

Эвристический (или управляемый)
Эвристическое сканирование Binwalk — это попытка классифицировать зашифрованные или сжатые блоки данных с высокой энтропией. Хотя этот тип сканирования не на 100% точен.
Как правило, используемые сжатые данные или алгоритмы слабого шифрования будут иметь общее высокоэнтропийное шифрование, но будут небольшие блоки с низкоэнтропийными данными. Данные, которые были зашифрованы с помощью сильного алгоритма энтропии, не будут содержать эти небольшие фрагменты данных с низкой энтропией:
Обратите внимание, что для этого сканирования требуется два цикла (один для начального энтропийного анализа, а второй — более жесткий эвристический анализ), который занимает определенное время для завершения, особенно если целевой файл особенно поражен, это занимает больше времени.
Использование BufferedInputStream
Описанный выше подход не рекомендуется для больших файлов, так как он может исчерпать память кучи. Если файлы большие, вместо того, чтобы читать все файлы в массивы, мы должны использовать и читать файлы по частям.
⮚ Читать посимвольно, используя BufferedReaderх read() метод
⮚ Читайте построчно, используя BufferedReaderх readLine() метод
Вот и все, что касается сравнения содержимого двух файлов для определения равенства в Java.
Спасибо за чтение.
Пожалуйста, используйте наш онлайн-компилятор размещать код в комментариях, используя C, C++, Java, Python, JavaScript, C#, PHP и многие другие популярные языки программирования.
Как мы? Порекомендуйте нас своим друзьям и помогите нам расти. Удачного кодирования 🙂
Функция сравнения
Binwalk может генерировать шестнадцатеричные дампы и различия одного или нескольких файлов. В файле один и тот же байт отображается зеленым, разница отображается красным, а синий указывает, что это только другая часть некоторых файлов.
Извлечь файлы вручную
Binwalk может извлечь данные и обнаружить, что правило извлечения, указанное в целевом файле, использует параметр –dd. Формат, используемый для извлечения указанных правил:
- тип — это строчная строка, описанная в подписи (поддерживаются регулярные выражения)
- расширение — это расширение файла, используемое при сохранении данных на диск
- команда — это необязательный оператор выполнения команды после сохранения данных на диск
По умолчанию, если подпись, указанная в альтернативном имени файла, не является неожиданной, имя файла находится с шестнадцатеричной подписью смещения.
В следующем примере показано, как использовать параметр -dd для извлечения подписи любого zip-файла, содержащего расширение файла архива zip-строки, а затем выполнить команду «unzip», чтобы указать правила извлечения. Можно указать несколько опций -dd:
Обратите внимание на использование заполнителей, таких как: «% e»: когда этот заполнитель будет заменен относительным путем извлеченного файла, команда будет выполнена.
Как получить
Нам понадобится ещё один файл заполненный пробелами:
” ” ( spaces.txt )
Он должен быть больше или равен по размеру файлу источнику ( source.txt )
Включить функцию плагина
Некоторые плагины по умолчанию отключены. Эта опция может использоваться, когда эти плагины включены — опция -enable-plugin
Отключить плагин
Некоторые плагины включены по умолчанию. Эти плагины могут быть отключены при использовании этой опции —diable-plugin option
Или, все плагины могут быть отключены, используйте эту опцию: –disable-plugins option:
Использование Arrays. equals() метод
В JDK мы можем просто считать файлы целиком в массивы байтов, а затем сравнить оба массива на равенство. Чтобы прочитать все байты из файла в массив байтов, мы можем использовать метод, а равенство байтовых массивов можно проверить с помощью , как показано ниже:
Как сравнить два файла, в чем у них различия (текст, Word/Excel-документы, Exe-файлы)

Приветствую всех читателей!
Сегодняшняя заметка будет относиться к офисной тематике. (а точнее: речь пойдет о сравнении нескольких документов между собой).
Представьте , у вас есть парочка документов, в которых частично различается текст (например, где-то уже исправленный, а где-то «старый», с ошибками. ). И теперь нужно найти между ними различия, принять их к сведению, и собрать из 2-х файлов один.
Можно, конечно, сориентироваться по дате — однако, далеко не всегда такой подход будет уместен. Но вот если бы какая-то программа нашла и выделила несовпадающие символы (строки). это было бы здорово! 👌
Собственно, о нескольких подобных примерах и пойдет речь в этой заметке.

О каких файлах идет речь
И так, начать заметку (я думаю) стоит с самых обычных текстовых файлов (коих большинство). Задача перед нами будет следующая : есть два почти одинаковых текстовых файла (в формате TXT), и нужно найти в них отличные строки и символы, и подсветить их (о чем я и сказал выше).
Для работы нам понадобится блокнот 👉 Notepad++ (ссылка на офиц. сайт) . Установка у программы стандартная (поэтому ее опускаю).
