинство утилит в Linux.
Программа grep — это основной инструмент для работы с регулярными выражениями. Grep анализирует данные со стандартного ввода, ищет совпадения с указанным шаблоном и выводит все подходящие строки. Обычно grep предустановлен в большинстве дистрибутивов. Если хотите потренироваться в использовании регулярных выражений, можете повторять описанные команды в виртуальной машине, либо на
Grep имеет следующий синтаксис:
Самый простой случай использования grep — поиск строк, содержащих фиксированную подстроку. В следующем примере grep вывел все строки, содержащие последовательность nologin:
grep nologin /etc/passwdУ grep имеются множество параметров. Подробно с ними ознакомиться можно в документации. Приведем ключи, полезные при работе с регулярными выражениями:
Ключ -v — инвертировать критерий. В этом случае grep выводит строки, не содержащие совпадений:
Ключ -i — игнорировать регистр символов.
Ключ -o — выводить не строки, а только совпадения с шаблоном:
Ключ -w — искать только строки, содержащие все слово, которое составляет шаблон.
Для сравнения та же команда без опции. В вывод также попали строки, содержащие шаблон в качестве подслова в слове.
Basic Regular Expressions
Ранее упоминалось, что существует множество диалектов регулярных выражений. В стандарте POSIX рассматриваются два вида реализаций. Первый — Basic Regular Expressions (BRE). Ему соответствуют практически все POSIX-совместимые программы. Второй — Extended Regular Expression (ERE). Этот вид позволяет создавать более сложные регулярные выражения, но поддерживается не всеми утилитами. Для начала рассмотрим особенности BRE.
Метасимволы и литералы
В тексте выше мы уже столкнулись с простыми регулярными выражениями. К примеру, выражение «zip» обозначает строку, соответствующую следующим критериям: в строке не меньше трех символов; в строке присутствуют символы «z», «i», «p», причем именно в таком порядке; между ними нет других символов. Символы, соответствующие сами себе (как «z», «i», «p») называются литералами. Кроме того, существуют другая категория символов, называемая метасимволами. Они применяются для составления различных критериев поиска. К метасимволам в BRE относятся:
Чтобы использовать метасимвол в качестве литерала, его нужно экранировать с помощью обратного слэша (\). Обратите внимание, что некоторые метасимволы имеют специальное значение в оболочке. Поэтому при передаче регулярного выражения в аргумент команды его следует заключать в кавычки.
Метасимвол «точка» (.) соответствует любому символу в данной позиции. Например:
Здесь имеется один важный момент. Программа zip не вошла в вывод, так как метасимвол «точка» увеличил длину обязательного совпадения до четырех символов.
Символ «карет» (^) и «доллар» ($) в регулярных выражениях играют роль якорей. Это означает, что в их присутствии совпадение с шаблоном возможно, только если оно будет найдено в начале строки (^) или в ее конце ($).
Регулярное выражение ^$ будет соответствовать пустым строкам.
Кроме описания совпадения с любым символом в заданной позиции (.) в регулярных выражениях имеется возможность описать символ из определенного множества. Делается это с помощью квадратных скобок. В следующем примере ищутся соответствия со строками bzip и gzip:
Все метасимволы, кроме двух, теряют свое специальное значение внутри скобок.
Если сразу после открывающей квадратной скобки стоит символ карет (^), остальные символы множества интерпретируются как недопустимые в данной позиции. Например:
Включив отрицание, мы получили список имен файлов, содержащих последовательность zip, которой предшествуют любой символ, кроме b или g. Обратите внимание, что имя zip не было найдено. Символ отрицания не отменяет необходимости присутствия символа в заданной позиции. Кроме того символ карет является отрицанием, только если стоит сразу же после открывающей скобки; в противном случае он теряет свое специальное значение.
