
Findstr – поиск текста в файле с использованием регулярных выражений.
Команда FINDSTR используется для поиска текстовой строки в одном или нескольких файлах с использованием регулярных выражений. По сравнению с командой FIND данная команда позволяет выполнять значительно более гибкий поиск в соответствии с правилами, задаваемыми в качестве параметров командной строки.
Регулярные выражения ( regular expressions ) – это своеобразный язык с применением обычных и специальных символов, задающих шаблон и алгоритм поиска. Обычные символы ( литералы ) – это привычные текстовые знаки – буквы, цифры, знаки препинания и т. п. Специальные символы ( метасимволы ) – это элементы записи правил и параметров обработки для обычных символов. Так, например, символ точка . означает “Любой символ”, квадратные скобки – набор из заключенных в них символов, последовательность d – любой цифровой символ, D – любой не цифровой символ.
При необходимости обработки метасимволов как обычных элементов текста, в регулярных выражениях используется экранирующий символ – обратная косая черта . Запись [ означает обычный символ раскрывающейся квадратной скобки, а не метасимвол для начала набора. Для экранирования нескольких метасимволов используется последовательность :
Q . . . набор метасимволов . . .E
Обратная косая черта перед обычным символом означает, что он интерпретируется как служебный символ:
s – соответствует символу пробела.
При использовании в регулярных выражениях, строчные и заглавные символы различаются.
S – любой символ, не пробел.
Формат командной строки FINDSTR:
FINDSTR [/B] [/E] [/L] [/R] [/S] [/I] [/X] [/V] [/N] [/M] [/O] [/P] [/F:файл] [/C:строка] [/G:файл] [/D:список_папок] [/A:цвета] [/OFF[LINE]] строки [[диск:][путь]имя_файла[ …]]
/B – Искать образец только в началах строк.
/E – Искать образец только в конце строк.
/L – Поиск строк дословно.
/R – Поиск строк как регулярных выражений.
/S – Поиск файлов в текущей папке и всех ее подпапках.
/I – Определяет, что поиск будет вестись без учета регистра.
/X – Печатает строки, которые совпадают точно.
/V – Печатает строки, не содержащие совпадений с искомыми.
/N – Печатает номер строки, в которой найдено совпадение, и ее содержимое.
/M – Печатает только имя файла, в которой найдено совпадение.
/O – Печатает найденный строки через пустую строку.
/P – Пропускает строки, содержащие непечатаемые символы.
/OFF[LINE] – Не пропускает файлы с установленным атрибутом “Автономный”.
/A:цвета – Две шестнадцатеричные цифры – атрибуты цвета. См. “COLOR /?”
/F:файл – Читает список файлов из заданного файла (/ для консоли).
/C:строка – Использует заданную строку как искомую фразу поиска.
/G:файл – Получение строк из заданного файла (/ для консоли).
/D:список_папок – Поиск в списке папок (разделяются точкой с запятой).
строка – Искомый текст.
[диск:][путь]имя_файла – Задает имя файла или файлов.
Для разделения нескольких искомых строк, если аргумент не
имеет префикса /C, используется пробел. Например,
FINDSTR “Привет мир” file.txt поиск “Привет” или “мир” в файле file.txt
FINDSTR /C:”Привет мир” file.txt поиск строки “Привет мир” в файле file.txt.
Краткую справку по использованию команды FINDSTR можно получить при использовании ключа /?:
FINDSTR /?
Кроме параметров командной строки, справка дополнена краткой сводкой по синтаксису регулярных выражений:
. – Любой символ.
* – Повтор: ноль или более вхождений предыдущего символа или класса
^ – Позиция в строке: начало строки
$ – Позиция в строке: конец строки
[класс] – Класс символов: любой единичный символ из множества
[^класс] – Обратный класс символов: любой единичный символ из дополнения
[x-y] – Диапазон: любые символы из указанного диапазона
x – Служебный символ: символьное обозначение служебного символа x
< xyz – Позиция в слове: в начале слова
xyz > – Позиция в слове: в конце слова
За полной информацией о регулярных выражениях FINDSTR обратитесь к доступной
интерактивной документации.