Далее делаем следующее:
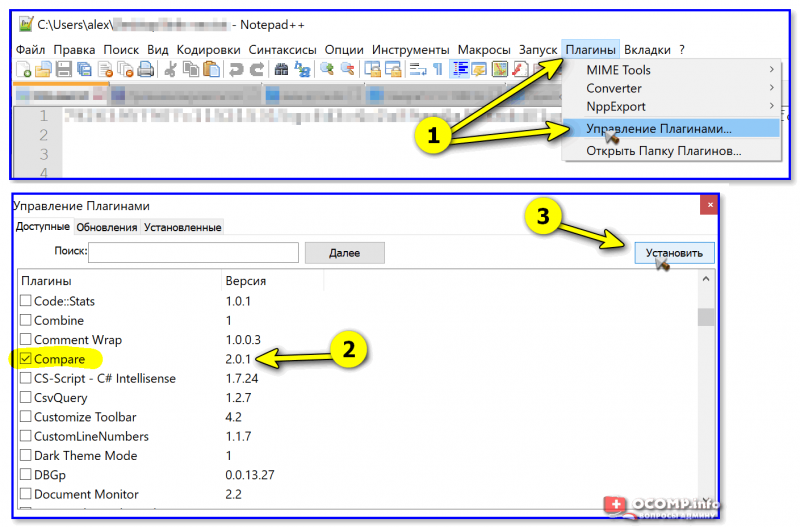
Устанавливаем плагин в Notepad++
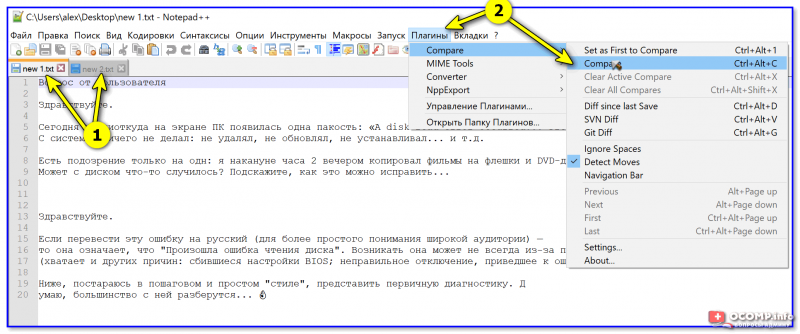
Открываем два нужных файла и жмем кнопку сравнения
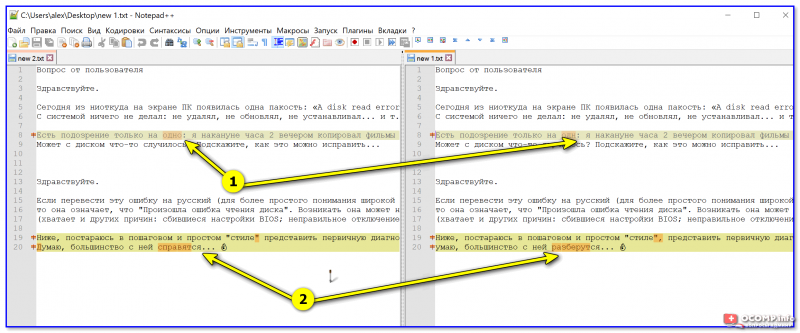
Места, где есть различия, были выделены! // Notepad++
Документы Word / Excel (+ текстовые в т
Начну с MS Word.
Программа универсальная и позволяет сравнивать как документы формата Docx, так и обычные текстовые файлы (TXT, RTF и пр. форматы).
Делается это так (на примере Word 2019):
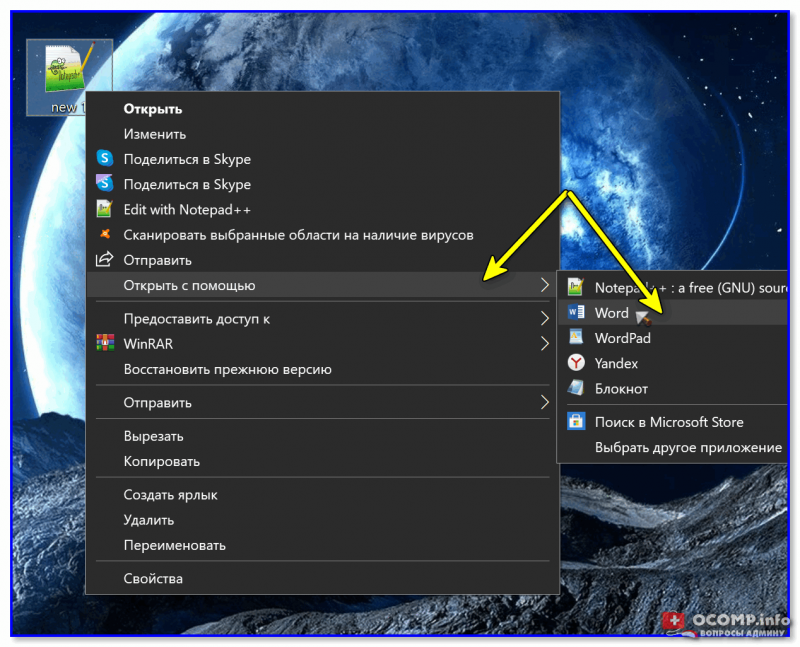
Открываем 2 файла в Word
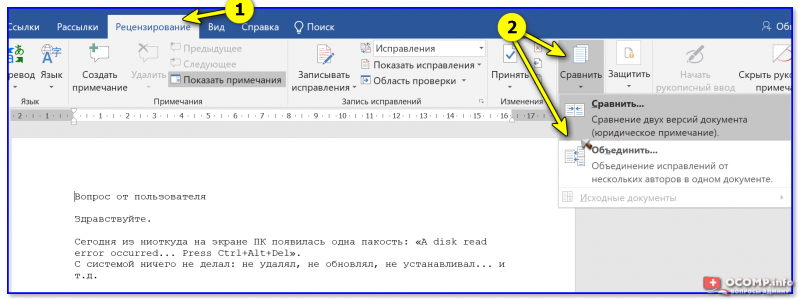
Рецензирование — Сравнить (Word 2019)
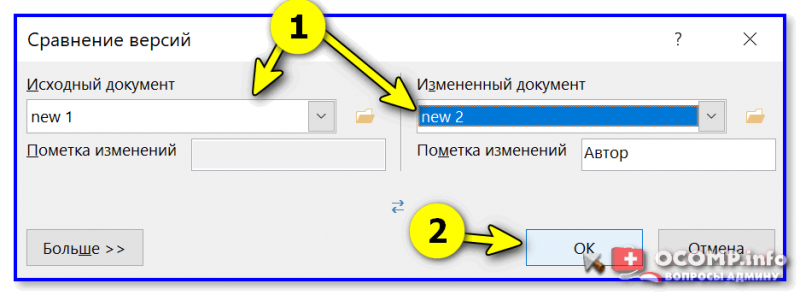
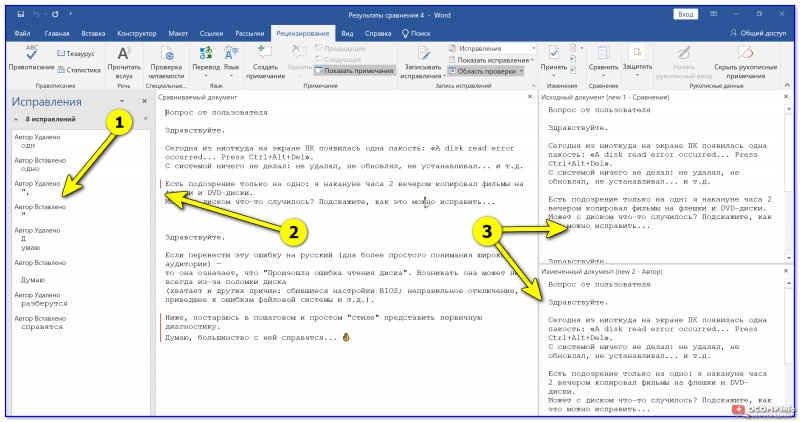
Что получается в итоге // Word подсчитал сколько было мест с исправлениями (в моем случае 8!).