С помощью дефиса (-) можно определять диапазоны символов. Так можно выразить любой диапазон символов и даже нескольких таких диапазонов. К примеру нам нужно найти все имена файлов, начинающиеся с буквы или цифры. Делается это так:
Классы символов POSIX
Extended Regular Expressions
Особенности, рассматривавшиеся выше, поддерживаются практически всем POSIX-совместимыми приложениями и приложениями, реализующими BRE (например grep и потоковый редактор sed). Стандарт POSIX ERE позволяет создавать более выразительные регулярные выражения, однако не все программы умеют с ним работать. Диалект ERE поддерживался программой egrep, но GNU-версия grep также поддерживает расширенные регулярные выражения при вызове с ключом -E.
В ERE множество метасимволов расширяются следующими:
Чередование позволяет выбирать совпадение с одним из нескольких выражений. Так же как выражения в квадратных скобках позволяют одному символу соответствовать множеству указанных символов, чередование позволяет находить совпадение с множеством строки или других регулярных выражений. Чередование обозначается метасимволом вертикальной черты:
Элементы регулярных выражений можно объединять и ссылаться на них как на один элемент. Делается это с помощью круглых скобок.
Следующее выражение будет соответствовать именам файлов, начинающихся с bz, gz или zip. Если отбросить круглые скобки, смысл регулярного выражения изменится, и ему будут соответствовать имена, начинающиеся с bz или содержащие gz, или zip.
Квантификаторы позволяют определить число совпадений с элементом. B RE поддерживают несколько способов.
Квантификатор ? означает совпадение с элементом ноль или один раз. Иными словами совпадение с предыдущим элементом необязательно:
В последнем случае совпадения не найдены, так как буква «s» встретилась дважды.
Подобно метасимволу ?, звездочка (*) обозначает необязательный элемент; однако, в отличие от знака вопроса, этот элемент может встречаться любое число раз, а не только единожды. Рассмотрим предыдущий пример, используя вместо знака вопроса звездочку:
На этот раз все три строки совпали с шаблоном.
Метасимвол + действует почти так же, как *, но требует совпадения с предыдущим элементом не менее одного раза:
Теперь с шаблоном не совпала первая строка, так как метасимвол + требует хотя бы одного совпадения с предыдущим элементом.
С шаблоном совпали только те строки, где буква s встречается один, два или три раза.
Регулярные выражения на практике
В качестве заключения рассмотрим пару примеров, как регулярные выражения могут использоваться на практике.
Проверка номеров телефонов
Допустим, у нас имеется список номеров телефонов. Корректный формат номера: (nnn) nnn-nnnn. В списке 10 номеров, три номера имеют некорректный формат.
cat phonenumbers.txt
Output:
(185) 136-1035
(95) 213-1874
(37) 207-2639
(285) 227-1602
(275) 298-1043
(107) 204-2197
(799) 240-1839
(218) 750-7390
(114) 776-2276
(7012) 219-3089 Задача — найти неправильные номера. Для этого можно использовать следующую команду:
Здесь мы использовали параметр -v, чтобы обратить сопоставление и вывести только строки, не соответствующие указанному выражению. Поскольку круглые скобки считаются метасимволами в ERE, мы экранировали их обратными слешами, чтобы они интерпретировались как литералы.
Поиск некорректных имен файлов
Команда find поддерживает проверку, основанную на регулярном выражении. Тут важно помнить одну деталь: если grep выводит строку, содержащую совпадение с регулярным выражением, то find требует точного совпадения пути. Допустим нам нужно найти в директории имена файлов и каталогов, содержащие пробелы и другие, потенциально вредные символы:
Последовательность .* в начале и конце означает любое количество любых символов. Такой прием необходим, так как find требует совпадения всего пути. В квадратных скобках находится отрицание множества допустимых символов в именах файлов. Таким образом любое имя файла или каталога, содержащее хотя бы один символ, не являющиеся дефисом, подчеркиванием, цифрой или латинской буквой, попадет в вывод.
В этой статье мы рассмотрели лишь несколько примеров практического применения регулярных выражений. В начале вам будет сложно придумывать длинные регулярки. Но со временем вы получите опыт, используя регулярные выражения для поиска в разных приложениях, поддерживающих такую возможность.