Примеры использования FINDSTR:
findstr /M [0-9] %temp%*.* – отобразить список файлов ( ключ /M ), в которых содержатся цифры ( набор 0-9 ) из каталога временных файлов ( определяется %TEMP% )
findstr /P /I “Error” %temp%*.* – Отобразить строки, содержащие слово Error . Поиск строк выполнять без учета регистра символов ( ключ /I ), строки, содержащие непечатаемые символы, не отображать ( ключ /P ) .
findstr /M /I /C:”network error” %windir%system32*.exe – отобразить список исполняемых файлов из системного каталога Windowssystem32, в которых встречается строка “network error “
findstr /s /I /A:f4 /O /C:”failed” C:*.log – отобразить строки файлов с расширением log, содержащие слово failed. Имя файла и смещение строки относительно его начала отображать красными символами на белом фоне ( ключ /A:F4 ). Поиск выполняется во всех файлах .log корневого каталога диска C: и всех его подкаталогов ( ключ /S )
findstr /A:FC /N /s /i “< comput.*” *.* – отобразить строки, содержащие слово, начинающееся с ” comput” ( compute, computer, computers и т. д. ), а также имена файлов и номера строк ( ключ /N ).
findstr /A:FC /N /s /i “< правильн.*” *.* – как и в предыдущем случае, но ищется строка, содержащая слово, начинающееся с подстроки правильн. При использовании символов русского языка нужно учитывать их кодировку, поскольку коды символов в DOS- и Windows – кодировке различаются. В командных файлах, когда необходимо выполнять поиск строк, содержащих символы национального алфавита, шаблон для поиска должен быть представлен в той же кодировке, что и содержимое файла. Можно использовать переключение кодовой страницы перед поиском:
REM переключаемся на Windows – кодировку
chcp 1251
REM Выполняем поиск
findstr /A:FC /N /s /i “< правильн.*” *.*
REM Переключаемся на DOS – кодировку
chcp 866
REM Выполняем поиск
findstr /A:FC /N /s /i “< правильн.*” *.*
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки
AA[A
|..
]A[A
|-1..
]A[
1..
]
. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой
для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка
«ababcaba»
. Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях).
Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.Использовать эти наблюдения предлагается следующим образом.
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены все позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).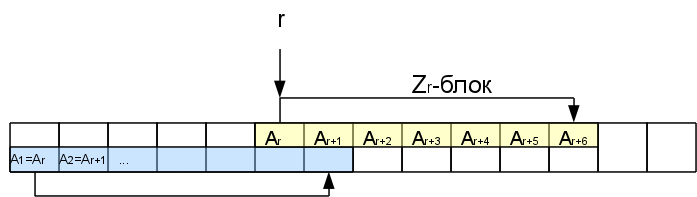
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.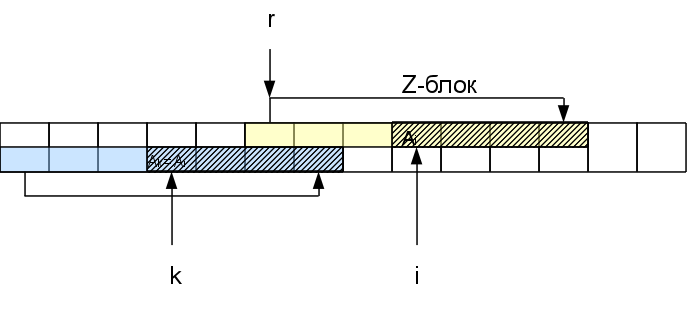
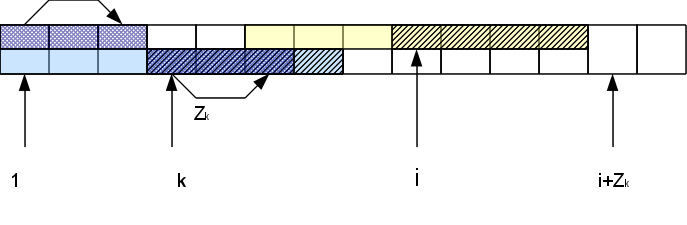
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r 1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk h. В результате у нас может появиться новый самый правый Z-блок (если h>0).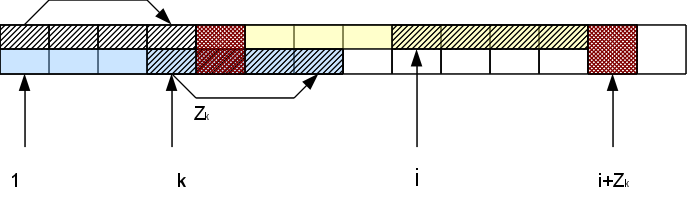
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A| |X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A| |X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{ const size_t len = str.size(); Z.clear(); Z.resize(len); if (0 == len) return; Z[0] = len; for (size_t curr = 1, left = 0, right = 1; curr < len; curr) { if (curr >= right) { size_t off = 0; while ( curr off < len && str[curr off] == str[off] ) off; Z[curr] = off; right = curr Z[curr]; left = curr; } else { const size_t equiv = curr - left; if (Z[equiv] < right - curr) Z[curr] = Z[equiv]; else { size_t off = 0; while ( right off < len && str[right - curr off] == str[right off] ) off; Z[curr] = right - curr off; right = off; left = curr; } } }
}А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Алгоритм кнута-морриса-пратта (кмп)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции —
(КМП). Введем понятие
. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место 🙂
«ababcaba»
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку.
Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения.
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.
Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i 1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi 1..i]. Если символ A[Pi 1] совпадет с A[i 1], то можем спокойно записать, что Pi 1=Pi 1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi 1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi 1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i 1-ый символ — ситуация будет идентичной.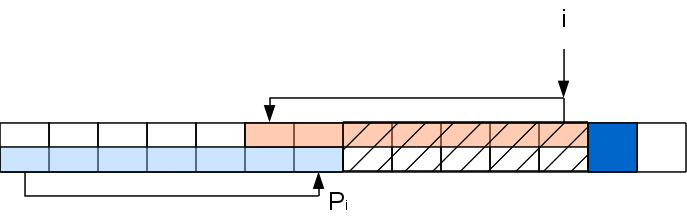
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i 1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi 1] совпадет с A[i 1], то Pi 1=PPi 1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.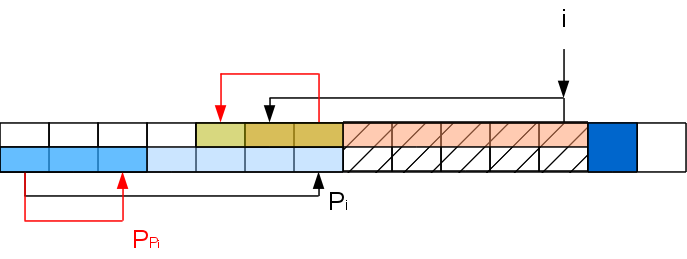
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i 1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{ const size_t str_length = str.size(); prefix_func.clear(); prefix_func.resize(str_length); if (0 == str_length) return; prefix_func[0] = 0; for (size_t current = 1; current < str_length; current) { size_t matched_prefix = current - 1; size_t candidate = prefix_func[matched_prefix]; while (candidate != 0 && str[current] != str[candidate]) { matched_prefix = prefix_func[matched_prefix] - 1; candidate = prefix_func[matched_prefix]; } if (candidate == 0) prefix_func[current] = str[current] == str[0] ? 1 : 0; else prefix_func[current] = candidate 1; }
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил
. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|
X
| |
A
|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|
X1
| |
X2
| … |
Xn
| n|
A
|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|
X1
| |
X2
| … |
Xn
| |
A
|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
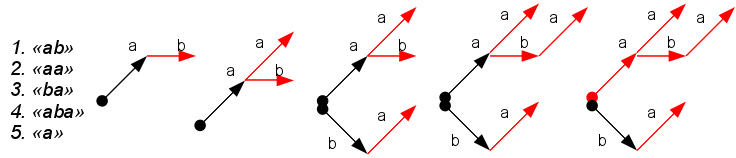
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов.
. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений).
На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом
или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много.
X1
| |
X2
| … |
Xn
| n|
A
|) получить O(|
X1
| |
X2
| … |
Xn
| |
A
|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|
A2
) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде —
, причем сделать это за O(|
A
|). Недавно на Хабре была по этому поводу
, так что интересующиеся могут прочитать про
там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен
. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|
X
| log|
A
|) если подумать и сделать все аккуратно, и O(|
X
|log|
A
|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|
X
|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка
Aтекст
). Необходимо проверить, есть ли в ней подстрока
Xобразец
), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если
X
не длинее
A
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое
строка
все, наверное, понимают — это последовательность символов, возможно пустая.
Символы
, или буквы, принадлежат некоторому множеству, которое называют
алфавитом
(данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании).
Длина строкиA
| — это, очевидно, количество символов в ней.
Префикс строкиA[
..i
]
— это строка из i первых символов строки
AСуффикс строкиA[
j..
]
— это строка из |
A
|-j 1 последних символов. Подстроку из
A
будем обозначать как
A[
i..j
]
, а
A[]
— i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как
сентинел
— некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке
A
и искать в ней вхождение первого символа искомой строки
X
. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки
A
. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из
X
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки
A
с текущей позиции. Почему это не так легко продемонстрировать на примере поиска
X«AAAB»A«AAAAB»
. Первая гипотеза нас приведет к четвертому символу
A“AAAAB”
, где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в
A
проверили около |
X
| раз. То есть вычислительная сложность сложность алгоритма O(|
XA
|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.