👉 Что касается Excel
С одной стороны — в Excel есть десятки способов, как можно сравнить две таблички между собой, с другой — в зависимости от конкретной задачи в каждом случае нужно «всё подгонять» под себя (универсального способа на все случаи жизни — нет!). 👌
Ниже приведу лишь парочку наиболее простых вариантов (разумеется, есть много др. способов решения).
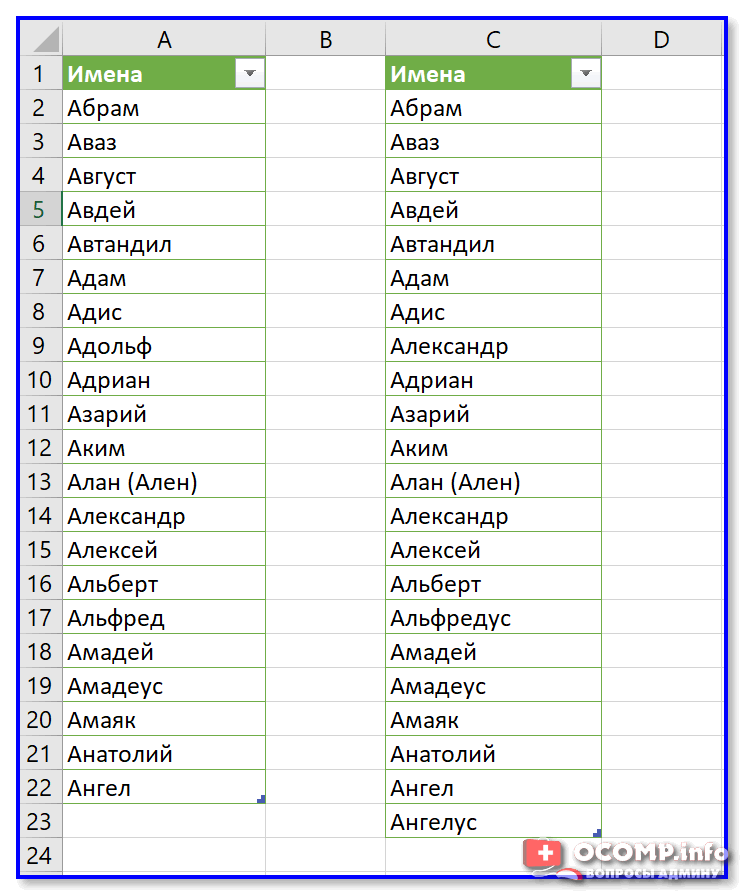
Пример двух табличек
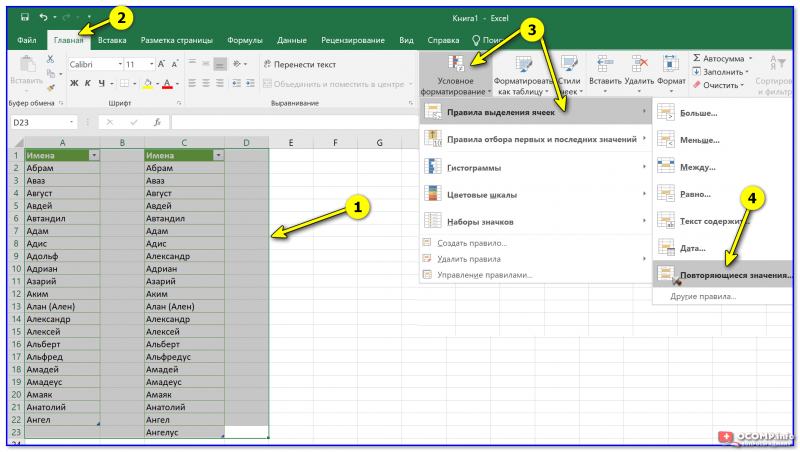
Выделяем таблицы, и вкл. повторяющиеся значения
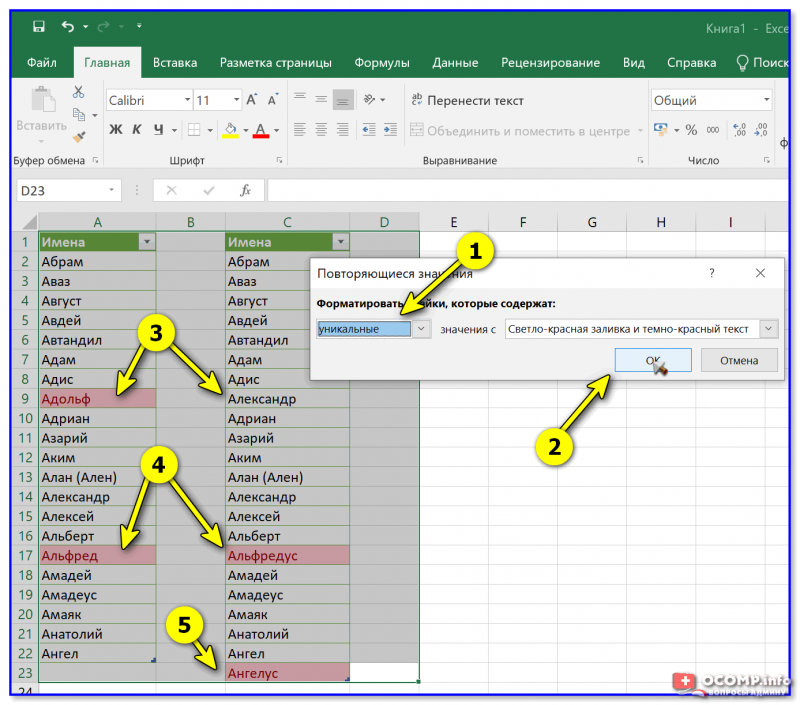
Все отличия были найдены!
В Excel есть одна довольно мощная функция ВПР — она позволяет сравнивать 2 таблицы и при нахождении чего-то «несовпадающего» — выполнять условие (скажем, подставить значение из одной таблицы в другую). О том, как с ней работать — показано в одной моей прошлой статье (парочка ссылок ниже).
1) Excel: как сравнить 2 таблицы с помощью функции ВПР — см. простейший пример.
2) Повторяющиеся значения в Excel: как удалить дубликаты / уникальные строки.