Кстати, в официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Джон Бамбенек и Агнешка Клус
2009
Вступление
Скорее всего, если вы какое-то время работали в системе Linux в качестве системного администратора или разработчика, вы использовали команду grep. Инструмент устанавливается по умолчанию почти на каждую установку Linux, BSD и Unix, независимо от дистрибутива, и даже доступен для Windows (с wingrep или через Cygwin).
GNU и Free Software Foundation распространяют grep как часть своего набора инструментов с открытым исходным кодом. Другие версии grep распространяются для других операционных систем, но в этой книге основное внимание уделяется версии GNU, поскольку на данный момент она является наиболее распространенной.
Команда grep позволяет пользователю быстро и легко находить текст в заданном файле или выводить его. Предоставляя строку для поиска, grep распечатает только строки, содержащие эту строку, и может распечатать соответствующие номера строк для этого текста. « Простое» использование команды хорошо известно, но существует множество более сложных применений, которые делают grep мощным инструментом поиска.
Цель этой книги – собрать всю информацию, которая может понадобиться администратору или разработчику, в небольшое руководство, которое можно носить с собой. Хотя «простое» использование grep не требует особого образования, продвинутые приложения и использование регулярных выражений могут стать довольно сложными. Название инструмента фактически является аббревиатурой от «Global RegularExpression Print», что указывает на его назначение.
GNU grep на самом деле представляет собой комбинацию четырех различных инструментов, каждый со своим уникальным стилем поиска текста: основные регулярные выражения, расширенные регулярные выражения, фиксированные строки и регулярные выражения в стиле Perl. Существуют и другие реализации программ, подобных grep, например, agrep, zipgrep и grep-подобные функции в . NET, PHP и SQL. В этом руководстве будут описаны особенности и сильные стороны каждого стиля.
Официальный сайт grep: http://www.gnu.org/software/grep/. Он содержит информацию о проекте и некоторую краткую документацию. Исходный код grep составляет всего 712 КБ, а текущая версия на момент написания – 2.5.3. Этот карманный справочник актуален для этой версии, но информация в целом будет действительна для более ранних и более поздних версий.
Важно отметить, что текущая версия grep, поставляемая с Mac OS X 10.5.5 – 2.5.1; тем не менее, большинство параметров в этой книге по-прежнему будут работать в этой версии. Помимо программы GNU, существуют и другие программы «grep», которые обычно устанавливаются по умолчанию в HP-UX, AIX и более старых версиях Solaris. По большей части синтаксис регулярных выражений в этих версиях очень похож, но параметры различаются. Эта книга имеет дело исключительно с версией GNU, потому что она более надежна и мощна, чем другие версии.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
Обозначает команды, новые термины, URL-адреса, адреса электронной почты, имена файлов, расширения файлов, пути, каталоги и служебные программы Unix.
Указывает параметры, переключатели, переменные, атрибуты, ключи, функции, типы, классы, пространства имен, методы, модули, свойства, параметры, значения, объекты, события, обработчики событий, теги XML, теги HTML, макросы, содержимое файлов или вывод команд.
Моноширинный курсивный шрифт
Показывает текст, который следует заменить значениями, введенными пользователем.
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. Как правило, вы можете использовать код из этой книги в своих программах и документации. Вам не нужно связываться с нами для получения разрешения, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, не требуется разрешения. Для продажи или распространения компакт-дисков с примерами из книг О’Рейли требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и цитируя пример кода, не требуется разрешения. Для включения значительного количества примеров кода из этой книги в документацию по вашему продукту требуется разрешение.
