
")
Utf-16 on cmd.exe
Yeah,I’ve just resolved my problem. It was a fault of default font in cmd.exe which can’t manage unicode signs. To fix it(windows 7 x64 pro):
- Open/run
cmd.exe - Click on the icon at the top-left corner
- Select properties
- Then “Font” bar
- Select “Lucida Console” and OK.
- Write
Chcp 10000at the prompt - Finally
dir /b
Enjoy your clean UTF-16 output with hearts, Chinese signs, and much more!
What encoding/code page is cmd.exe using?
Yes, it’s frustrating—sometimes type and other programs
print gibberish, and sometimes they do not.
First of all, Unicode characters will only display if the
current console font contains the characters. So use
a TrueType font like Lucida Console instead of the default Raster Font.
But if the console font doesn’t contain the character you’re trying to display,
you’ll see question marks instead of gibberish. When you get gibberish,
there’s more going on than just font settings.
When programs use standard C-library I/O functions like printf, the
program’s output encoding must match the console’s output encoding, or
you will get gibberish. chcp shows and sets the current codepage. All
output using standard C-library I/O functions is treated as if it is in the
codepage displayed by chcp.
Matching the program’s output encoding with the console’s output encoding
can be accomplished in two different ways:
However, programs that use Win32 APIs can write UTF-16LE strings directly
to the console with
WriteConsoleW.
This is the only way to get correct output without setting codepages. And
even when using that function, if a string is not in the UTF-16LE encoding
to begin with, a Win32 program must pass the correct codepage to
MultiByteToWideChar.
Also, WriteConsoleW will not work if the program’s output is redirected;
more fiddling is needed in that case.
type works some of the time because it checks the start of each file for
a UTF-16LE Byte Order Mark
(BOM), i.e. the bytes 0xFF 0xFE.
If it finds such a
mark, it displays the Unicode characters in the file using WriteConsoleW
regardless of the current codepage. But when typeing any file without a
UTF-16LE BOM, or for using non-ASCII characters with any command
that doesn’t call WriteConsoleW—you will need to set the
console codepage and program output encoding to match each other.
How can we find this out?
Here’s a test file containing Unicode characters:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好Here’s a Java program to print out the test file in a bunch of different
Unicode encodings. It could be in any programming language; it only prints
ASCII characters or encoded bytes to stdout.
import java.io.*;
public class Foo { private static final String BOM = "ufeff"; private static final String TEST_STRING = "ASCII abcde xyzn" "German äöü ÄÖÜ ßn" "Polish ąęźżńłn" "Russian абвгдеж эюяn" "CJK 你好n"; public static void main(String[] args) throws Exception { String[] encodings = new String[] { "UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" }; for (String encoding: encodings) { System.out.println("== " encoding); for (boolean writeBom: new Boolean[] {false, true}) { System.out.println(writeBom ? "= bom" : "= no bom"); String output = (writeBom ? BOM : "") TEST_STRING; byte[] bytes = output.getBytes(encoding); System.out.write(bytes); FileOutputStream out = new FileOutputStream("uc-test-" encoding (writeBom ? "-bom.txt" : "-nobom.txt")); out.write(bytes); out.close(); } } }
}The output in the default codepage? Total garbage!
Z:andrewprojectssx1259084>chcp
Active code page: 850
Z:andrewprojectssx1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y = bom
■A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y == UTF-16BE
= no bom A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
= bom
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y = bom
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y == UTF-32BE
= no bom A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
= bom ■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}However, what if we type the files that got saved? They contain the exact
same bytes that were printed to the console.
Z:andrewprojectssx1259084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
uc-test-UTF-16BE-nobom.txt A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣☺↓☺z☺|☺D☺B R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y
uc-test-UTF-32BE-bom.txt ■ A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
uc-test-UTF-32BE-nobom.txt A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N ♦O C J K O` Y}
uc-test-UTF-32LE-bom.txt A S C I I a b c d e x y z G e r m a n ä ö ü Ä Ö Ü ß P o l i s h ą ę ź ż ń ł R u s s i a n а б в г д е ж э ю я C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺ R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦ C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢The only thing that works is UTF-16LE file, with a BOM, printed to the
console via type.
If we use anything other than type to print the file, we get garbage:
Z:andrewprojectssx1259084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z G e r m a n õ ÷ ³ ─ Í ▄ ▀ P o l i s h ♣☺↓☺z☺|☺D☺B☺ R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦ C J K `O}Y 1 file(s) copied.From the fact that copy CON does not display Unicode correctly, we can
conclude that the type command has logic to detect a UTF-16LE BOM at the
start of the file, and use special Windows APIs to print it.
We can see this by opening cmd.exe in a debugger when it goes to type
out a file:

After type opens a file, it checks for a BOM of 0xFEFF—i.e., the bytes
0xFF 0xFE in little-endian—and if there is such a BOM, type sets an
internal fOutputUnicode flag. This flag is checked later to decide
whether to call WriteConsoleW.
But that’s the only way to get type to output Unicode, and only for files
that have BOMs and are in UTF-16LE. For all other files, and for programs
that don’t have special code to handle console output, your files will be
interpreted according to the current codepage, and will likely show up as
gibberish.
You can emulate how type outputs Unicode to the console in your own programs like so:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest = "ASCII abcde xyzn" "German äöü ÄÖÜ ßn" "Polish ąęźżńłn" "Russian абвгдеж эюяn" "CJK 你好n";
int main() { int n; wchar_t buf[1024]; HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE); n = MultiByteToWideChar(CP_UTF8, 0, lpcsTest, strlen(lpcsTest), buf, sizeof(buf)); WriteConsole(hConsole, buf, n, &n, NULL); return 0;
}This program works for printing Unicode on the Windows console using the
default codepage.
For the sample Java program, we can get a little bit of correct output by
setting the codepage manually, though the output gets messed up in weird ways:
Z:andrewprojectssx1259084>chcp 65001
Active code page: 65001
Z:andrewprojectssx1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好 你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好 你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…However, a C program that sets a Unicode UTF-8 codepage:
#include <stdio.h>
#include <windows.h>
int main() { int c, n; UINT oldCodePage; char buf[1024]; oldCodePage = GetConsoleOutputCP(); if (!SetConsoleOutputCP(65001)) { printf("errorn"); } freopen("uc-test-UTF-8-nobom.txt", "rb", stdin); n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin); fwrite(buf, sizeof(buf[0]), n, stdout); SetConsoleOutputCP(oldCodePage); return 0;
}does have correct output:
Z:andrewprojectssx1259084>.test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好The moral of the story?
typecan print UTF-16LE files with a BOM regardless of your current codepage- Win32 programs can be programmed to output Unicode to the console, using
WriteConsoleW. - Other programs which set the codepage and adjust their output encoding accordingly can print Unicode on the console regardless of what the codepage was when the program started
- For everything else you will have to mess around with
chcp, and will probably still get weird output.
Исправляем проблему с кодировкой с помощью смены кодировки
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe.
Узнать текущую кодировку можно введя в командной строке команду chcp, после ввода данной команды необходимо нажать Enter.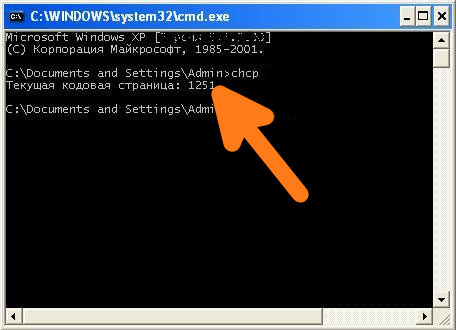
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp <код_новой_кодировки>, где <код_новой_кодировки> – это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 – Windows-кодировка (Кириллица);
- 866 – DOS-кодировка;
- 65001 – Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
chcp 866Для смены кодировки на UTF-8, команда примет следующий вид:
chcp 65001Для смены кодировки на Windows-1251, команда примет следующий вид:
chcp 1251Исправляем проблему с кодировкой с помощью смены шрифта
Первым делом нужно зайти в свойства окна: Правой кнопкой щелкнуть по верхней части окна -> Свойства -> в открывшемся окне в поле Шрифт выбрать Lucida Console и нажать кнопку ОК.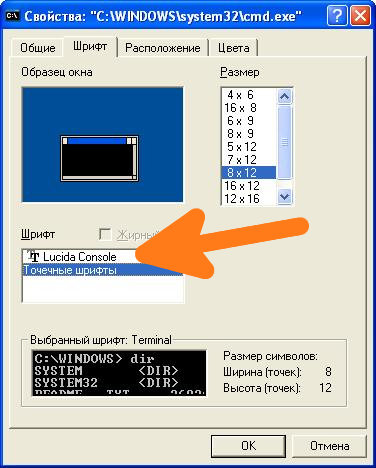
После этого не читаемые символы должны исчезнуть, а текст должен выводиться на русском языке.
Кодировки в windows
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет!!! Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:

А тут было написано:
echo Я абракадабра, написанная автором.Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
assoc .bat = .mp4Первый способ устранения проблемы, это
Notepad
. Для этого Вам нужно открыть Ваш батник таким способом:

Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:

Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программ
Нередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad , но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
del C:Program Data
echo Mne pofig
pauseВторой способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C ).
#include <iostream>
#include <windows.h>
int main() {
SetConsoleCP(номер_кодировки);
SetConsoleOutputCP(номер_кодировки);
}Если же не сработает:
#include <math.h> //Не забываем про библиотеку Math.
char bufRus[256];
char* Rus(const char* text) { CharToOem(text, bufRus); return bufRus }
int main { cout << "Тут пишите, что угодно!" << endl; system("pause") return 0
}3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
chcp 1251 >nul
for /f "delims=" %%A in ("Мой текст") do >nul chcp 866& echo.%%AТеперь у Нас будет нормальный вывод в консоль. На других языках (С ):
SetConsoleOutputCP(1251)
//А тут добавляете тот цикл, который был в батнике4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
Установить Windows 10. Там кодировка консоли специально подходит для языка страны, и Вам больше не нужно будет беспокоиться об этой проблеме. Но у Вас появится ещё 6 проблем, и вернуться к предыдущей лицензионной версии Windows Вы не сможете.