Бинарные файлы Exe, Com и пр. (возможно без расширения)
Тема очень специфичная, и я включил ее в заметку только для общей информации.
Сравнить два EXE-файла (или любых других, у которых нет расширения, и вы даже не знаете их тип данных) можно с помощью спец. редактора шестнадцатеричных, десятичных и бинарных файлов. Например, один из доступных для начинающих — это 👉 Hex Editor Neo (ссылка на сайт разработчика).
Как с ней работать : сначала необходимо запустить программу и открыть в ней оба файла (это стандартно, как и в др. софте). Далее перейти в раздел «Tools / File Comparison / Compare Files» . 👇
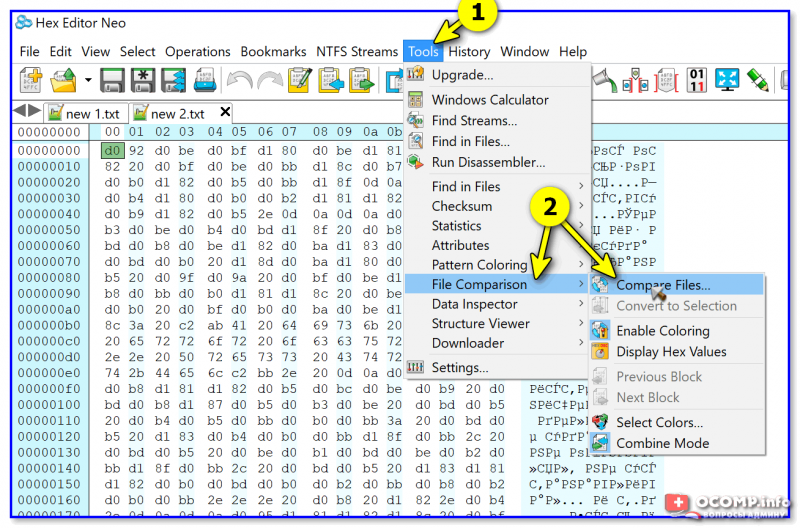
Hex Editor Neo — инструмент сравнения
В результате Hex Editor Neo автоматически разделит экран поровну на две части и подсветит несовпадающий код. 👇
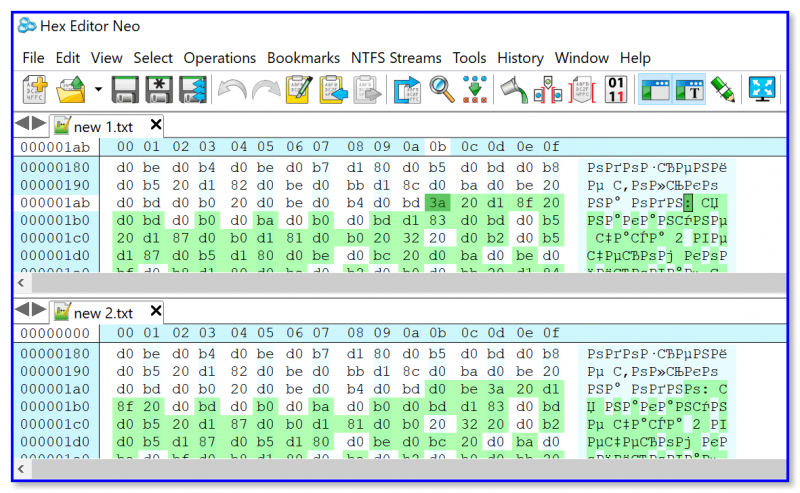
Разумеется, для дальнейшего редактирования и более-менее осмысленной работы — необходимы определенные знания / либо точно знать, какой кусок нужно удалить, поменять (можно, конечно, поэкспериментировать. но результаты могут быть самыми разными — от ошибок при запуске отредактированного файла, до «вылетов» синих экранов).
Картинки
Вообще, две картинки чаще всего сравнивают просто на «глазок», ставя их одну к одной. Впрочем, для этого можно использовать и спец. утилиты — например, те, которые используются для поиска дубликатов файлов. Я на страницах блога как-то упоминал о них, ссылка ниже в помощь.
Обратите внимание , программа Image Comparer 👇 автоматически выделят на картинках те области, к которым стоит присмотреться (либо есть различие, либо они не четкие и нельзя точно сказать наверняка. ).
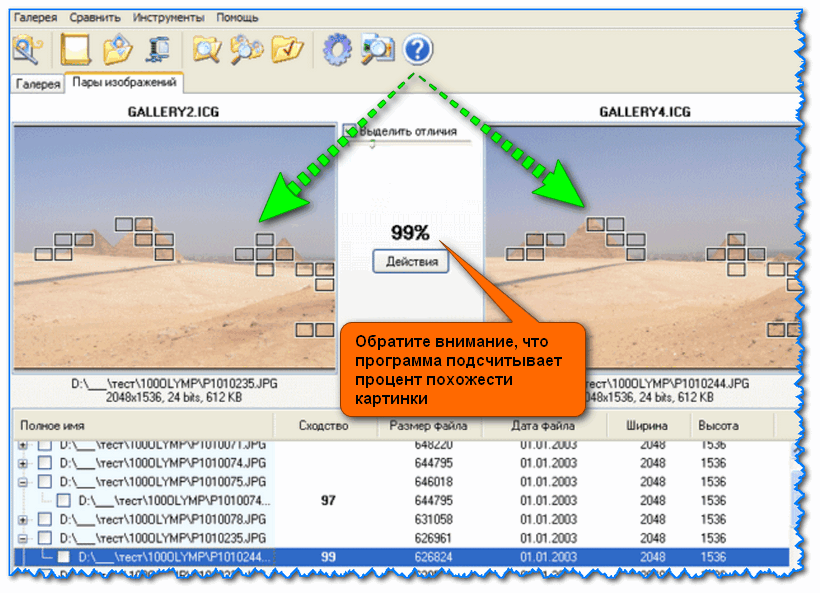
Image Comparer — скрин работы приложения (от разработчика)
Дополнения по теме (👇), разумеется, приветствуются!
Расширенные фильтры
Вы можете объединить две функции фильтров включения и исключения:
Пример: следующие результаты поиска включают результаты поиска из текста «файловая система» и исключают результаты строки jffs2.
Try diff -s
Short answer: run diff with the -s switch.
Long answer: read on below.