Комментарии и вопросы
O’Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (в США или Канаде)
707-829-0515 (международный или местный)
707-829-0104 (факс)
У нас есть веб-страница для этой книги, где мы перечисляем исправления, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу:
Благодарности
От Джона Бамбенека
Я хотел бы поблагодарить Изабель Канкл и остальную команду О’Рейли, стоящую за редактированием и выпуском этой книги. Моя жена и сын заслуживают благодарности за поддержку и любовь, когда я завершил этот проект. Мой соавтор, Агнешка, сыграла неоценимую роль в облегчении выполнения обременительной задачи по написанию книги; она внесла большой вклад в этот проект. Брайан Кребс из The Washington Post заслуживает похвалы за идею написания этой книги. Время, проведенное в Internet Storm Center, позволило мне поработать с некоторыми из лучших специалистов в области информационной безопасности, и их отзывы оказались чрезвычайно полезными в процессе технической проверки. Особая благодарность адресована Чарльзу Хэмби, Марку Хофману и Дональду Смиту. И, наконец, закусочная Merry Anne’s Diner в центре Шампейна, штат Иллинойс, заслуживает благодарности за то, что позволила мне часами появляться среди ночи, чтобы занять один из их столиков, пока я это писал.
От Агнешки Клус
Во-первых, я хочу поблагодарить своего соавтора Джона Бамбенека за возможность поработать над этой книгой. Для меня это определенно было литературным приключением. Это открыло окна возможностей и дало мне возможность заглянуть в мир, который иначе я бы попасть не смогла. Я также хотел бы поблагодарить мою семью и друзей за их поддержку и терпение.
Концептуальный обзор
Команда grep предоставляет множество способов поиска строк текста в файле или потоке вывода. Например, можно найти все экземпляры указанного слова или строки в файле. Это может быть полезно, например, для извлечения определенных записей журнала из объемных системных журналов. В файлах можно искать определенные шаблоны, например типичный образец номера кредитной карты. Такая гибкость делает grep мощным инструментом для обнаружения наличия (или отсутствия) информации в файлах. Есть два способа ввода данных в grep, каждый из которых имеет свои особенности.
Во-первых, grep можно использовать для поиска заданного файла или файлов в системе. Например, файлы на диске можно искать на предмет наличия (или отсутствия) определенного содержимого. grep также можно использовать для отправки вывода другой команды, которая затем будет искать желаемый контент. Например, grep можно использовать для извлечения важной информации из команды, которая в противном случае выдает чрезмерный объем вывода.
При поиске в текстовых файлах grep можно использовать для поиска определенной строки во всех файлах во всей файловой системе. Например, номера социального страхования следуют известному шаблону, поэтому можно выполнить поиск в каждом текстовом файле в системе, чтобы найти вхождения этих номеров в его файлы (например, для академической среды, чтобы соответствовать федеральным законам о конфиденциальности). По умолчанию возвращается имя файла и строка текста, содержащая эту строку, но также можно включить номера строк.
Кроме того, grep может проверять вывод команды, чтобы найти вхождения строки. Например, системный администратор может запустить сценарий для обновления программного обеспечения в системе, которая имеет большой объем «отладочной» информации и может заботиться только о том, чтобы видеть сообщения об ошибках. В этом случае команда grep может искать строку (например, «ERROR»), которая указывает на ошибки, отфильтровывая информацию, которую администратор не хочет видеть.
Как правило, команда grep предназначена для поиска только текстового вывода или текстовых файлов. Команда позволит вам искать двоичные (или другие нетекстовые) файлы, но в этом отношении утилита ограничена. Уловки для поиска информации в двоичных файлах с помощью grep (т.е., с помощью команды strings) описаны в последнем разделе («Дополнительные советы и приемы с grep»).
Хотя обычно можно интегрировать grep в управление текстом или выполнение операций «поиск и замена», это не самый эффективный способ выполнить работу. Программы sed и awk более удобны для выполнения таких функций.
Есть два основных способа поиска с помощью grep: поиск фиксированных строк и поиск шаблонов текста. Поиск фиксированных строк довольно прост. Однако поиск шаблона может очень быстро усложниться, в зависимости от того, насколько изменчив этот желаемый шаблон. Для поиска текста с переменным содержанием используйте регулярные выражения.</p