Here’s an example. Let’s start by creating two files with random binary contents:
$ dd if=/dev/random bs=1k count=1 of=test1.bin
1+0 records in
1+0 records out
1024 bytes (1,0 kB, 1,0 KiB) copied, 0,0100332 s, 102 kB/s
$ dd if=/dev/random bs=1k count=1 of=test2.bin
1+0 records in
1+0 records out
1024 bytes (1,0 kB, 1,0 KiB) copied, 0,0102889 s, 99,5 kB/s
Now let’s make a copy of the first file:
$ cp test1.bin copyoftest1.bin
Now test1.bin and test2.bin should be different:
$ diff test1.bin test2.bin
Binary files test1.bin and test2.bin differ
$ diff test1.bin copyoftest1.bin
But wait! Why is there no output?!?
The answer is: this is by design. There is no output on identical files.
But there are different error codes:
Now fortunately you don’t have to check error codes each and every time because you can just use the -s (or –report-identical-files) switch to make diff be more verbose:
$ diff -s test1.bin copyoftest1.bin
Files test1.bin and copyoftest1.bin are identical
Выбираем шестнадцатеричный редактор для анализа бинарников
После окончания цикла статьей «Лучшие инструменты пентестера» в редакцию пришло немало писем с просьбой сделать подборку hex-редакторов. Интерес, конечно, представляет не возможность редактировать бинарные данные, а дополнительные фичи вроде автоматического распознавания структур данных и дизассемблирования кода. Чтобы сделать обзор, мы выяснили мнения людей, которым чаще других приходится ковыряться с такими инструментами – вирусных аналитиков. И вот что они нам рассказали.
Любой hex-редактор позволяет исследовать и модифицировать файл на низком уровне, оперируя с битами и байтами. Содержание файла представляется в шестнадцатеричной форме. Это базовый функционал. Однако некоторые редакторы предлагают пользователям намного большее, позволяя разобраться, собственно, что есть что в том непонятном наборе символов, который появляется при открытия файла. Для этого автоматически извлекаются ASCII и Unicode строки, осуществляется поиск известных паттернов, выполняется распознавание основных структур данных и многое другое. Шестнадцатеричных редакторов довольно много, но если мы решили рассмотреть их в контексте исследования образцов малвари, то легко выделить некоторые из них. Лишь немногие оказываются реально полезными для анализа зловредного кода и исследования зараженных документов (скажем, PDF).
McAfee FileInsight
FileInsight – это бесплатный hex-редактор для Windows от компании McAfee Labs. Продукт, само собой, выполняет весь стандартный функционал, сопутствующий подобному софту, предлагая удобный интерфейс для просмотра и редактирования файлов в шестнадцатеричном и текстовом режимах. Но это лишь капля в море, если посмотреть на весь его функционал. Начать стоит с того, что FileInsight способен парсить структуру исполняемых бинарников для Windows (PE файлов), а также OLE-объектов Microsoft Office. Мало этого, пользователю предлагается встроенный x86 дизассемблер. Достаточно выбрать часть файла, которую хочешь просмотреть в виде читаемого кода, и FileInsight покажет этот фрагмент как листинг ассемблерных инструкций. Дизассемблер особенно полезен, когда ищешь шеллкод в зловредных файлах. Среди других опций, которые придутся по душе реверсерам – возможность импортировать объявления структур. Для этого программе достаточно указать заголовочный файл с объявлениями вроде:
В этом случае программа сама будет парсить подобные конструкции. Впрочем, и по умолчанию предлагается немало интуитивных алгоритмов для обработки кода. Речь, прежде всего, идет о декодировании многих методов обфускации (xor, add, shift, Base64 и т.д.) – встроенные скрипты щелкают подобную криптозащиту на раз-два. Тут надо заметить, что в качестве объекта исследования необязательно должен быть бинарник, это может быть и обычная веб-страница, вызывающая подозрения. Многие действия программа позволяет автоматизировать с помощью простых сценариев на JavaScript или модулей на Python, которых написано уже немало. Увы, при всех достоинствах, у FileInsight есть и серьезный недостаток, выражающийся в невозможности обрабатывать большие файлы. К примеру, если попытаешься скормить утилите файл размером в 400-500 Мб, вылетает ошибка «Failed to open document».
Существует две версии этого шестнадцатеричного редактора от компании HDD Software – простая бесплатная и продвинутая коммерческая версия. Freeware-вариант – это добротный, но мало чем примечательный HEX-редактор, имеющий классный настраиваемый интерфейс с поддержкой разных цветовых схем. Не более того. А вот профессиональная версия Hex Editor Neo предоставляет несколько полезных опций, которые могут быть крайне полезны при анализе бинарников. К примеру, пользователь получает возможность декодирования кода, закриптованного с помощью наиболее общих алгоритмов. Помимо этого появляется возможность просмотра и редактирования локальных ресурсов типа NTFS-потоков, локальных дисков, памяти процесса, а также оперативки. В самой полной версии появляется и поддержка скриптового языка, позволяющая автоматизировать многие процессы с помощью сценариев на VBScript и JavaScript. Но самый смак в том, что к твоим услугам предоставляется встроенный дизассемблер, который работает и с x86, и с x64, и с .NET-бинарниками! Еще одна фича – быстрое создание патчей, основанное на сравнении двух бинарников. Звучит впечатляюще, но лучше ли он, чем FileInsight? Скорее, нет. FileInsight в целом выглядит более функционально. С другой стороны, любая, даже бесплатная версия Hex Editor Neo отлично работает даже с очень большими файлами и позволяет искать ASCII и Unicode-строки. Дизассемблер здесь не ограничивается одной лишь x86 платформой, а встроенный редактор ресурсов очень удобен. Есть над чем подумать.
FlexHex
FlexHex – это мощный коммерческий hex-редактор от компании Heaventools Software, который включает многие из функций, доступных в Hex Editor Neo. Единственное, чего здесь нет – это, пожалуй, поддержка скриптов. Зато этот полнофункциональный редактор одинаково хорошо обрабатывает бинарники, OLE-файлы, физические диски и альтернативные NTFS-потоки. Последнее особенно важно, потому что FlexHex позволяет редактировать те данные, которые другие редакторы могут даже не увидеть. К тому же сразу чувствуется ориентированность на работу с большими массивами информации: какой бы размер ни был у файла, навигация по нему осуществляется без каких-либо лагов и тормозов. Для еще большего удобства работает система удобных закладок. При этом FlexHex непрерывно ведет историю всех операций – можно отменить любое действие, просто выбрав его из списка изменений (undo-list не ограничен)! В FlexHex поддерживаются все необходимые операции с бинарными данными, поиск ASCII и Unicode-строк. Если необходимо обрабатывать структуру с заранее известным форматом, задать ее параметры не составит труда с помощью специальных инструментов. В результате получаем отличный hex-редактор, но все-таки сильно уступающий тому же FileInsight. Единственная примечательная опция – это обработка OLE-файлов, но и тут есть проблемы. Несколько раз при попытке открыть зараженный OLE, программа вылетала с ошибкой «The docfile has been corrupted».
010 Editor – известный коммерческий продукт, разработанный SweetScape Software. Если сравнивать его с предыдущими тремя инструментами, то он умеет все: поддерживает работу с очень большими файлами, предоставляет классные возможности по оперированию с данными, позволяет редактировать локальные ресурсы, имеет систему скриптинга для автоматизации рутинных действий (более 140 различных функций к твоим услугам). А еще у 010 Editor есть изюминка, уникальная фишка. Редактор уделывает всех благодаря возможности парсить различные форматы файлов, используя собственную библиотеку шаблонов (так называемые Binary Templates). Вот здесь ему нет равных. Над шаблонами работают множество энтузиастов по всему миру, забивая различные структуры форматов и данных. В результате процесс навигации по различным форматам файлов становится прозрачным и понятным. Это касается в том числе и обработки бинарников для винды (PE файлам), файлов-ярлычков Windows (LNK), Zip-архивов, файлов Java-классов и многого другого. Всю прелесть этой фишки многие смогли осознать, когда известный специалист по безопасности Didier Stevens создал для 010 Editor шаблон для парсинга PDF-файлов. Вкупе с другими утилитами это серьезно упростило анализ зараженных PDF-документов, которые последние полгода не перестают удивлять количеством мест, откуда можно эксплуатировать программу-читалку. Добавляем сюда классный инструмент для сравнения бинарников, калькулятор с C-подобным синтаксисом, конвертирование данных между ASCII, EBCDIC, Unicode-форматами, и получаем очень привлекательный инструмент с уникальными фишками.
Hiew, в плане способа распространения, мало чем отличается от своих коллег – это тоже коммерческий продукт, который разработал наш соотечественник Евгений Сусликов. Имеющая долгую историю, программа сильно полюбилась многим специалистам по информационной безопасности. Тому есть вполне очевидные причины – мощные возможности для исследования и редактирования структуры и содержания исполняемых файлов как винды (PE), так и бинарников для Linux (ELF). Другая очень полезная фича для реверсинга – встроенный x86-64 ассемблер и дизассемблер. Последний даже поддерживает инструкции ARM. Не надо говорить, что редактор отлично переваривает большие файлы и позволяет редактировать логические и физические диски. Многие задачи легко автоматизируются за счет системы клавиатурных макросов, скриптов и даже API для разработки расширений (Hiew Extrenal Modules). Но прежде чем рваться в бой, учти – интерфейс Hiew представляет собой DOS-подобное окно, работать с которым с непривычки довольно неудобно. Зато можешь прочувствовать на себе всю прелесть олдскула.
Radare
Radare – это набор бесплатных утилит для Unix-платформы, которые предоставляют классные возможности для редактирования файлов в HEX-режиме. В него входит непосредственно сам hex-редактор (radare) с возможностью открытия локальных и удаленных файлов. Программа анализирует исполняемые файлы различных форматов, как линуксовых (ELF), так и виндовых (PE). Помимо редактирования в пакете Radare есть инструмент для сравнения бинарных файлов (radiff) и встроенный ассемблер/дизассемблер. А лично мне пару раз пригодился инструмент для генерации шеллкодов (rasc). Любые операции легко можно автоматизировать и подогнать под себя за счет скриптовой системы. Из минусов, опять же, можно отметить отсутствие GUI-интерфейса – все действия осуществляются из командной строки, а полноценно работать с утилитами получится, только прочитав документацию. С другой стороны на сайте есть наглядные скринкасты, демонстрирующие как основные моменты, так и маленькие секреты (вроде подключения Python-плагина).
Так что же выбрать?
Мы рассмотрели несколько мощных hex-редакторов, которые включают в себя полезные опции для анализа подозрительных файлов. Из всех продуктов серьезно выделяется FileInsight, который при всем своем функционале (а он действительно впечатляет) остается бесплатным. 010 Editor предоставляет большое количество шаблонов для обработки самых разных файлов, в том числе PDF-документов. Это мега-фишка, которой нельзя пренебрегать. Эти два редактора я использую постоянно; для работы аналитика, пожалуй, они подходят лучше всего. Если говорить о работе под Unix-платформой, то, конечно, нельзя забывать о Radare. Пакет предлагает очень мощные возможности, хотя и сложен в использовании из-за того, что работает из командной строки. Не очень дружелюбен и Hiew, хотя его возможности, безусловно, позволяют выполнять самые разные операции с бинарниками. К тому же, Hiew – это выбор большого количество настоящих профи, а это дорогого стоит (и многое значит). Что касается Hex Editor Neo, то его стоит взять на вооружение, если тебя интересует возможность дизассемблировать x86, x64 и .NET код.
Рекурсивное извлечение
Во многих случаях извлеченные данные могут потребовать дальнейшего анализа. Чтобы помочь с автоматизацией, binwalk может рекурсивно сканировать извлеченные данные и использовать опции -M и -e с файлами, указанными внешними средствами распаковки или извлечения:
Обратите внимание, что опция -M будет рекурсивно извлекать 8 слоев извлеченных файлов и игнорировать внешний инструмент извлечения для создания любого каталога.
Использование Apache Commons IO
Этот метод проверяет наличие обоих файлов, проверяет, что оба файла являются обычными файлами, а не каталогом, сравнивает длину обоих файлов или указывают ли они на один и тот же файл, прежде чем прибегать к побайтовому сравнению содержание.
Включая фильтры
Опция -y включает только результаты сопоставления указанного поискового текста. Строка поиска (текст) должна быть в нижнем регистре, включая регулярные выражения, и можно указать несколько опций -Y. Следующие результаты поиска включают только результаты поиска из текста «Файловая система». (То есть, если используется опция Y файловой системы, результат содержит только текстовые символы)
Сравнение файлов
Файлы в Total Commander сравниваются по строкам. Для сравнения:
- Выделяем оба файла;
- Идем в меню Файл — Сравнение по содержимому.
Результат: строки, в которых найдены отличия подсвечиваются серым цветом, а различия в них красным. Внизу общее количество найденных различий, переход между которыми осуществляется посредством кнопок «Следующее отличие» и «Предыдущее отличие». Можно использовать поиск по тексту. Также, можно перенести выбранные отличия в другой файл. Чтобы это сделать активируйте режим редактирования кнопкой «Редактировать».
Как с помощью командной строки сравнить два текстовых или бинарных файла
Б ывают случаи, когда у пользователей возникает необходимость проверить два файла на идентичность. Чаще всего с подобной задачей сталкиваются начинающие веб-разработчики и программисты. Отыскивать несоответствия в одинаковых с виду файлах приходится редакторам, корректорам и прочим специалистам, работающим с текстовыми данными.
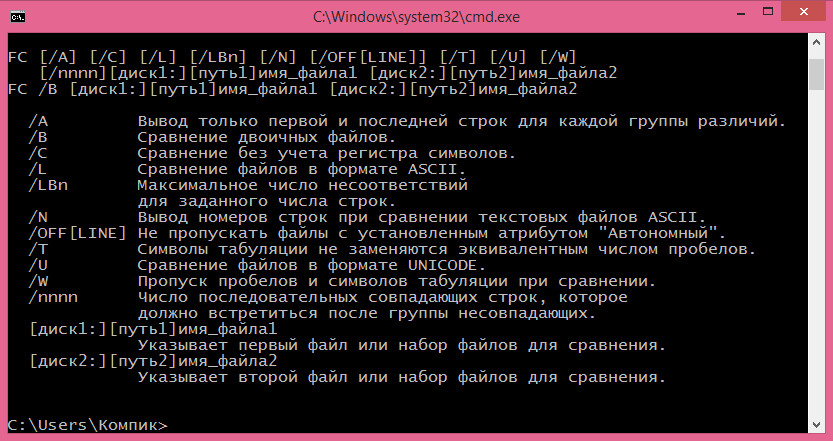
По идее для этих целей лучше всего использовать специальные утилиты, например WinMerge, но файлы также можно сравнивать с помощью самой обыкновенной командной строки . В командной оболочке всех версий Windows имеется замечательная команда FC. Она позволяет сравнивать между собой любые файлы, причём как текстовые, так и бинарные. Синтаксис этой команды очень прост и выглядит он следующим образом:
Список доступных ключей можно просмотреть, набрав и выполнив в консоли CMD команду FC /? . Справка даётся на русском языке, так что вы без труда разберетесь, что к чему.
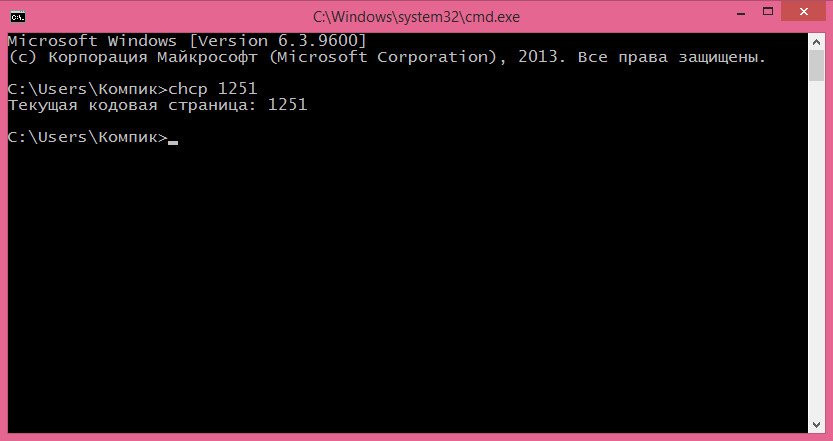
А теперь немного практики. Допустим, у вас есть два файла с кодом PHP и в одном из них предположительно имеются некие различия. Скрипты PHP это обычные текстовые файлы , поэтому в данном случае будем использовать ключ L предназначенный для сравнения текстовых документов в кодировке ASCII. Если скрипт содержит кириллицу, не забудьте перед выполнением команды сравнения выставить в консоли кодировку 1251, иначе на выходе вы получите крякозябры. Смена кодировки выполняется командой chcp 1251 .
Затем сравниваем файлы:
FC /L D:/1.php D:/2.php
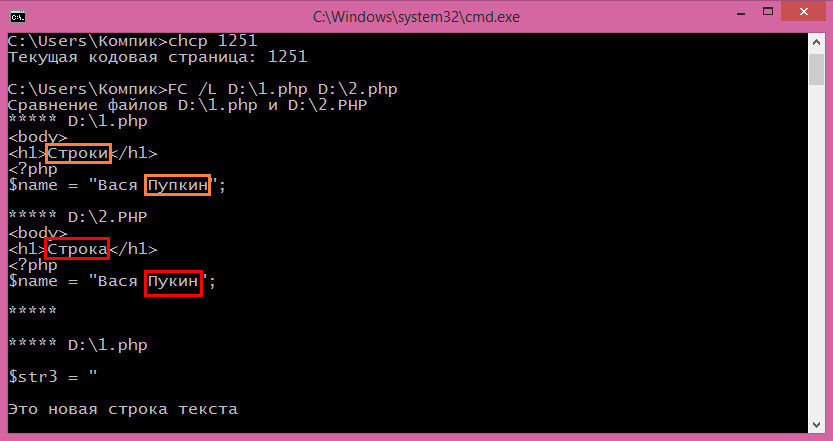
Различия между файлами выводятся в следующем порядке. Сначала идёт имя первого файла, затем строка, в которой было найдено несовпадение. За ним идёт имя второго файла и точно также указывается различающаяся строка. Если программа находит ещё несколько несоответствий в других строках, всё повторяется. В общей сложности утилита может обнаружить до 100 различий, такое ограничение имеет используемый командой fc внутренний буфер.
При поиске несоответствий в бинарных файлах используется ключ B. При этом сравнение производится побайтово. В принципе, таким способом можно сравнивать любые файлы, ведь все они по сути двоичны, просто при работе с текстовыми форматами FC может ограничиться информацией какой из сравниваемых объектов длиннее и на этом завершить свою работу.
FC /B D:/1.exe D:/2.exe
В данном примере сравниваются два исполняемых файла. Результат такого сравнения будет выглядеть примерно следующим образом:
00000040: 56 BA 00000050: 65 68 00000060: 43 72 00000070: 6U 0A
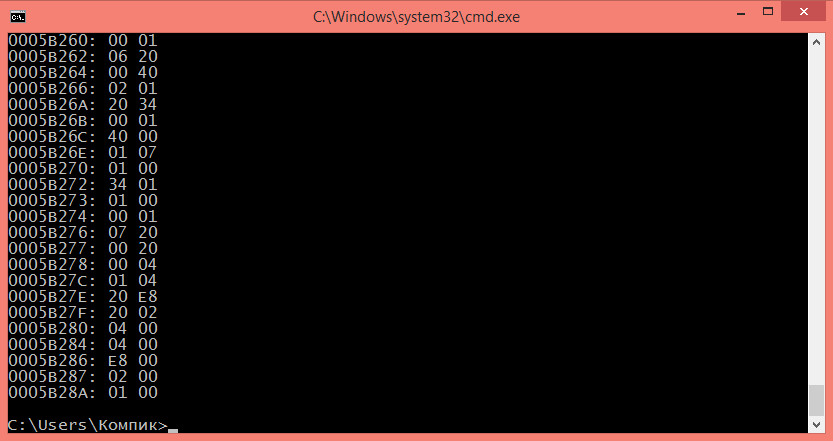
Если вы раньше никогда не имели дела с шестнадцатеричными редакторами, разобраться со всем этим нагромождением символов будет непросто. В общем так, каждая выведенная в консоли строка это найденное различие. Символы до двоеточия указывают на смещение от начала файла, первое двухзначное число это соответствующий смещению байт в первом файле, второе двухзначное число — соответствующий смещению байт во втором файле.
Какими ещё полезными возможностями обладает команда FC? Ну, например поддержкой подстановочных знаков. Если вам нужно сравнить некий файл etalon.exe с другими исполняемыми файлами в текущем каталоге, используйте команду следующего формата:
fc *.exe etalon.exe
Также с помощью подстановочных знаков можно производить пакетное сравнение файлов, расположенных в разных каталогах или разделах жёсткого диска. А что будет, если сравниваемые файлы окажутся полностью идентичными? Утилита выведет лаконичное сообщение — FC:различия не найдены.
Автоматическое (автоматическое) извлечение
Опцию -e можно использовать для автоматического извлечения данных на основе файла по умолчанию extract.conf, указанного в правилах извлечения:
Опция извлечения работает так же, за исключением того, что вы должны указать путь к файлу пользовательского правила извлечения:
Функция обновления
Через волшебные файлы и файлы конфигурации, а также используйте опцию -u binwalk для простого обновления до последней версии (для обновления требуется разрешение root)
Если вы используете функцию http proxy, установите http_proxy в переменной окружения.
Энтропийный анализ
Binwalk может выполнить энтропийный анализ целевого файла, чтобы сгенерировать исходные данные энтропии и / или данные кривой, представленные продуктом:
Анализ сигнатур или строк и энтропийный анализ могут быть объединены. Например, следующая команда будет сканировать целевой файл, исполняемый код и результат сканирования, наложенный на график энтропии:
Сравнение папок
Чтобы сравнить и унифицировать папки и подкаталоги в Total Comander, понадобиться проделать следующий путь:
- Выбираем с одной и другой стороны папки которые будем сравнивать.
- Галку asymmetric (асимметрично) оставляем пустой, отмечаем галки: subdirs (с подкаталогами), by content (по содержимому), ignore date (игнорировать даты).
- Кнопки в разделе «показывать» отмечаем все кроме «Одинаковые файлы» (зависит от того что именно вам нужно проделать с папками).
- Нажимаем сравнить.
Результат: если папки одинаковые по содержимому файлов, то список будет пуст. Если нет, укажет расхождения.
Исключить фильтр
Опция -x исключает текст (или символьные строки), указанные в результатах поиска, которые соответствуют правилам. Строка поиска (текст) должна использовать строчные буквы, включая регулярные выражения, и может указывать несколько опций -X. Следующий пример исключит строку «jffs2» при поиске:
Строка
В дополнение к вышеописанному сканированию на основе сигнатур binwalk может выполнять интеллектуальный анализ строк целевого файла, хотя он и не такой мощный, как полностью замененные строки Unix, binwalk отфильтровывает большинство «мусорных» строк, применяя некоторые очень простые правила проверки. И игнорировать некоторые неупорядоченные блоки данных
Функция преобразования
binwalk использует опцию -C для завершения нескольких преобразований без использования типов файлов, обычно лучше использовать опцию -l, чтобы ограничить это сканирование:
Тестовые jpeg файлы на которых вы можете протестировать способы сравнения
Результат сравнения этих файлов:
F1BF F0B786 F39BAF F3BD94
Битые байты перевёл в HEX.
Поделитесь учебником по искусственному искусству моего учителя! Нулевой фундамент, легко понять!http://blog.csdn.net/jiangjunshow
Вы также можете перепечатать эту статью. Делитесь знаниями, приносите пользу людям и осознайте великое омоложение нашей китайской нации!
Недавно в сети обнаружилась уязвимость производителя, связанная с бэкдором встроенного ПО, например, инструмент анализа, используемый, когда бэкдором маршрутизатора D-LINK Tengda является Binwalk, который был недавно обновлен до последней версии. В пятницу я нашел время, чтобы перевести использование инструмента и примеры.
Введение в Binwalk
Binwalk Является Firmware из анализ инструмент , Разработанный, чтобы помочь Исследователи Firmware Неаналитический Добыча и Обратный инжиниринг полезность 。 Прост в использовании, Полностью автоматизированный скрипт , и Через настройку подпись Извлечь правило И плагины модуль , Также важно то, что он может быть легко продлен 。
Самый простой способ использовать это просто, просто укажите путь к файлу прошивки и имя файла:

Если сопоставление основано только на сигнатурах, некоторые типы файлов не могут быть точно идентифицированы.
Таким образом, обнаружение подписанных файлов такого типа требует взаимодействия определенных подключаемых модулей (через подключаемые модули), если они не включены, это значительно увеличивает время сканирования и занимает много памяти.
Например, при сканировании сжатых пакетов zlib необходимо использовать плагин zlib:
Функция регистрации
Выходные данные журнала Binwalk, как правило, очень велики, поэтому они часто записываются для сохранения файла.
Опция -f позволяет вам указать файл журнала. Следует отметить, что если опция -Q не указана, результаты будут напечатаны в стандартный вывод и файлы журнала.
Файлы журнала могут быть сохранены в формате CSV


